Self-Supervised pre-training Models
최신동향
-
앞서 배웠던 Transformer Model은 NLP 뿐만 아니라, CV, 추천시스템 등 다양한 분야에서 좋은 성능을 내고 있다.
-
Transformer Model을 기반으로 대용량 Data를 학습한 Model이 여러 Task들을 해결하는 Model에 Backbone으로 사용되고 있다.
GPT1
-
가장 널리쓰이는 GPT 시리즈의 최초 Model
-
엘런 머스크가 만든 OPEN AI에서 제시한 Model
GPT1의 구조
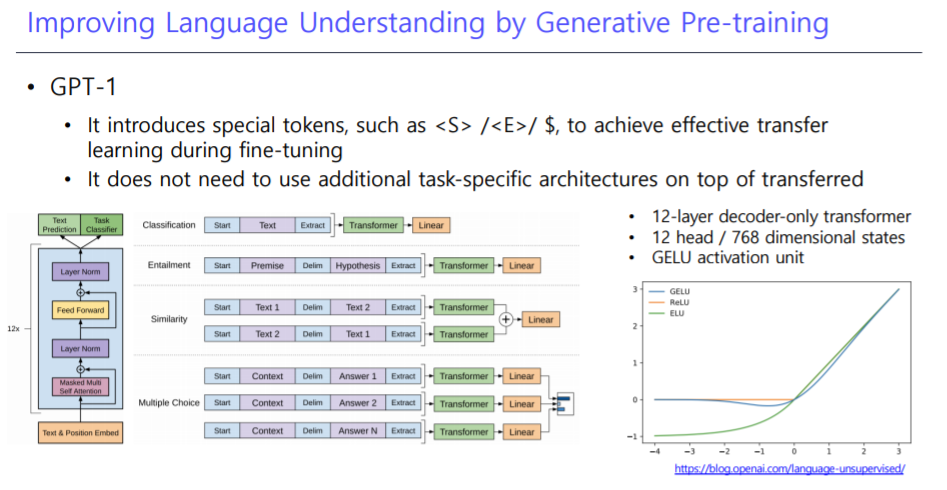
-
이전에 배웠던 Self-Attention Module을 여러개 쌓은 형태
-
여러 문장을 학습에 사용 할때, Delim token을 중간에 넣고 끝에는 Extract token을 넣음
-
전이학습에 사용할 때, 마지막 layer를 제거한 후, 원하는 Task를 수행하는 Layer를 추가한다.
-
이 때, 추가한 Layer에 러닝 레이트는 크게하고, 이미 학습된 기존의 Model의 러닝 레이트를 작게하여 학습을 진행한다.
GPT1 전이학습의 성능
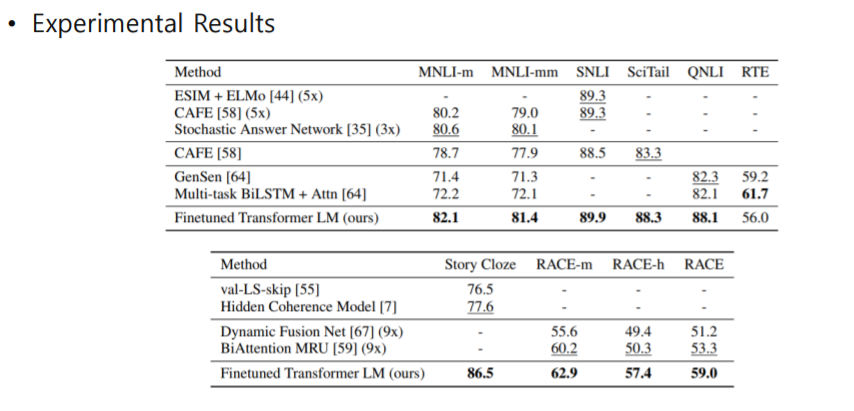
- GPT1을 전이학에 사용했을 때, 여러가지 Task에 대해 여러 방법과 비교했을 때, 좋은 성능 걷을 수 있는것을 확인 할 수 있다.
BERT
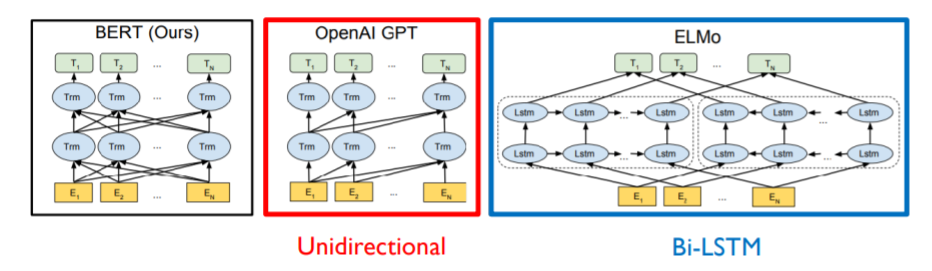
- 문장이나 단어를 만들 때, 이 후 단어뿐만 아니라 이전단어를 같이 보면 좀 더, 정확한 생성이 되지 않을까? 에 대한 의문에서 출발한 Model
Pre-training Tasks in BERT

-
Dataset의 15%는 Masking을 하여 사용한다.
-
15%의 80%는 아예 Masking, 10%는 무작위 단어로 대체,10%는 원래 Data로 넣어서 Training 한다.
-
사진의 아래 쪽 처럼 문장의 시작은 [CLS] token이 들어가고, 연결 할 때는 [SEP] token이 들어간다.
BERT:Input Represention

-
Transformer에서 사용되는 Position Embedding이 똑같이 진행된다.
-
조금 다른 점은 Segment Embedding으로 각각의 문장의 위치를 별개로 구분해준다는 것이다.
-
WordPice embedding은 Preposition이라는 단어가 있을 때, pre/posistion이라는 단어로 쪼개어 학습에 이용한다는 것이다.
BERT VS GPT-1

-
BERT가 조금 더 큰 Batch size를 가지고 있고 학습에 사용된 Data도 크다는 것을 알수있다.
-
두 모델은 다른 방식의 Token을 이용한다.
이전 P-stage에서 전이학습을 많이 공부한게 이번 강의를 이해하는데 도움이 됐다. 이번 선택과제도 열심히 공부해야겠다.
