인공지능과 자연어처리
- 본격적인 Pstage를 시작하기 앞서, 사람과 컴퓨터는 어떻게 문장을 인식할지 생각해보자
사람은 어떻게 자연어를 인식할까?

-
화자는 입을 통해, 자신의 생각을 언어로 표현하여 전달한다.
-
청자는 귀를 통해, 자신의 경험을 바탕으로 화자가 전달한 언어를 해석한다.
컴퓨터는 어떻게 자연어를 인식할까?
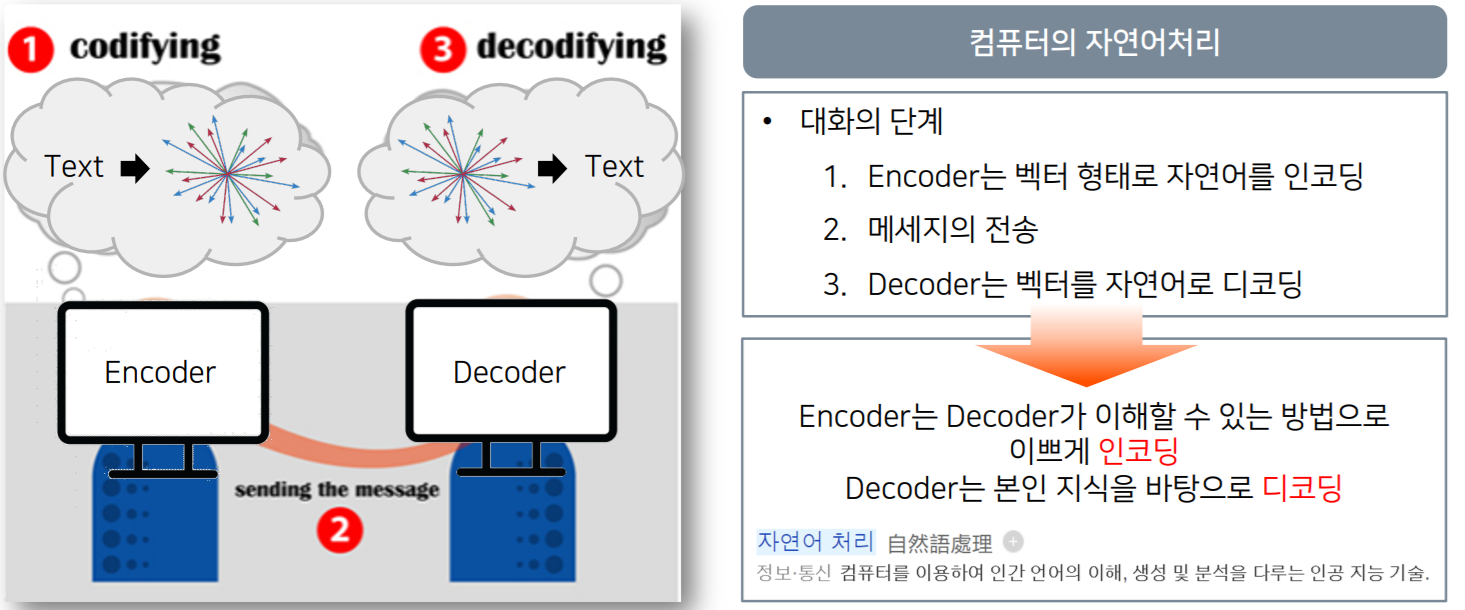
-
컴퓨터는 자연어를 Vector형태의 수학값으로 인식한다.
-
Vector로 표현한 자연어를 다른 컴퓨터가 인식할 수 있도록, 수학값으로 표현하는 것을 인코딩이라고한다.
-
메세지가 전송되면, Decoder는 전달 받은 Vector를 학습된 파라미터로 해석하여 인식한다.
인코딩은 발화의 과정 디코딩은 수신의 과정으로 이해하면 쉽다.
자연어 단어 임베딩
- 컴퓨터가 어떻게 자연어 단어를 Vector로 표현하는지 알아보자.
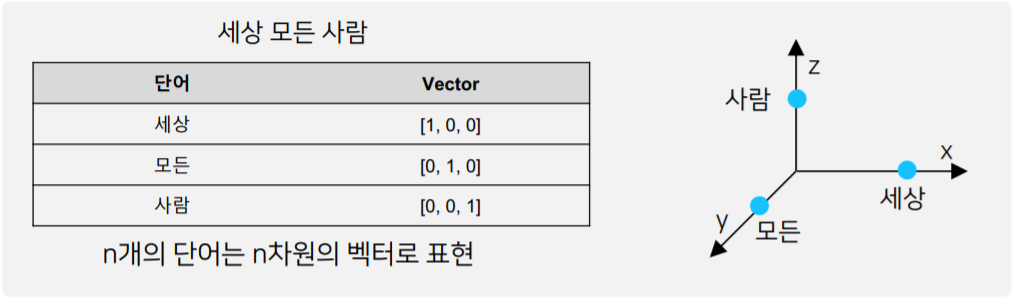
- 여러가지 단어를 각각의 차원에 맞는 Vector로 표현한다.
Word2Vec
- 위에서 임베딩한 것을 어떻게 활용 할까?

-
우리는 아랍어를 모르지만 뒤에 한국어 문장을 보고 아랍어를 유추할 수 있다.
주변의 단어들은 알고 싶은 단어와 상관관계가 있기 때문에, 주변 단어는 알고 싶은 단어를 추론할 때 도움이 된다. 이와같은 개념을 바탕으로 만들어진게 Word2Vec 이다.
Word2Vec 예시
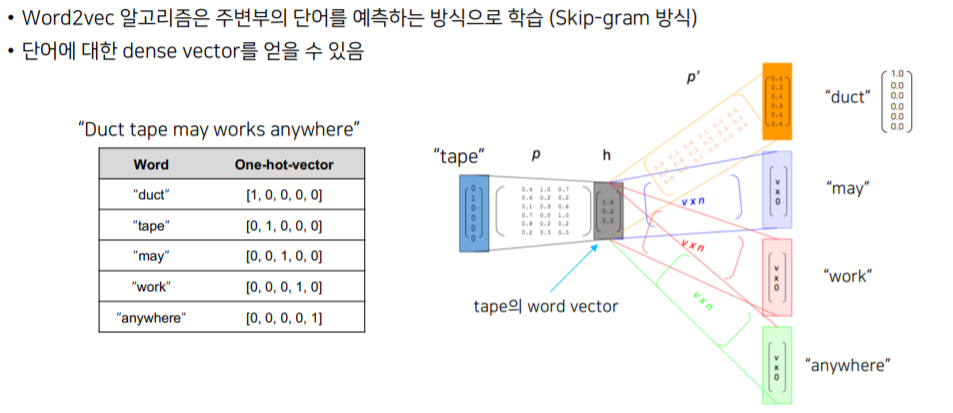
tape라는 단어와 비슷 한단어를 찾기위해 파라미터 p와 dot 연산을 거쳐 h vector를 만든다. 이 h vector와 p` 파라미터를 다시 dot 연산을 거쳐 가장 유사한 단어를 찾아낸다.
Word2Vec의 장단점
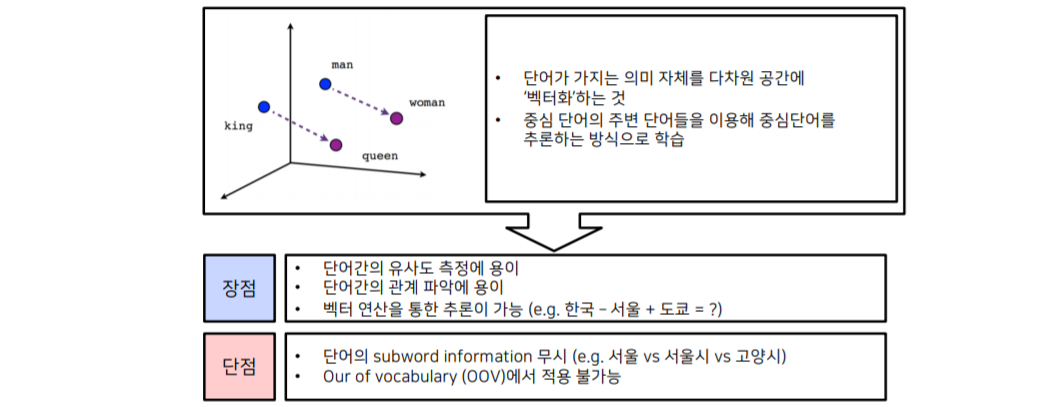
Word2Vec의 단점에 대해 생각해보자. 사전의 크기가 아무리커도 세상 모든 단어나 문장을 저장해 할 수 없다. 이 문제를 OOV 라고 한다. 이것을 어떻게 해결 할 수 있을까?
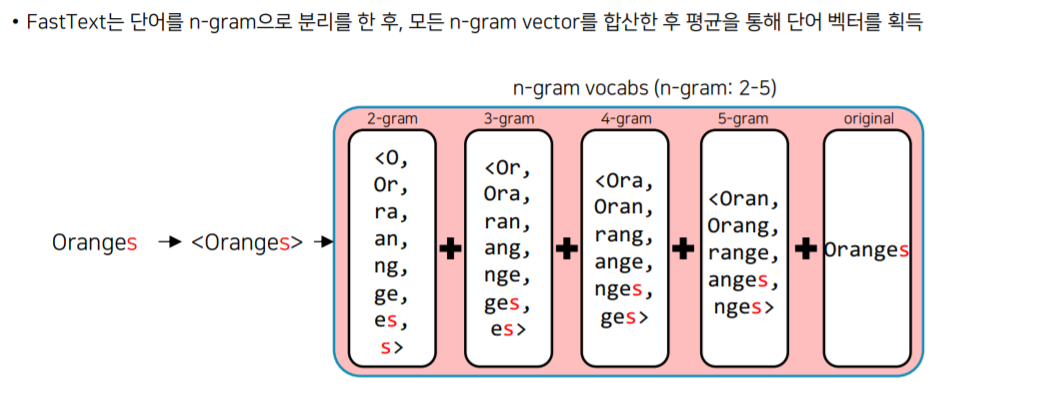
FastText
-
FastText는 OOV를 해결할 수 있는 방법이다.
Orange라는 단어를 생각해보자. Oranges라는 단어가 들어오면 oov가 발생하게 된다. 이를 해결하기위해 FastText는 N-gram 단위로 단어를 분리하여 얻은 Vector를 평균을 내어 단어 벡터를 얻는다.
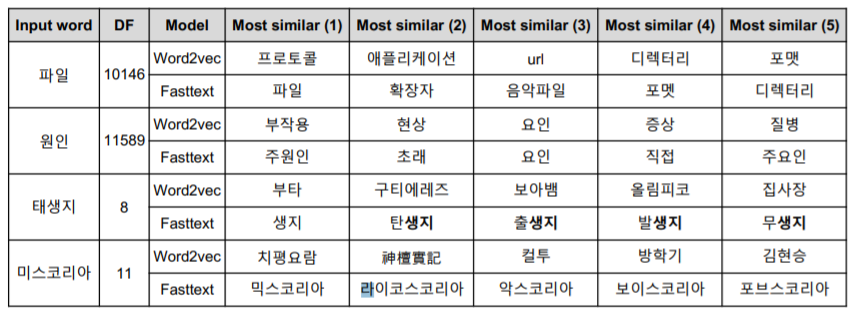
FastText의 예시
-
위의 예시를 보면 Word2Vec과 비교했을 때, OOV 문제를 꽤 잘해결하는 것을 알 수 있다.
이번주 부터 다시 Pstage 시작이다. 각 강의를 듣고 바로 학습정리하고 내가 공부했던것들을 바로바로 정리하는 습관을 들이면서 성장하는 시간이 될 수 있도록 노력해야겠다.
