Huggingface
-
Huggingface는 Transformers 라이브러리를 구축하고 유지하고 있는 회사이다.
-
이 라이브러리를 통해 오늘날 사용 가능한 대부분의 크고 최첨단 Transformer Model을 사용할 수 있다. ex) BERT, RoBERTa, GPT, GPT-2, XLNet 등
Huggingface 사용법

- Huggingface를 가져오는 방법은 위 사진 처럼 쉽게 3줄의 코드를 입력하면 된다.
Tokenizer

- Transformer 기반의 대표 모델인 Multi-lingual bert model을 사용해보자.
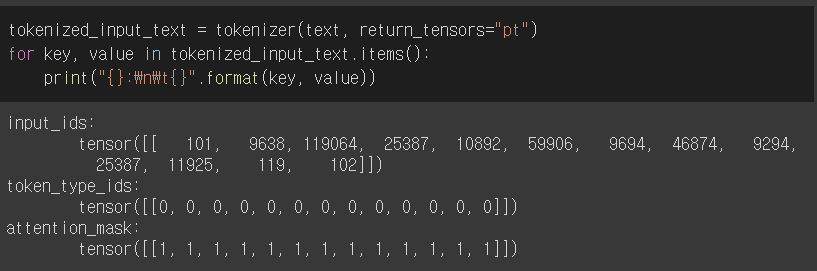
-
tokenizer를 통해 쉽게 text를 Token으로 자를 수 있다.
-
retun_tensor="pt"는 파이토치 기반의 Vector를 말한다.
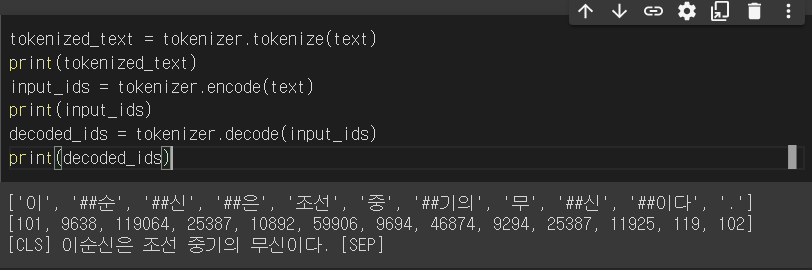
-
첫번째 결과는 '이순신은 조선 중기의 무신이다'라는 문장을 Token으로 자른 결과이다.
-
두번째 결과는 Token으로 잘랐을 때, Token들의 id 이다.
-
101,102 Token id는 각각 [CLS],[SEP] 토큰을 의미한다.
-
이처럼 자동적으로 시작과 끝에 Bert Model에 맞는 Token을 붙혀준다.
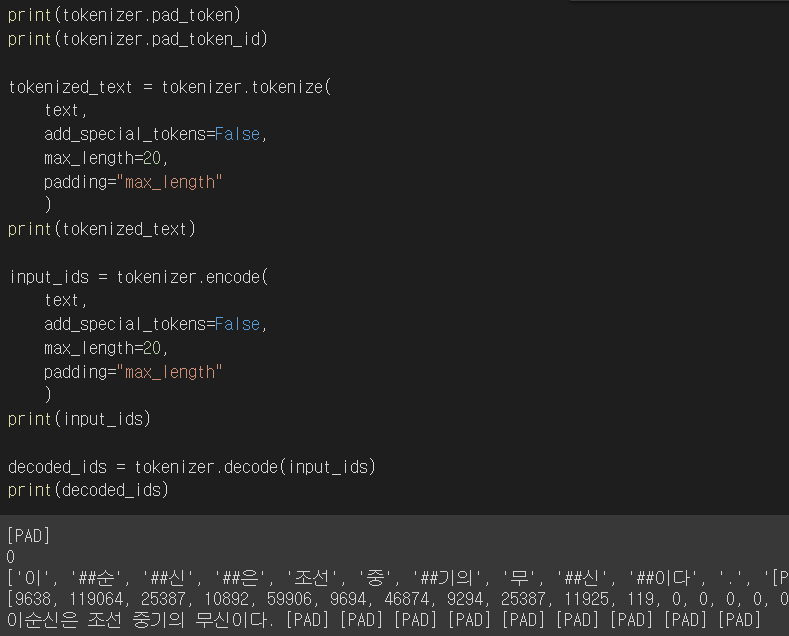
Tokenizer Option
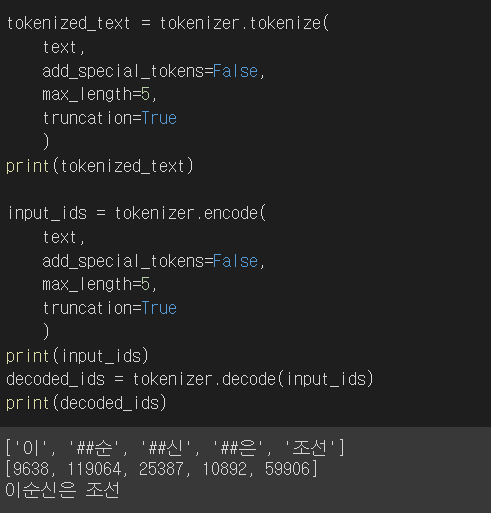
- tokenizer.encode에 입력 Text와 max_lenght값을 지정해주면 지정한 max_length 만큼만 Token을 생성한다.
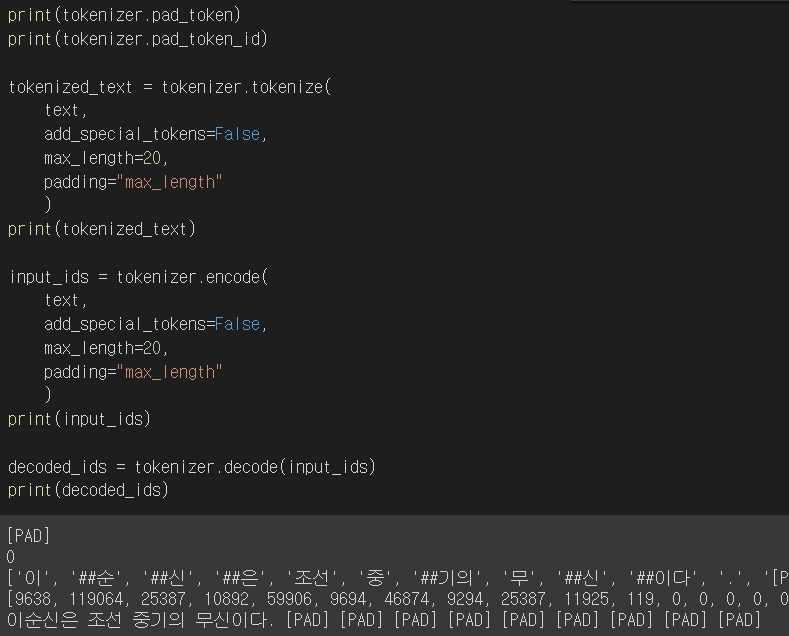
- padding을 설정해주면, 설정한 길이만큼의 [PAD] Token이 추가되어 문장에 적용된다.
Tokenizer Vocab 추가

-
Huggingface에 저장된 한국어 단어는 약 12만개로 저장되어있지 않은 단어의 경우 [UNK]로 Token이 생성된다.
-
[UNK] token이 많아지면 Model 성능에 악영향을 미칠 수 있다.

- tokenizer.add_tokens를 통해 원하는 단어를 간단하게 Vacob에 추가 할 수 있다.
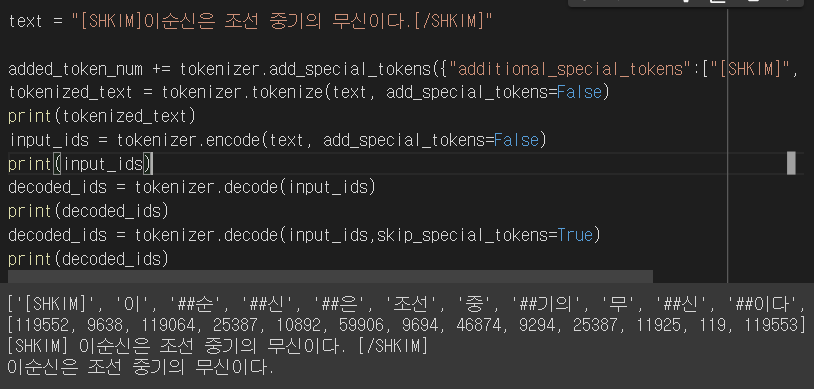
- 단어 뿐만 아니라 tokenizer.add_special_tokens을 통해 임의의 Token 또한 추가 가능하다.

- 단어를 추가했다면 반드시 model의 embedding layer 사이즈를 늘려야 한다.
BERT Model Test
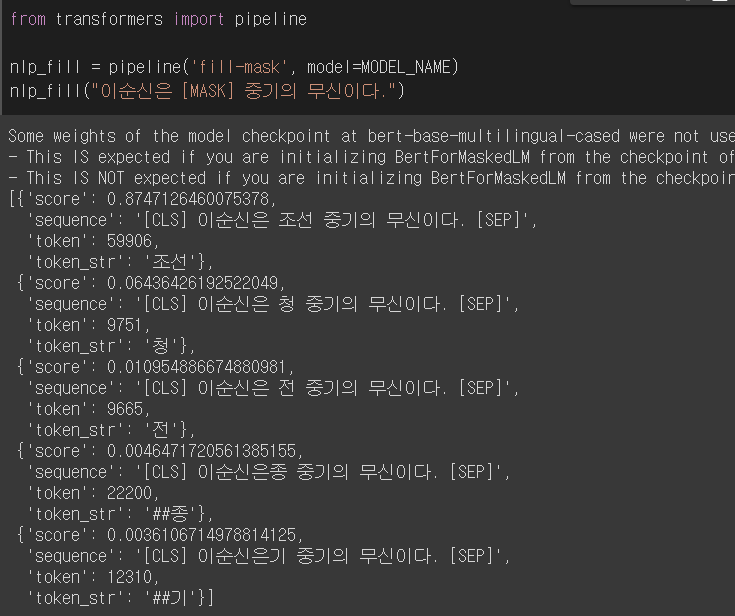
- 문장에 일부를 [MASK] token으로 대체하여 이 부분을 BERT Model로 예측한 결과이다.
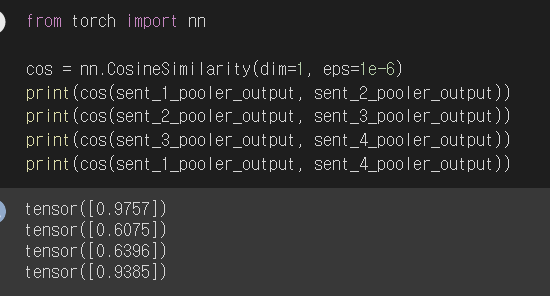
-
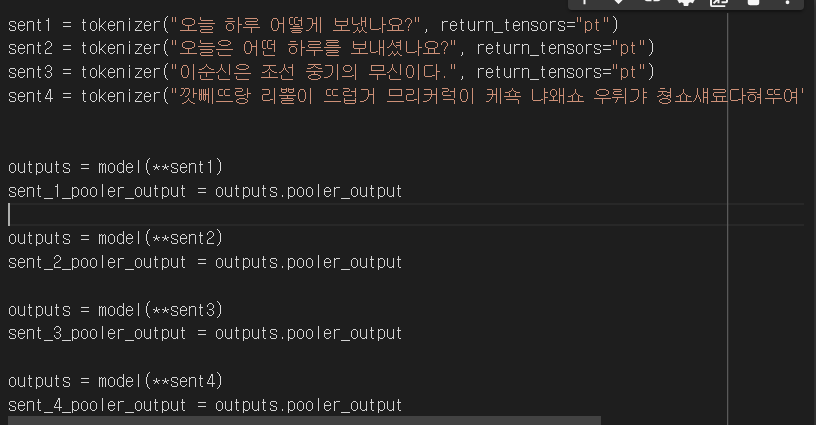
예시로 제시된 4개의 문장의 유사도를 구한것이다.
-
눈 여겨 볼것은 첫번째 문장과, 네번째 문장의 유사도이다.
-
두 문장은 전혀 유사하지 않지만 꽤 높은 유사도를 보이고 있다.
-
이를 통해 알 수 있는것은 유사도로 구한 값의 쓰레쉬 홀드를 맹신 할 수 없다는 것이다.

개발이 하고싶습니다.