- 기본적으로 함수의 출력(
loss=myfunction()) 최소화하는 파라미터(params)를 찾습니다.
- 도함수의 형태를 미리 알고 있지 않고, 한 스텝 이동한 후 함수의 출력값을 구하여 loss의 기울기를 구합니다.
- 아주 간단한 구현입니다. 좋은 최적화 성능을 기대할 수 없습니다.
직접 구현하게된 이유?
- loss를 구하는 과정, 즉 목적함수 부분이 지나치게 복잡해서 일반적으로 사용하는 torch, tensorflow, autograd 등을 사용할 수 없었다.
import numpy as np
import time
class GDOptimizer():
history = []
best_params = None
best_loss = None
def __init__(self, num_epochs=1000, step=0.05, learning_rate=0.1, term_threshold=0.000001, report_interval=10):
self.num_epochs = num_epochs
self.step = step
self.learning_rate = learning_rate
self.term_threshold = term_threshold
self.report_interval = report_interval
def optimize(self, my_function, params:np.array):
t0 = time.time()
history = []
temp_params = None
best_loss, best_params = np.inf, None
for i in range(self.num_epochs):
loss = my_function(params)
if (len(history) > 0) and (i % self.report_interval == 0):
print(f'{i}\t loss : {loss:.3f}, change : {abs(history[-1] - loss):.6f}, params : {params}')
if (not best_loss) or (loss < best_loss):
best_idx = i
best_loss = loss
best_params = params.copy()
if len(history) > 0 and abs(history[-1] - loss) < self.term_threshold:
history.append(loss)
break
elif self.num_epochs -1 == i:
break
else:
history.append(loss)
temp_params = params.copy()
for j in range(len(params)):
temp_params[j] += self.step
stepped = my_function(temp_params)
delta = stepped - loss
params[j] -= self.learning_rate * delta
loss = stepped
print(f'{i}\t loss : {loss:.3f}, change : {abs(history[-1] - loss):.6f}, params : {params}')
print(f'terminated, best idx= {best_idx}')
result = {
'best_loss' : best_loss,
'best_params' : best_params,
'history' : history,
'time' : time.time() - t0
}
self.result = result
return result
예시
def my_function(params):
# example function
return (params[0]-3) ** 2
print('test optimizer')
print('------')
gdo = GDOptimizer(report_interval=100, term_threshold=1e-6)
result = gdo.optimize(my_function, np.ones(1))
print('------')
print('')
print(f"best loss : {result['best_loss']}")
print(f"best parmas : {result['best_params']}")
Results
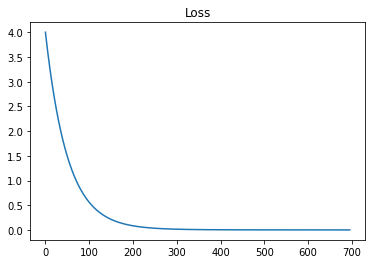
test optimizer
------
100 loss : 0.559, change : 0.010976, params : [2.25208613]
200 loss : 0.084, change : 0.001555, params : [2.71039014]
300 loss : 0.015, change : 0.000239, params : [2.87814423]
400 loss : 0.004, change : 0.000043, params : [2.93954766]
500 loss : 0.001, change : 0.000010, params : [2.9620233]
600 loss : 0.001, change : 0.000003, params : [2.97025011]
695 loss : 0.001, change : 0.000000, params : [2.97317178]
terminated, best idx= 695
------
best loss : 0.0007197531375624824
best parmas : [2.97317178]
