Intro
selenium 으로 인스타그램을 크롤링 작업을 하다보면
- 팔로워 or 팔로잉 크롤링
- 해시태그 크롤링
- username 크롤링
3가지를 크롤링 하는 상황이 있다.
이번 게시글에서는 간단하게 팔로워 or 팔로잉 목록을 scroll down 방법으로 크롤링 하는 방법을 알아보려고 한다.
팔로워 or 팔로잉 추출하기
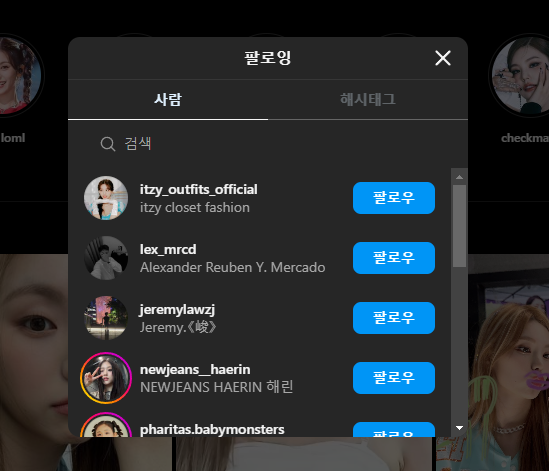
위 사진의 following 또는 followers 목록을 크롤링 하기 위해서 고려해볼 방법은
- scroll down
- GraphQL
직접 scroll down 하는 방법과 GraphQL 로 followers 또는 following 목록 데이터를 요청하는 방법 두가지가 있다.
나는 이번 게시글에서 selenium 을 통해 HTML 요소를 자동으로 끝까지 scroll down 하여 현재 팔로워 목록 또는 팔로잉 목록을 가져오는 방법을 구현해보려 한다.
Selenium webdriver 이동
먼저 selenium 을 내가 크롤링할 상대 인스타 아이디의 followers 또는 following 목록을 보기 위해
webdriver를 크롤링할 상대방 username 과 following 또는 followers 선택하고 해당 url로 이동한다.
#잇지 예지 인스타 팔로잉 목록으로 이동
driver.get("https://www.instagram.com/yeji.ltzy/following/")
driver.implicitly_wait(1)여기서 webdriver 메소드인 implicitly_wait 는 HTML 의 모든 요소가 나올 때까지 최대로 wait 할 시간(초) 를 의미한다.
Selenium scroll down
Scroll down DOM
내가 원하는 로직을 구현하기전에 먼저 어떻게 스크롤 다운 해야하는지 알아보자.
selenium 에서는 아래 코드와 같이 DOM 제어를 통해서 내가 원하는 요소에서 원하는 만큼 scroll down 할 수 있다.
driver.execute_script("document.querySelector('.abcd').scrollTo(0, 100)")즉, 해당 코드에서는 driver가 .abcd 요소를 0 부터 100 까지의 높이 까지 스크롤 다운 하는 DOM 제어문을 실행하도록 한다.
Check element and Start Scroll down
먼저 스크롤 다운할 요소의 class 명을 개발자 모드를 통해 확인해보자.
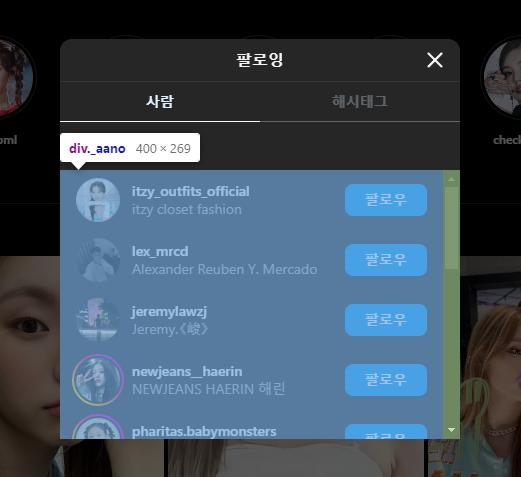
팔로워 또는 팔로잉 목록을 보여주는 요소의 class 명이 ._aano 라는 걸 확인했다.
이제 생각해야할 것은 지금 보여지는 list를 0 부터 100 까지 스크롤 하게 된다면,
새로운 데이터를 받아와도 이미 100까지 스크롤 되어있기 때문에 더이상 스크롤 하지 않는다.
따라서 내가 원하는 모든 팔로잉 또는 팔로워 목록을 가져오기 위해서는
모든 데이터를 가져올 때까지 계속해서 스크롤 다운해야한다.
scroll_method = "document.querySelector('._aano').scrollTo(0, document.querySelector('._aano').scrollHeight)"
driver.execute_script(scroll_method)스크립트의 ".scrollHeight" 메소드를 추가로 사용해 계속해서 해당 요소의 높이를 가져오고
해당 높이만큼 scroll down 하게 구현했다.
scroll down의 종료 메소드 정의
우리가 scroll down 을 사용할 때
해당 username 의 모든 데이터를 불러왔는데도 계속해서 scroll down하게 된다면
영원히 멈추지 않으므로 종료 메소드를 정의 해야한다.
즉, 스크롤 전 보여지는 height(before) 와 스크롤 후 height(now) 가 같게 된다면
loop 문을 종료해야 한다.
나는 스크롤 후 현재 요소의 height 를 반환받아 스크롤 전 height 와 비교해서 종료 메소드를 구현했다.
import time
while before_height != now_height:
before_height = now_height
now_height = driver.execute_script("return document.querySelector('._aano').scrollTop;")
driver.execute_script("document.querySelector('._aano').scrollTo(0, document.querySelector('._aano').scrollHeight)")
time.sleep(1)
print('following crawling end')while 루프문에서 before_height 와 now_height 를 비교하고
일치하지 않는다면 계속해서 스크롤 다운하고, 일치한다면 종료하도록 구현하였다.
scroll down이 종료되면, beautifulsoup4 를 통해 해당 요소의 text 를 추출해
가져온 팔로워 또는 팔로잉 목록을 crawling 할 수 있다.
Source code
driver.get("https://www.instagram.com/lilyiu_/following/")
time.sleep(3)
#초기 변수 세팅
before_height = -1
now_height = -2
try:
#스크롤 전/후 의 높이가 같을 때까지 스크롤 진행
while before_height != now_height:
before_height = now_height
now_height = driver.execute_script("return document.querySelector('._aano').scrollTop;")
driver.execute_script("document.querySelector('._aano').scrollTo(0, document.querySelector('._aano').scrollHeight)")
time.sleep(1)
print('following crawling end')
except:
print('error scroll')Issue
scroll down을 통해 팔로워 또는 팔로잉 목록을 crawling 시
너무 많은 데이터 요청으로 지연시간이 계속해서 발생하게 된다면
모든 데이터를 가져오지 못했는데, loop문이 종료되는 문제가 생기게 된다.
그래서, scroll down을 통해 데이터를 가져온다면 time out 를 따로 정의해
지연시간을 어느정도까지 허용할 것인가도 생각해야한다.
나는 이러한 문제 때문에 내가 만든 인스타그램 crawling 프로젝트에서는
scroll down이 아닌 GraphQL의 쿼리문 요청으로 팔로워 또는 팔로잉 데이터를 요청해
받은 JSON 데이터를 crawling 하는 방법을 사용하고 있다.
틀린부분이 있다면 수정 바로바로 진행하겠습니다!
