
이번 게시글에서는 느린 RDMBS 에서 어떠한 데이터를 가져와야 할 때
데이터 베이스에서 필요한 데이터를 조금 더 효율적이고 빠르게 가져오는 방법의 하나인 "DB Index" 에 대해 알아보고, 실제로 장고에서 SQLite3 에 index 를 생성해 보자!
INDEX 를 사용한다고 무조건 좋은 것은 아니니 언제 어떨 때 사용하면 좋을지 생각하면서 사용해야 한다.
DB Indexing
What is DB Index ??
DB Index 란, DataBase 테이블 내의 특정한 필드(column)에 대해 search speed 를 향상하는 자료구조 들을 말한다.
예를 들어, 우리가 어떤 단어를 찾기 위해 사전을 찾아볼 때 사전은 '알파벳' 또는 '가나다' 순으로 정렬되어 있어 사전에서 우리가 찾는 단어의 뜻이 적혀있는 위치를 빠르게 찾을 수 있게 된다.
이때, 정렬이 되어있는 '알파벳' 또는 '가나다' 순을 DB Index 라면 이해가 쉽다!
실제 DB Index 는 아래 그림과 같이, KEY-VALUE 구조로 index 키 값은 DB TABLE에서 해당 레코드가 저장된 위치를 나타낸다.
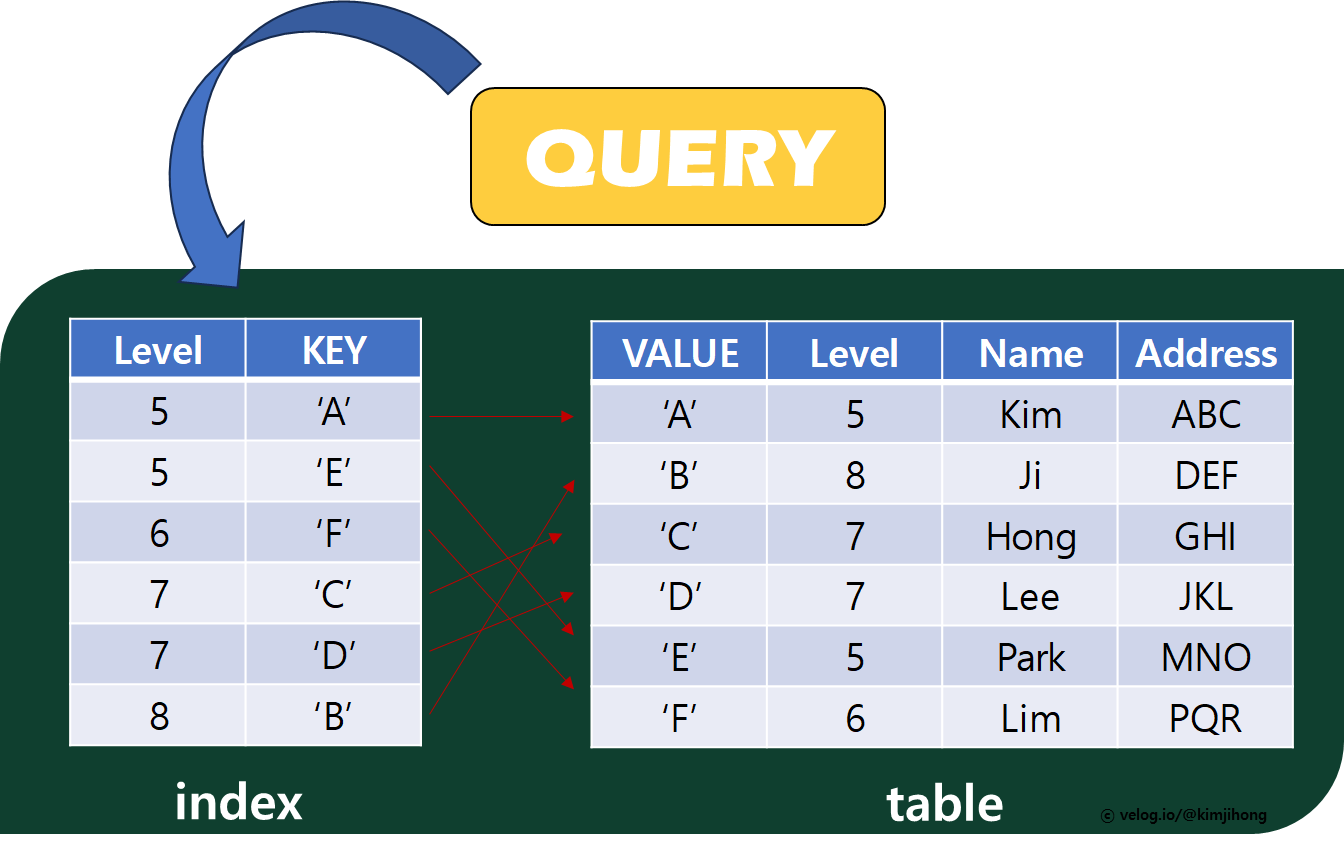
Trade-Off for using DB Index
DB Index 를 사용하기 전, DB Index 를 사용하게 되므로 얻게 되는 장점과 단점에 대해서 알아보고 상황에 알맞게 사용해야한다!
장점
WHERE절에서 Index 는 데이터가 정렬되어 있어 매우 빠르게 해당 데이터를 찾을 수 있다. (FULL-SCAN 방식이 아닌 INDEX-SCAN 방식으로 빠르게 데이터를 찾는다.)MIN,MAX값을 가져올 때, 효율적으로 데이터를 가져올 수 있다.- DB에 부하가 많이 걸리는
ORDER BY절을 매우 효율적으로 처리 가능하다. (이미 정렬이 되어 있기 때문에ORDER BY를 할 이유가 없다.)
단점
- Index 는 DML 작업 즉,
DELETE,UPDATE,INSERT시에 Index 에도 해당 사항을 반영해야 하므로, DML 에서는 오히려 좋지 않다.- Index 는 전체 DB Table 의
10% ~ 15%이하의 데이터를 처리할 때 유리하며, 그 이상의 데이터를 처리할 때는 효율적이지 못하다.- Index 를 관리하기 위해서 대략
10%의 공간이 추가로 필요로 한다.
위와 같이 사용함으로써 얻게 되는 매우 큰 장점도 있지만
Index 를 남용하게 된다면 성능적으로 향상하기 위해 사용하는 Index 가 오히려 더 좋지 못한 결과를 야기할 수 있다.
따라서 Index 의 Trade-Off 를 잘 생각하여 사용하는 목적에 맞게 잘 선택하고 Index 를 많이 사용하는 것보다는 SQL Query 문을 좀 더 효율적으로 사용하는 편이 좋다.
So? when should we use DB Indexing?
그럼 우리는 언제 DB Index 를 사용해야 할까?
우리가 Index 를 효율적으로 사용하기 위해서는 DATA 의 밀집도가 높고 조건절에 의한 호출 빈도가 높은 Column 을 Index 로 생성하고, MAN or WOMAN 과 같이 중복되는 값들이 매우 많은 값들은 Index 를 사용하지 않아 최적의 효율을 뽑는 것이 좋다.
MAN or WOMAN 과 같이 중복되는 '값' 들이 많은 DATA 는 Index 로 정렬을 해도 데이터 검색 시 의미가 없어지기 때문에, 사용하지 않아야 한다!
정리하면,
Index 의 고려 조건
- Cardinality (카디널리티) - 고유 값의 수
- Low Cardinality : 중복된 값이 많고, 고유 값이 적은 case
- ex) Gender
- High Cardinality : 중복된 값이 적고, 고유 값이 많은 case
- ex) Email
- Selectivity (선택도) - 쿼리문에 의해 사용되는 빈도
- Low Selectivity : 쿼리문에 맞는 레코드가 많은 case
- ex) 직업이 '학생'인 레코드
- High Selectivity : 쿼리문에 맞는 레코드가 적은 case
- ex) 직업이 '기타'인 레코드
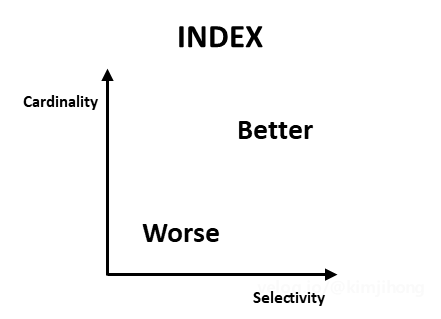
즉, Low Cardinality 와 Low Selectivity 에서는 index가 비효율적일 수 있다.
DB Index Data Structures
DB Index 에서 대표적으로 사용되는 3가지 자료구조
- Bitmap
- B-tree
- Hash
3가지의 자료구조에 대해서 매우 간단하게 알아보자.
Structure.1 Bitmap
BITMAP Index 는 주로 데이터가 변경되지 않거나, 데이터의 종류가 많지 않는 곳에 사용된다.
Index 를 저장할 때 '1' 과 '0' 즉, BIT 단위로 저장하여 각 비트들은 특정한 레코드 값을 가진다.
만약 Group 정보에 대한 칼럼에 대해서 BITMAP Index 를 저장한다고 해보자.
A_Group : 0 0 0 1
B_Group : 0 0 1 0
C_Group : 0 0 1 1
D_Group : 0 1 0 0
이런 식으로 BIT 들로 이뤄진 MAP 을 만들어서 각 비트들은 고유의 레코드 값 A_Group ~ D_Group 를 가지게 된다.
Structure.2 B-tree
B-TREE Index 는 BITMAP 와 달리, 주로 데이터의 종류가 적은 곳에 사용한다.
Index 를 저장할 때 트리구조로 저장되며, 데이터를 정렬된 순서로 저장하고 각 노드는 KEY 값과 그 KEY 에 해당하는 VALUE 의 위치를 저장한다.
위의 사진이 그 예시이다.
Structure.3 Hash
HASH Index 는 동등 조건 비교 절 즉, =, IN, IS NULL, IS NOT NULL 과 같이 일치 불일치 를 검색하게 될 때 매우 빠르게 찾을 수 있게 도와준다.
Index 를 저장할 때 특정 값을 해시 함수로 매핑해서 '버킷(Bukkit)' 이라고 불리는 공간에 KEY 값으로 저장되고 그 KEY 값을 통해서 해당 레코드의 위치를 찾는다.
일반적으로 메모리 기반 테이블 에 구현된다.
예를 들어, 사용자가 주문한 날짜를 HASH Index 로 저장한다고 해보자.
- 주문한 날짜가 '23/09/23' 인 데이터를 가져오기에는 알맞은 index !
- '23/09/23' ~ '23/09/25' 와 날짜의 범위를 가져오는 것은 알맞지 않은 index !
즉, 동등 비교 조건 에는 좋은 선택이지만, 범위 비교 조건 에서는 좋지 않은 선택이다.
Make Index in Django
Make B-TREE index
장고에서 기본적으로 지원하는 INDEX 기술인 B-TREE 를 생성해 보자.
장고에서 B-TREE Index 를 생성하는 것은 매우 간단하다!
# testapp/models.py
# index 를 생성한 model
class B_TREE_Model(models.Model):
fields1 = models.CharField(max_length=10)
fields2 = models.CharField(max_length=10)
fields3 = models.CharField(max_length=10)
fields4 = models.CharField(max_length=10)
class Meta:
# 단수형 index name
verbose_name = "indexname"
# 복수형 index name
verbose_name_plural = verbose_name
# index 생성 (Meta class 내부 정의 사용)
indexes = [
# 단일 index
models.Index(fields=['fields3'], name="single_index"),
# 복합 index
models.Index(fields=['fields2', 'fields4'], name="unique_index"),
]Meta 클래스의 indexes 를 사용하여 내가 원하는 칼럼을 인덱스로써 생성이 가능하다!
verbose_name 와 verbose_name_plural 는 해당 모델 안에서 사용되는 전체 index 집합의 이름을 정의해 준다!
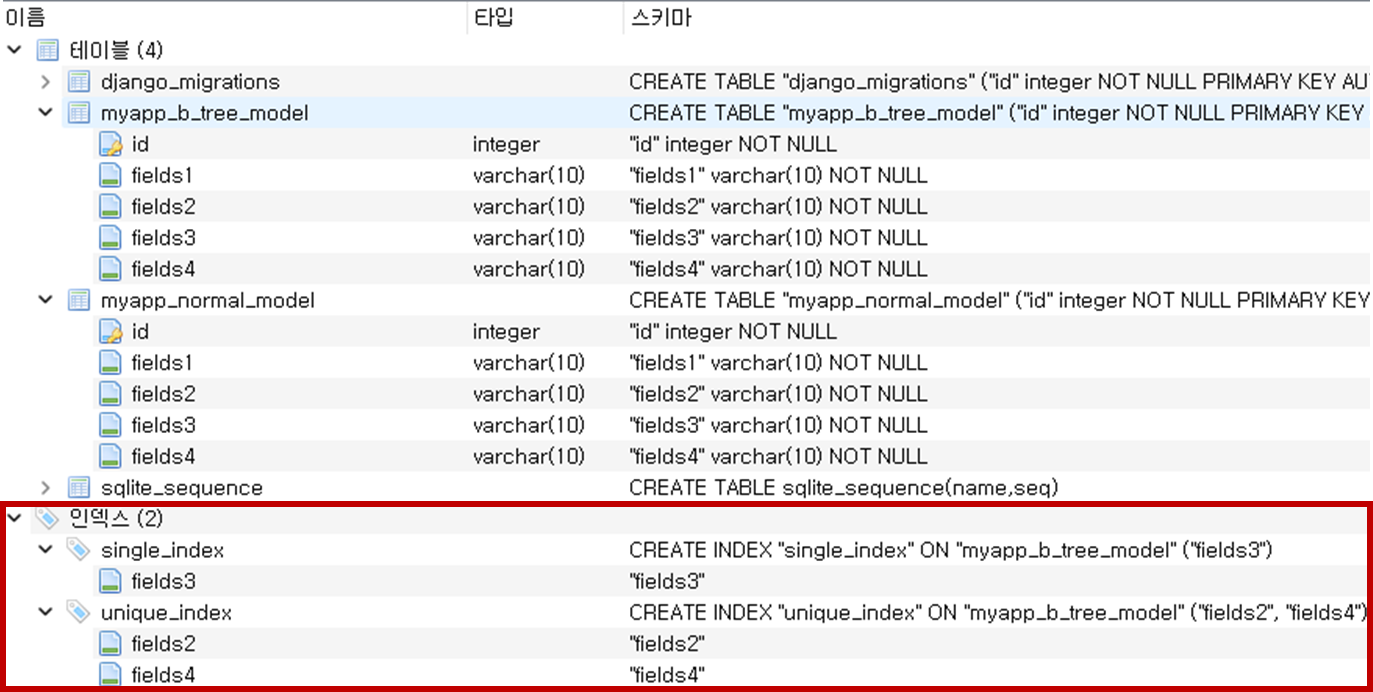
위 사진과 같이 B-TREE Index 2가지 single_index 와 unique_index 에 각각 fields3 과 fields2, fields4 가 생성되었다.
how to Use Hash & Bitmap index in Django?
장고에서는 HASH INDEX 와 BITMAP INDEX 는 어떻게 생성해야할까??
위 두 가지 index 를 생성하기 위해서는 Query 문을 통해서 DB 에 직접 생성 명령을 주거나, 라이브러리를 사용하면 된다.
장고 마이그레이션을 통해서 HASH INDEX 를 생성해 보자!
# myapp/migrations/000x_auto.py
from django.db import migrations
class Migration(migrations.Migration):
# ('앱 이름', '000x_previous_migration')
dependencies = [
('myapp', '0001_initial'),
]
operations = [
migrations.RunSQL('CREATE INDEX {인덱스명} ON {테이블명}({필드명}) USING HASH;')
]dependencies 부분에서 '000x_previous_migration' 은 모델 생성 또는 변경 시 사용된 마이그레이션 파일을 참조한다는 것을 의미한다.
위 코드에서는 0001_initial.py 를 참조한다!
그럼 이제 어떻게 BITMAP INDEX 를 생성할 수 있을까?
방법은 매우 간단하다!
# 쿼리문만 바꿔주자!
operations = [
migrations.RunSQL('CREATE INDEX {인덱스명} ON {테이블명}({필드명}) USING BTREE;')
]쿼리문만 바꿔주면 되는 것이다!!
※ 주의할 점은, 장고의 기본 DB 인 SQLite3 에서는 HASH INDEX 와 BITMAP INDEX 를 기본적으로 지원하지 않아 별도의 라이브러리 또는 기능 확장이 필요하다.
따라서 MySQL 또는 PostgreSQL 과 같은 DB를 사용하는 것이 좋다!
우리가 지금까지 쿼리문 없이 데이터를 가져올 수 있었던 이유는 장고의 ORM 을 사용했기 때문이다.
다음에는 장고 ORM 과 Query 문 의 차이와 간단한 Query 문을 사용해 보자!
ORM 과 Query 의 차이 비교 블로그
틀린 부분이 있다면 지적 정말 감사합니다. 바로바로 수정하겠습니다.
