CNN (Convolutional Neural Networks)
LeNet
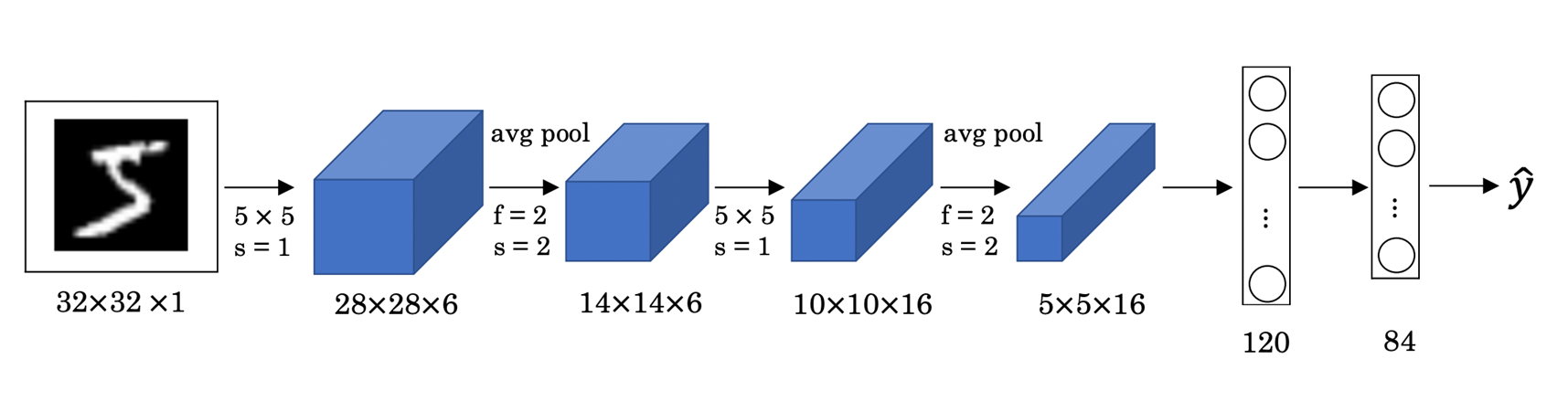
- 32X32X1 : 흑백의 32X32 사이즈 이미지
- filter size = 5 X 5, stride = 1인 커널로 Convolution
--> parameter 수 : (1 x 5 x 5 + 1) * 6
- filter size = 5 X 5, stride = 1인 커널로 Convolution
- fileter size = 2 x 2, stride = 2인 average pooling
--> parameter 수 : 0
- fileter size = 2 x 2, stride = 2인 average pooling
- filter size = 5 X 5, stride = 1인 커널로 Convolution
--> parameter 수 : (6 x 5 x 5 + 1) * 16
- filter size = 5 X 5, stride = 1인 커널로 Convolution
- fileter size = 2 x 2, stride = 2인 average pooling
--> parameter 수 : 0
- fileter size = 2 x 2, stride = 2인 average pooling
- (5 x 5 x 16)으로 flatten
- 노드 420개, 84개인 FCL
--> parameter 수 : (420 + 1) x 84
- 노드 420개, 84개인 FCL
- 노드 84개, 10개인 FCL
--> parameter 수 : (84 + 1) x 10
- 노드 84개, 10개인 FCL
Alexnet
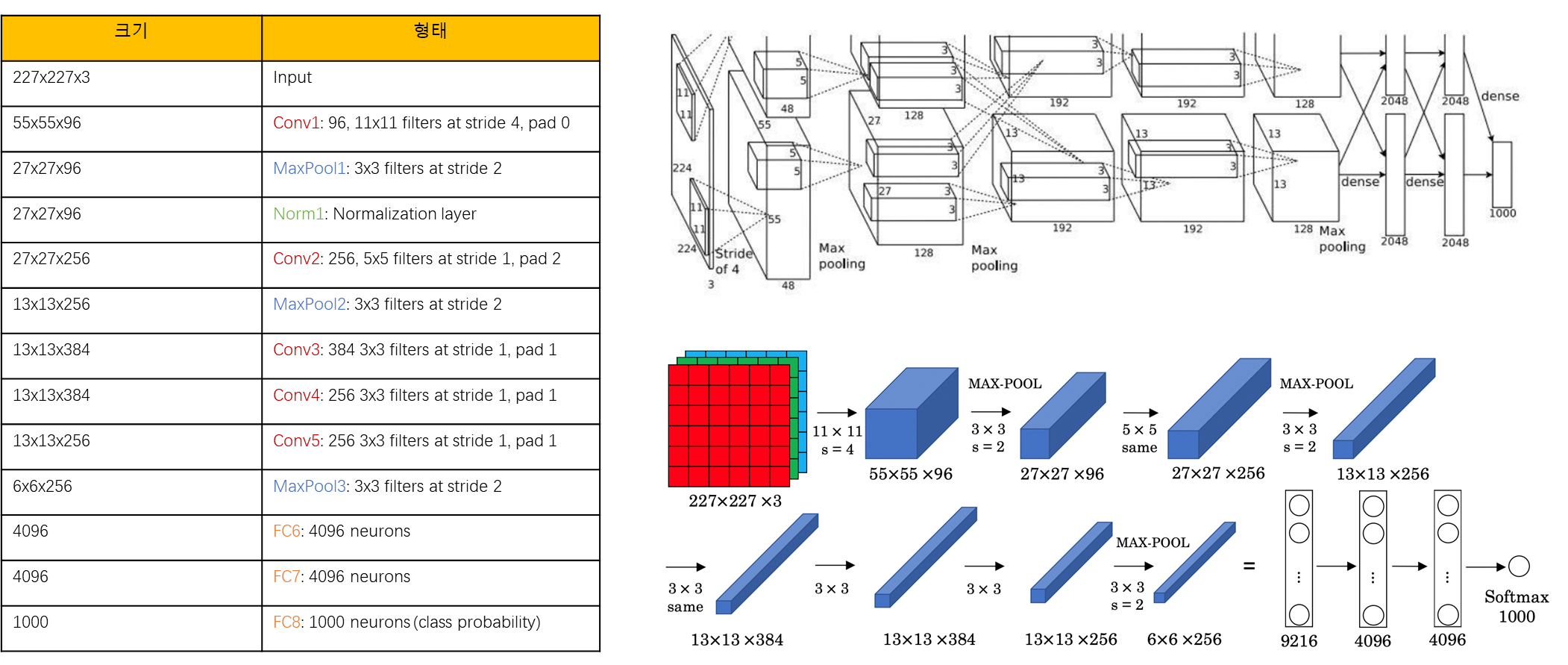
- Norm : Normalize
- Network가 깊어질수록 각 채널에서 특정 값이 커져 학습에 과도한 영향을 끼치는 것을 방지
--> 모든 채널에서 각각의 특징을 고루고루 학습 시킬 수 있도록 크기를 Normalize - 특징들을 풍부하게 학습할 수 있도록, layer 중간에 채널의 크기 크게 키움
VGG
- 3개의 3 x 3 필터를 사용하여 7 x 7 필터를 사용한 것과 같은 효과를 냄
- 더 깊은 구조로 더 많은 non-linearity를 얻을 수 있음
- 7 x 7 filter보다 3 x 3 filter가 더 적은 parameter를 사용
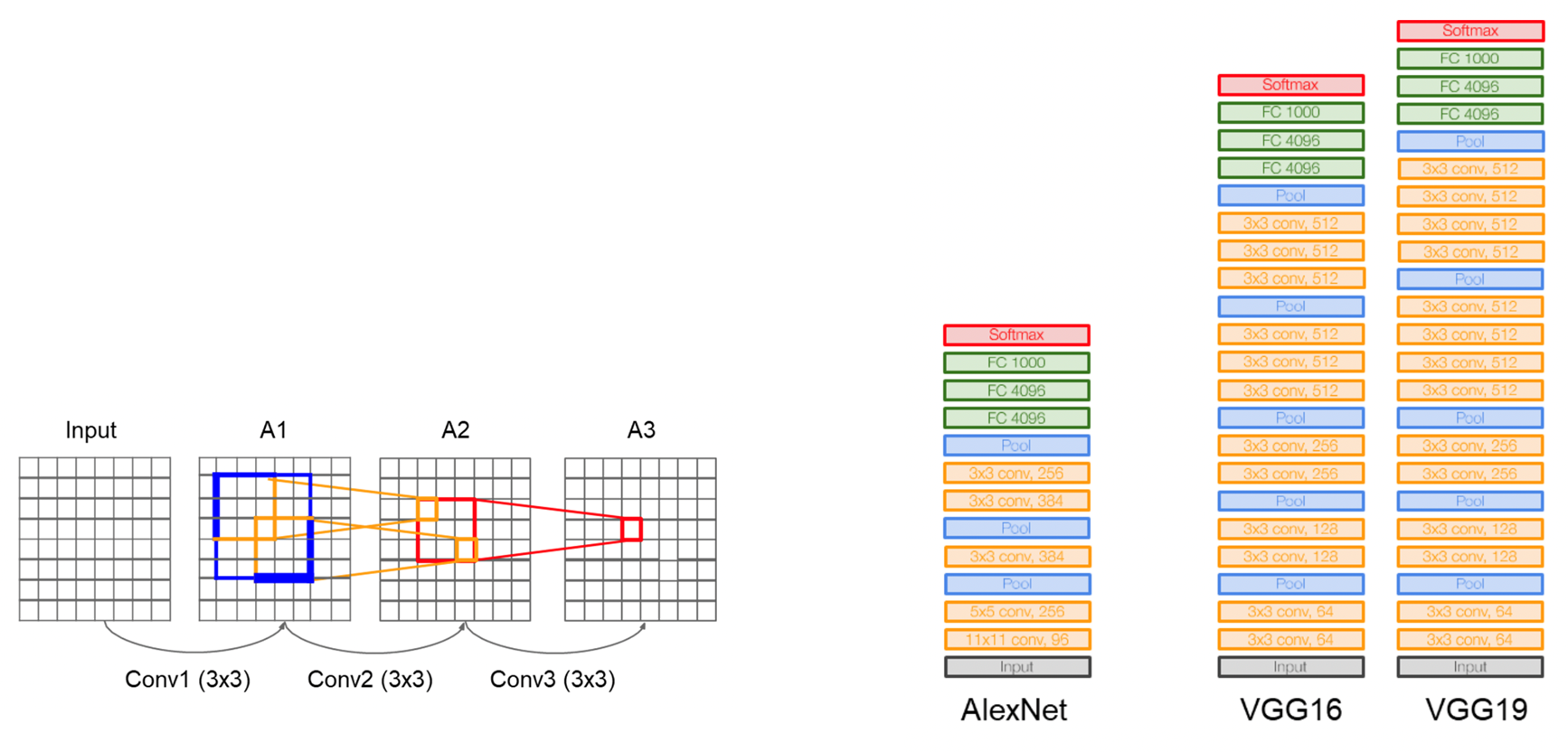
InceptionNet
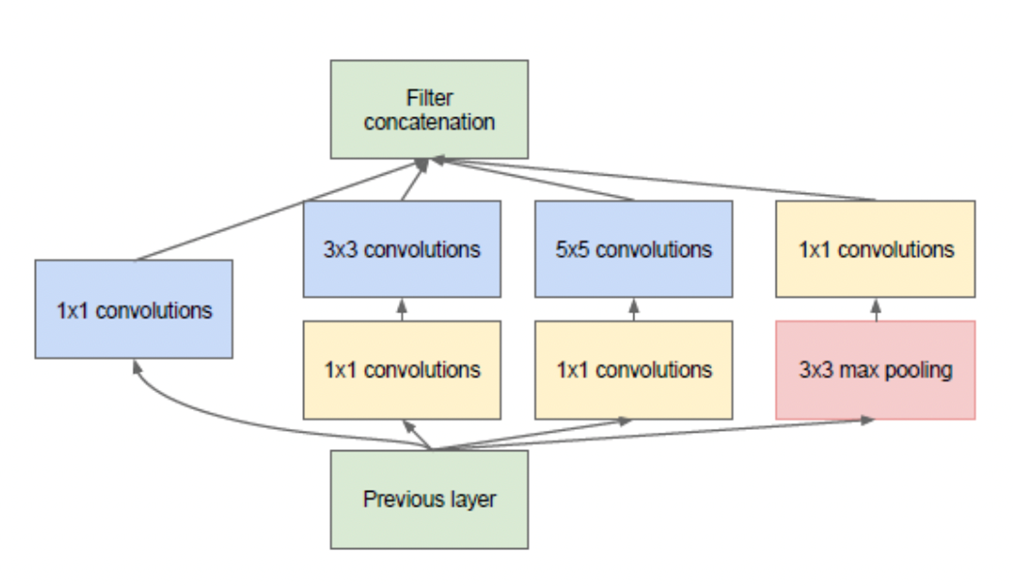
- VGGNet과 비슷한 시기에 나온 구조
- 하나의 블락을 병렬적으로 만듦
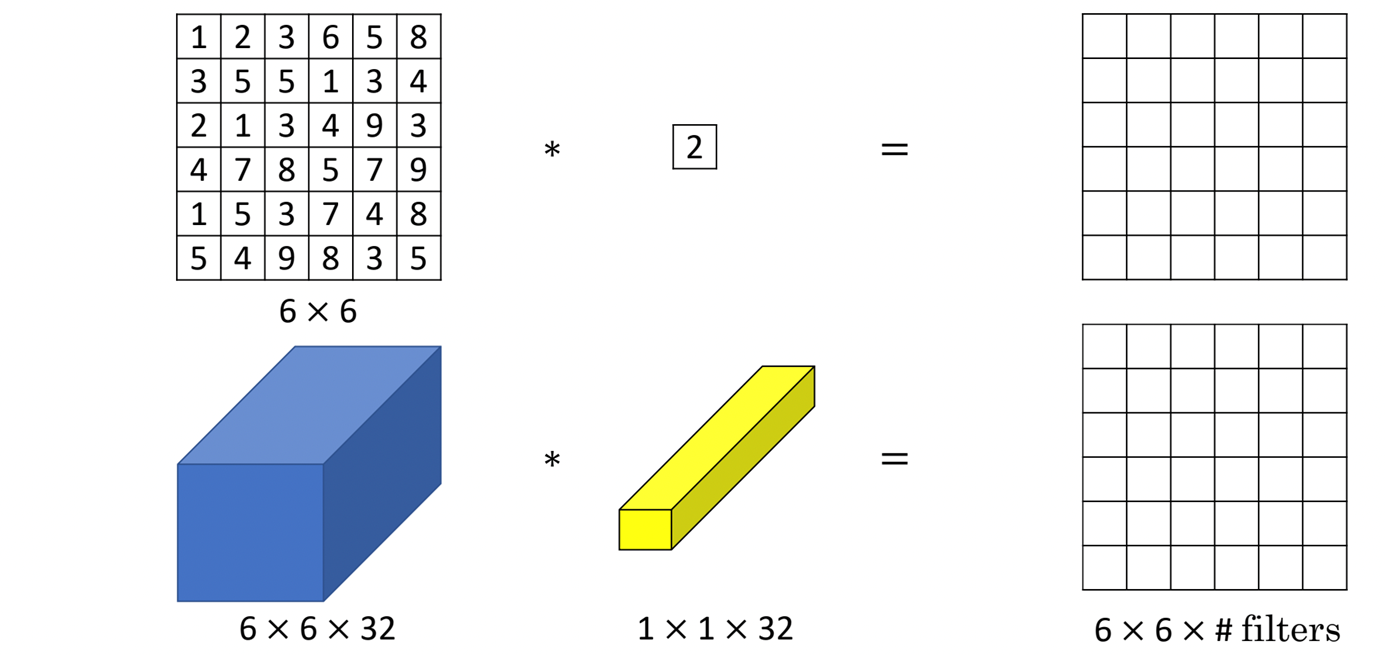
- 1 x 1 convolution을 통과시킴 --> Bottleneck 구조를 위해서 (채널을 압축하기 위해서)
--> 채널들의 정보를 잘 결합하여 특징 추출
--> 파라미터수 감소, 연산량 감소
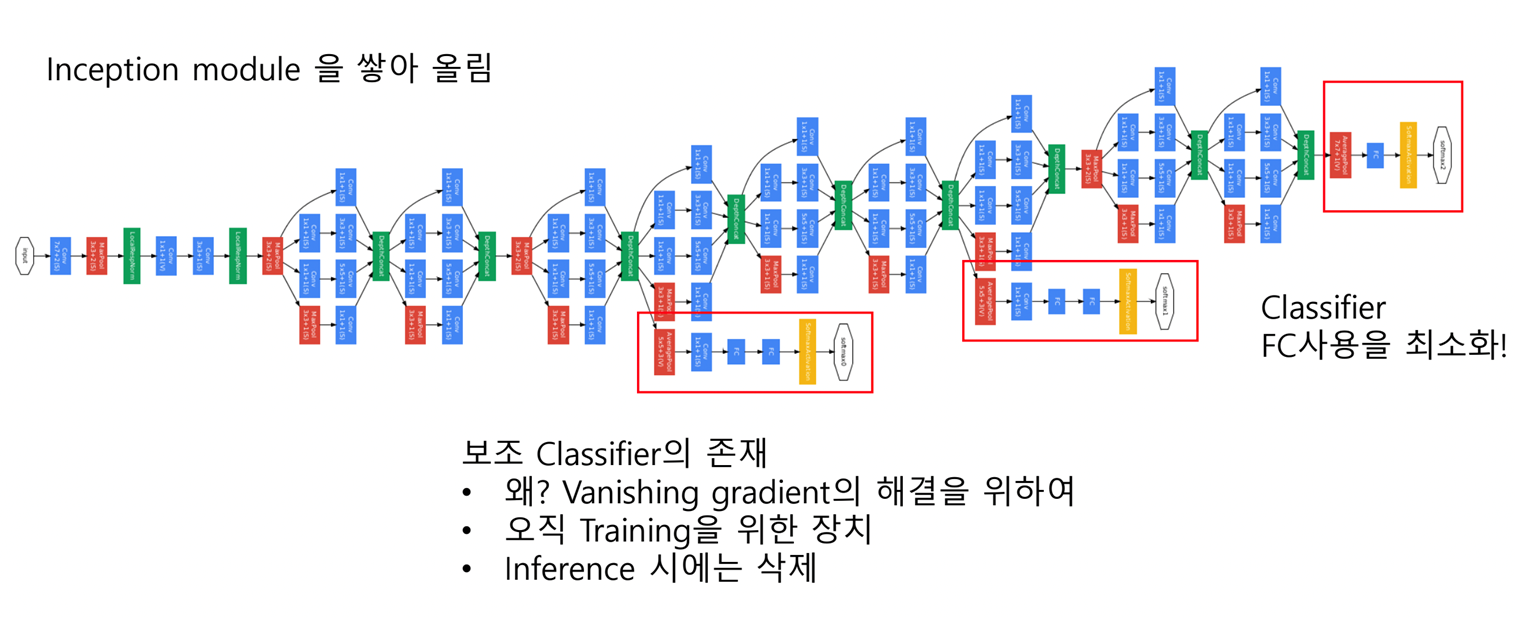
Vanishing Gradient 문제 : 층이 깊어질수록 backprop에서 gradient의 크기가 작아지는 현상
Receptive field의 의미

- 작은 receptive field는 객체의 위치와 부분적인 특징을 파악하는데 도움
- 조금 더 큰 receptive ield는 더 큰 범위의 spatial 특징을 잡아주지만 정답을 내리기에는 이름
- 더 큰 receptive field는 얼굴 전체를 바탕으로 고양이 사진임을 파악하는데 도움을 줌

Sometimes You gotta run before you can walk.