1. Transformer 모델 이해
Transformer 모델은 'Self-Attention' 메커니즘을 핵심으로 하는 복잡한 구조를 가지고 있습니다.
1) Query, Key, Value
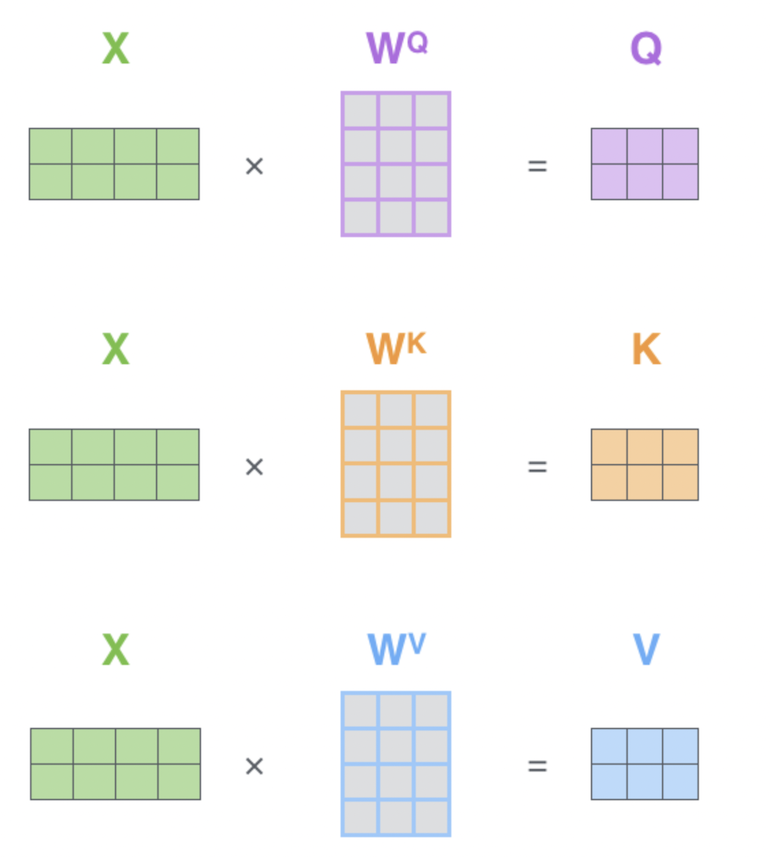
- 각 토큰 (X_1, X_2, X_3)에 대해 Query(Q), Key(K), Value(V) 벡터가 생성됩니다.
- 이들은 각각 특정 가중치 행렬(Wq, Wk, Wv)을 통해 계산됩니다.
- Query는 현재 토큰의 정보, Key는 다른 토큰들과의 관계, Value는 해당 토큰의 실제 정보를 나타냅니다.
2) 유사도 계산과 Self-Attention
- Query (Q_1)와 모든 Key (K_1, K_2, K_3) 간의 유사도를 계산합니다.
- 유사도는 내적(dot product)을 사용하여 계산되며, Softmax 함수를 적용하여 각 Key에 대한 정규화된 유사도 점수를 얻습니다. 이 점수는 각 Value에 얼마나 많은 "주목"을 해야 하는지를 나타냅니다.
- 유사도는 자기 자신에 대해 높은 값을 가지게 됩니다.
3) Attention 값의 계산과 출력
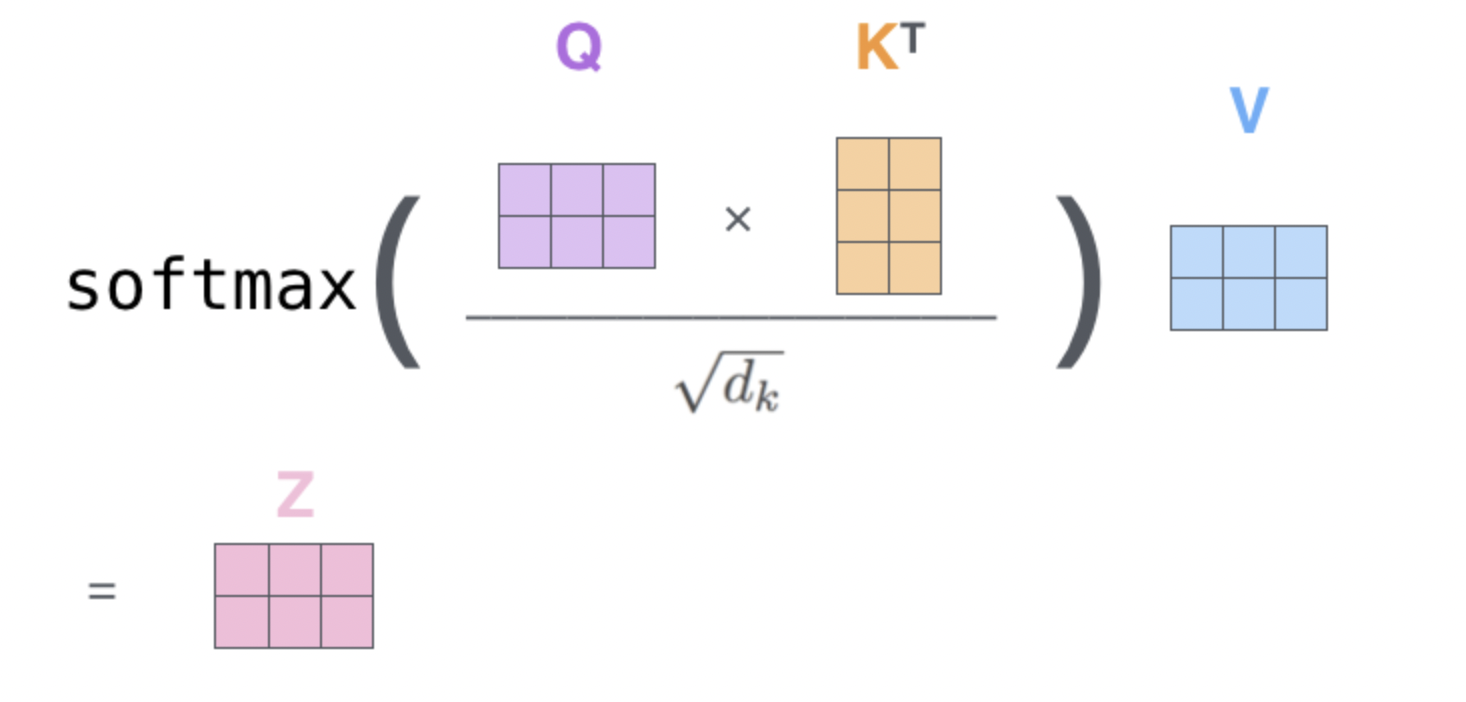
- 계산된 유사도 점수를 각 Value와 곱하고, 이를 모두 더하여 Attention 값을 얻습니다.
- 이 값에 출력 가중치 (W_o)를 곱하여 최종 출력 (Z_1)을 얻습니다.
- 이 과정은 각 토큰에 대해 반복됩니다.
4) Transformer의 핵심 아이디어
- 1~3까지의 과정을 반복하는 여러층으로 쌓아서 학습한다.
- Transformer는 각 토큰이 문장 내의 다른 토큰들과 어떤 관계를 가지는지 학습합니다. 이를 통해 문장의 문맥을 이해하고, 다양한 언어 처리 작업을 수행합니다.
- 'Transformer'라는 이름은 모델이 입력 시퀀스를 변형하여 새로운 시퀀스를 생성하는 능력에서 유래했습니다. 이는 단순히 원래 토큰에 영향을 미치는 것을 넘어서, 전체 문맥을 이해하고 이를 바탕으로 새로운 출력을 생성한다는 의미를 담고 있습니다.
2. Encoder 메커니즘
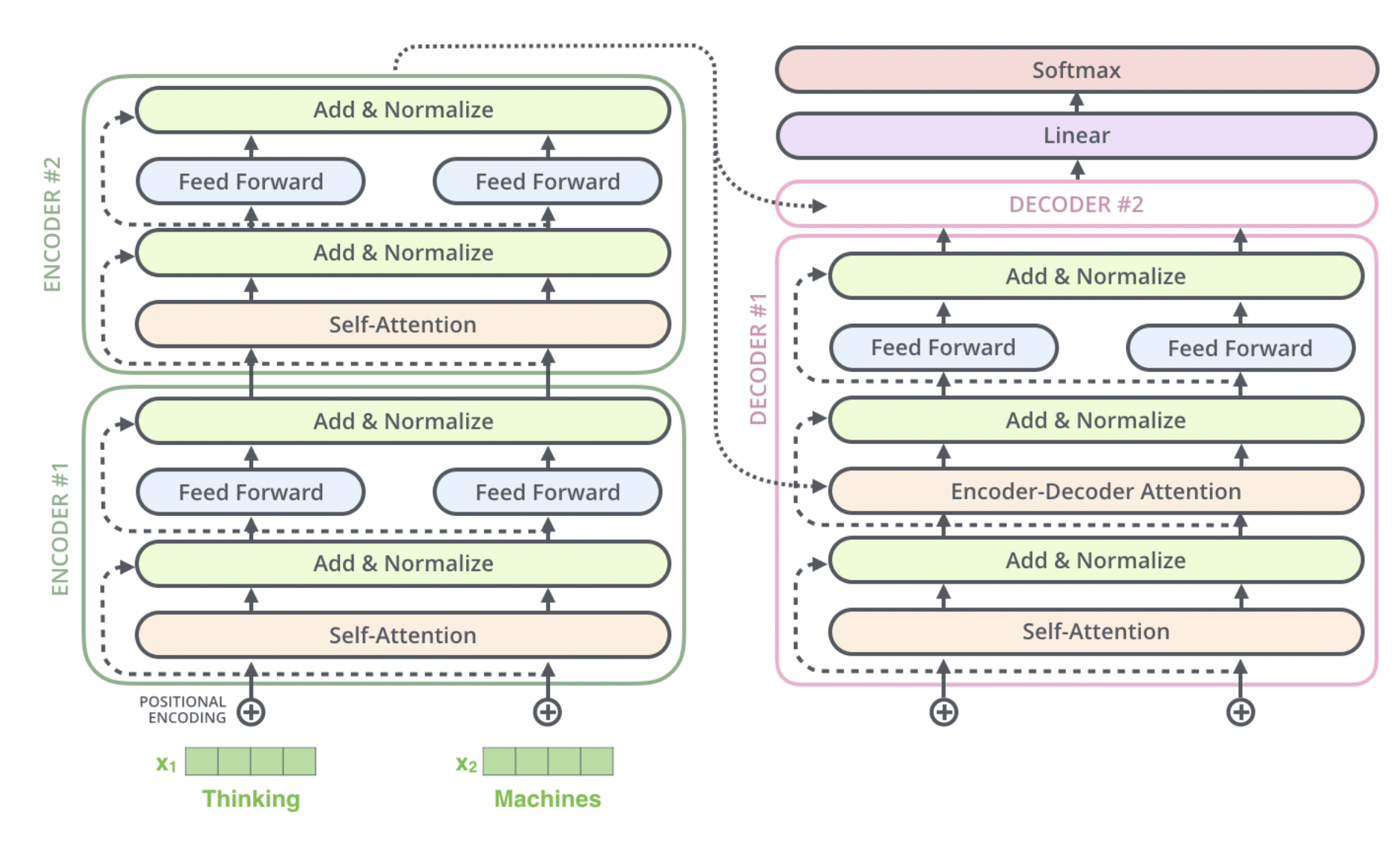
1) Input Embedding 과정
Transformer 모델의 첫 단계인 Input Embedding은 텍스트 데이터를 모델이 처리할 수 있는 형태로 변환하는 중요한 과정입니다.
토큰화(Tokenization)
- 입력된 텍스트는 먼저 '토큰'으로 분리됩니다. 이 토큰은 단어, 문자, 또는 서브워드(subword) 단위일 수 있습니다.
- 토큰화의 목적은 텍스트를 모델이 처리할 수 있는 더 작은 단위로 나누는 것입니다.
토큰을 벡터로 변환
- 각 토큰은 고정된 크기의 벡터로 변환됩니다. 이 과정은 '단어 임베딩(word embedding)'이라고 불립니다.
- 단어 임베딩은 단어의 의미적, 문맥적 정보를 고차원 벡터 공간에 매핑하는 방법입니다.
- 임베딩 벡터는 주로 학습 가능한 파라미터로, 모델 학습 과정에서 최적화됩니다.
임베딩 차원의 정의
- Transformer 모델은 일정한 크기의 벡터를 입력으로 받습니다. 이 크기를 '임베딩 차원(embedding dimension)'이라고 합니다.
- 임베딩 차원은 모델의 크기와 성능에 영향을 미치는 중요한 하이퍼파라미터입니다.
임베딩 정규화 및 스케일링
- 임베딩 벡터는 때때로 정규화되어 각 토큰의 임베딩이 일정한 범위 내에 있도록 합니다.
- 또한, 임베딩 벡터는 모델의 차원과 조화를 이루도록 스케일링될 수 있습니다.
요약
- 의미적 정보의 인코딩: 임베딩은 토큰의 의미적 정보를 포함하고 있어, 모델이 텍스트의 의미를 이해하는 데 중요한 기초를 제공합니다.
- 모델의 입력 형식 제공: Transformer 모델은 벡터 형식의 입력을 요구합니다. Input Embedding은 원시 텍스트를 이러한 형식으로 변환하는 필수적인 단계입니다.
- 학습의 시작점: 임베딩 벡터는 모델 학습의 출발점을 제공하며, 학습 과정에서 지속적으로 최적화되어 갑니다.
2) Multi-Head Attention
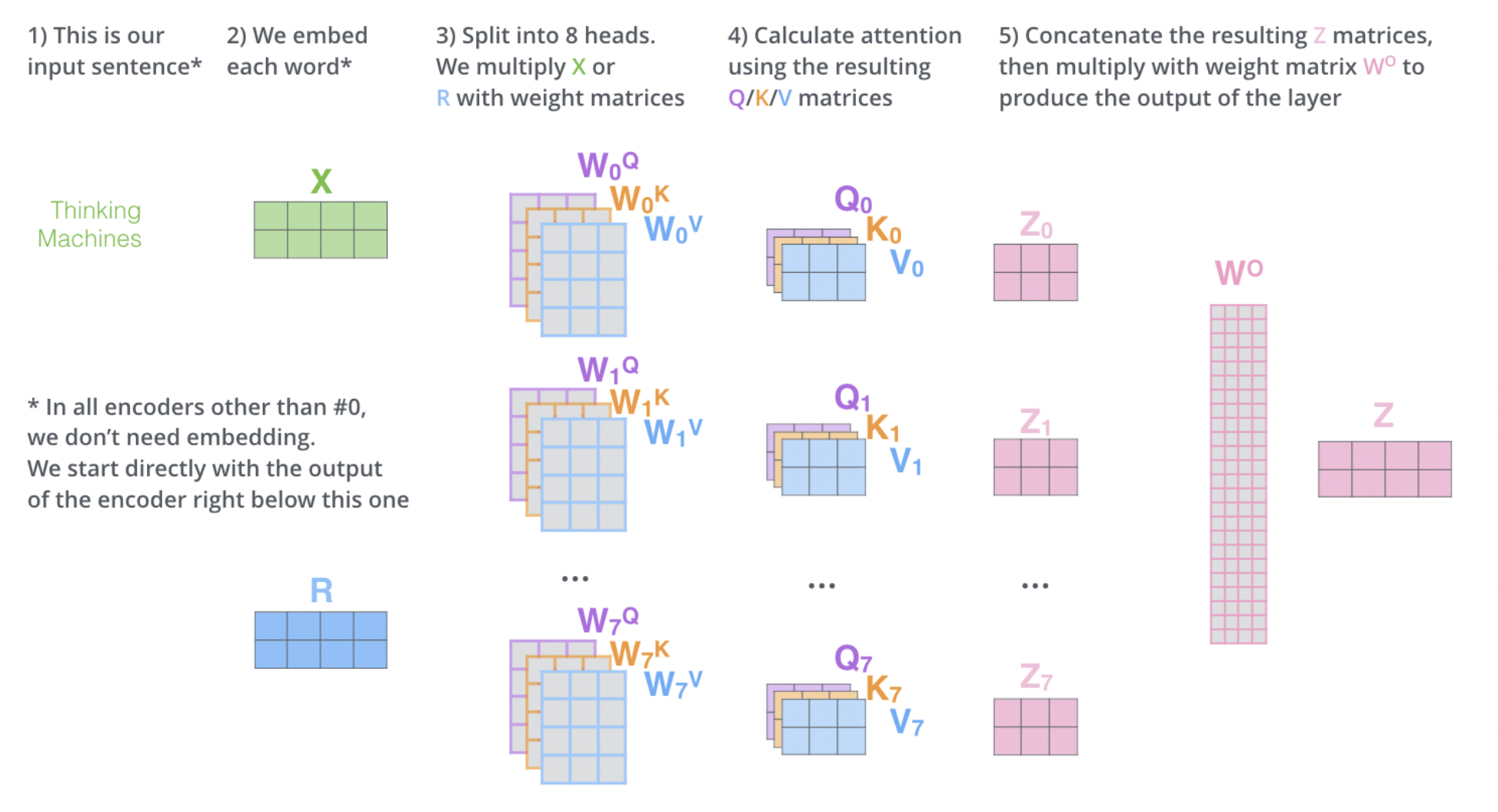
역할
- 병렬 처리: 여러 개의 Self-Attention 메커니즘이 병렬로 동작합니다. 각 'head'는 독립적으로 작동하며, 서로 다른 가중치 행렬을 사용합니다. 즉, 각 헤드는 독립적으로 Q, K, V 변환을 수행하며, 각각 다른 가중치 행렬 (W^Q_i, W^K_i, W^V_i)을 사용합니다.
- 다양한 관점에서의 학습: 이러한 병렬 구조는 모델이 다양한 관점에서 데이터를 학습하도록 합니다. 즉, 각 head는 입력 데이터의 다른 측면이나 패턴을 포착할 수 있습니다.
- 결합과 통합: 각 head에서 계산된 Attention 결과는 결합되어 하나의 단일 출력 벡터로 통합됩니다. 이는 추가적인 가중치 행렬 (W^O)을 통해 최종적인 Multi-Head Attention의 출력이 생성됩니다.
중요성 및 이점
- 풍부한 문맥 이해: 다양한 관점에서의 학습으로 모델은 동일한 데이터를 다양한 방식으로 해석합니다.
- 유연성: 각 head가 서로 다른 유형의 정보를 포착함으로써 모델은 더 유연해 집니다.
- 특정 문맥에 대한 민감도 증가: 다양한 문맥이나 의미상 중요한 요소에 대해 더 잘 반응할 수 있습니다.
요약
- Multi-Head Attention은 Transformer 모델이 입력 데이터를 다양한 차원에서 깊이 있게 이해할 수 있도록 하는 핵심 요소입니다. 이는 특히 복잡한 자연어 처리 과제에서 모델의 성능을 크게 향상시킵니다.
3) Feed-Forward 네트워크(FFN)
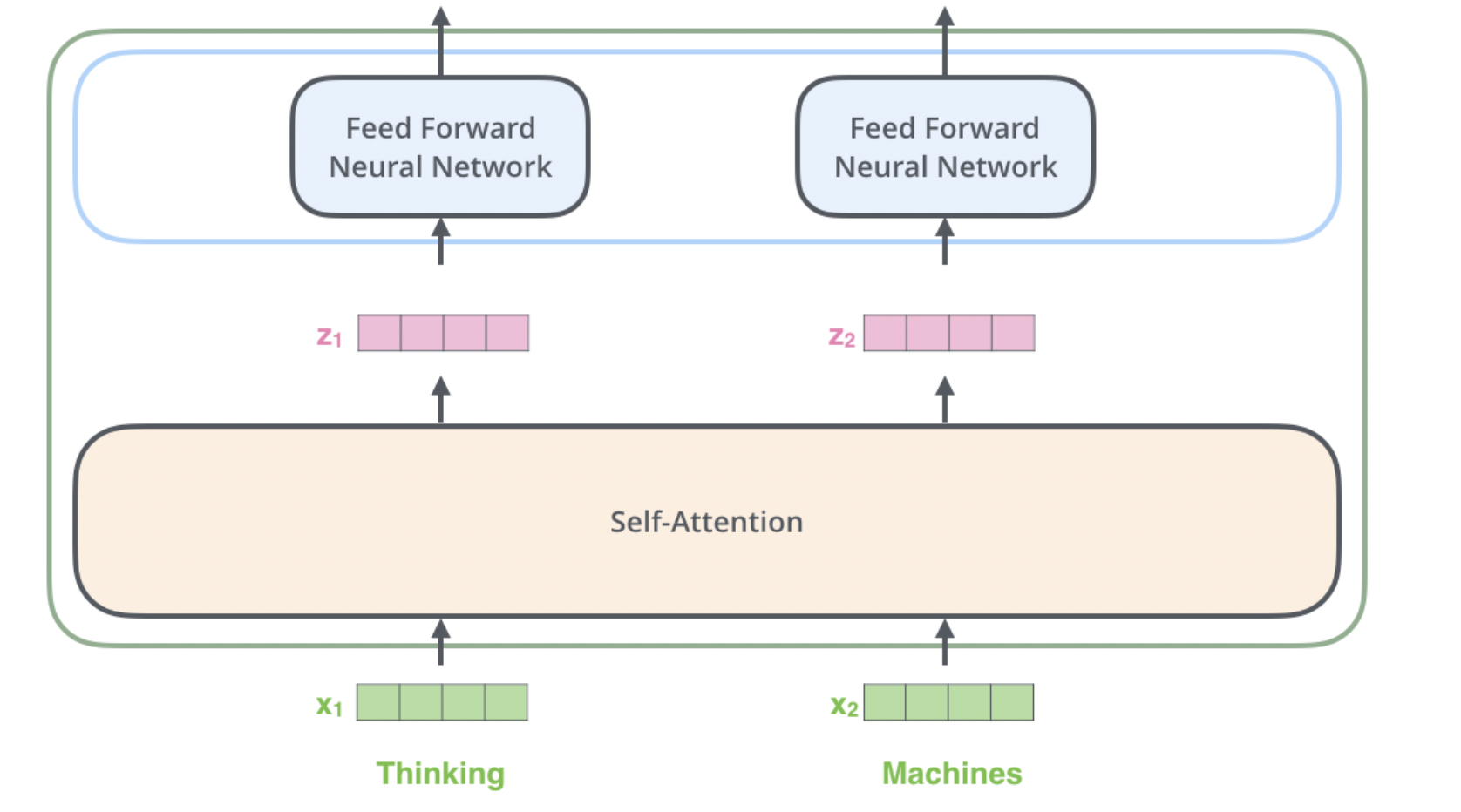
역할
비선형성 추가
- Multi-Head Attention은 선형 변환을 사용하여 입력 데이터 간의 관계를 모델링합니다.
- FFN은 이 선형적인 정보를 비선형적으로 변환하여, 모델이 더 복잡한 패턴과 관계를 학습할 수 있도록 합니다.
층간 표현력 강화
- FFN은 각 Attention 레이어의 출력에 대해 별도의 처리를 수행합니다.
- 이는 인코더가 단순히 입력 데이터의 상호작용뿐만 아니라, 더 깊은 데이터의 특징을 추출하고 이해할 수 있게 합니다.
모델의 유연성 증가
- Attention 메커니즘과 FFN의 조합은 모델에 더 큰 유연성을 제공합니다. 이는 다양한 유형의 데이터와 복잡한 문제를 처리하는 데 중요합니다.
Feed-Forward 네트워크(FFN) 메커니즘
구조
- FFN은 두 개의 선형 레이어와 비선형 활성화 함수로 구성됩니다.
- 첫 번째 레이어는 입력을 확장하고, 활성화 함수를 통해 비선형 변환을 적용한 후, 두 번째 레이어를 통해 다시 원래 차원으로 줄입니다.
활성화 함수
- 주로 ReLU(Rectified Linear Unit) 또는 그 변형들이 사용됩니다.
- 이 함수는 모델에 필요한 비선형성을 제공하여, 선형적으로 분리할 수 없는 데이터 패턴을 학습하는 데 도움을 줍니다.
레이어 구성
- 첫 번째 레이어(확장 레이어)는 입력 데이터의 차원을 증가시킵니다.
- 활성화 함수를 거친 후, 두 번째 레이어(축소 레이어)는 이 정보를 다시 압축하여 원래의 차원으로 복원합니다.
개별 처리
- FFN은 각 위치의 입력을 독립적으로 처리합니다. 즉, 각 위치에서의 계산은 다른 위치의 계산에 영향을 받지 않습니다. 이는 모델이 각 위치에서 독특한 정보를 학습할 수 있게 합니다.
파라미터
- transformer의 모든 인코더 레이어는 동일한 구조의 FFN을 사용하지만, 각 레이어는 서로 다른 파라미터(가중치)를 가집니다. 이는 모델이 각 레이어에서 다른 특징을 학습할 수 있게 합니다.
요약
- FFN을 사용하여 Transformer 인코더의 기능을 크게 향상시키며, 모델이 더 복잡한 데이터 표현을 학습할 수 있게 합니다.
4) Positional Encoding
Positional Encoding은 모델이 입력 시퀀스의 순서 정보를 인식할 수 있도록 합니다.
Positional Encoding의 역할과 필요성
순서 정보 제공
- Transformer는 입력 데이터의 순서에 대한 정보가 내재되어 있지 않습니다.
- Positional Encoding은 각 단어의 위치 정보를 모델에 제공하여, 단어들 사이의 관계와 문장의 문맥을 더 잘 이해할 수 있게 합니다.
Positional Encoding 메커니즘
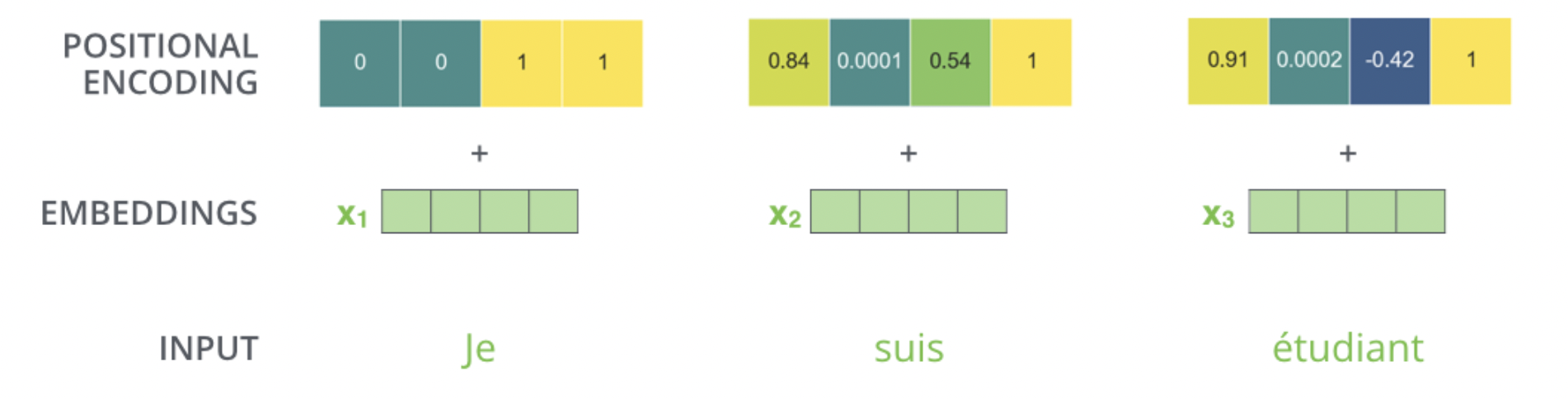
수학적 공식
- Positional Encoding은 사인(Sine)과 코사인(Cosine) 함수를 사용합니다.
- 각 위치 (pos)와 차원 (i)에 대해 다음 공식이 사용됩니다:
- (PE(pos, 2i) = \sin(pos / 10000^{2i/d_{model}}))
- (PE(pos, 2i+1) = \cos(pos / 10000^{2i/d_{model}}))
- (pos): 'pos'는 단어의 위치를 나타냅니다. 문장에서 첫 번째 단어는 (pos = 0), 두 번째 단어는 (pos = 1) 등으로 표현됩니다.
(i): 'i'는 벡터 차원의 인덱스를 나타냅니다. Transformer 모델의 각 단어는 (d{model}) 차원의 벡터로 표현되며, (i)는 이 벡터의 각 차원을 가리킵니다.
(10000^{2i/d{model}}): 이 부분은 각 차원에 대해 다른 주기를 갖는 사인과 코사인 함수의 주파수를 조정합니다.
- (pos): 'pos'는 단어의 위치를 나타냅니다. 문장에서 첫 번째 단어는 (pos = 0), 두 번째 단어는 (pos = 1) 등으로 표현됩니다.
주기적 패턴 사용
- 사인과 코사인 함수는 주기적인 값을 가집니다.
- 이를 통해 각 위치에 고유한 값이 할당되어, 모델이 위치를 구별하는 데 도움을 줍니다.
인코딩의 결합
- 생성된 Positional Encoding은 Input Embedding과 결합됩니다.
- 이를 통해 각 입력 토큰의 Embedding에 위치 정보가 추가됩니다.

Pay it forward