EfficientNet
Introduction
CNN의 성능은 주로 이미지 해상도, 네트워크의 너비, 네트워크의 깊이가 영향을 미친다.
기존의 작업들은 CNN의 성능을 높히기 위해서 이들 3개중 하나의 크기만 조정하는 것이 일반적이었지만 이 논문에서는 네트워크 깊이, 너비, 해상도의 균형을 맞추는 것이 중요하다는 결론이 나왔다. 단순히 일정한 비율로 각 차원을 확장함으로써 달성했다.
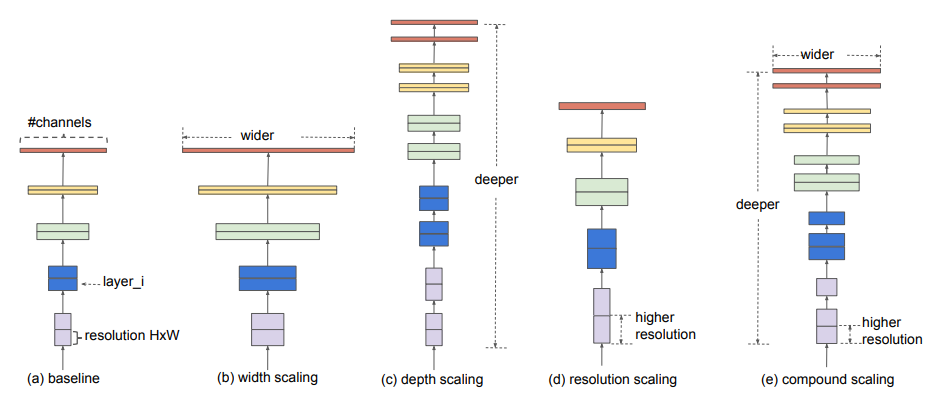
a는 기존의 모델이고 b는 너비(Channel 수, layer안의 연산)를 늘린 것이고 c는 깊이(layer 개수)를 늘린것이고 d는 이미지 해상도를 늘린 것이고 마지막 e는 복합적 scaling에 해당한다.
Width scaling
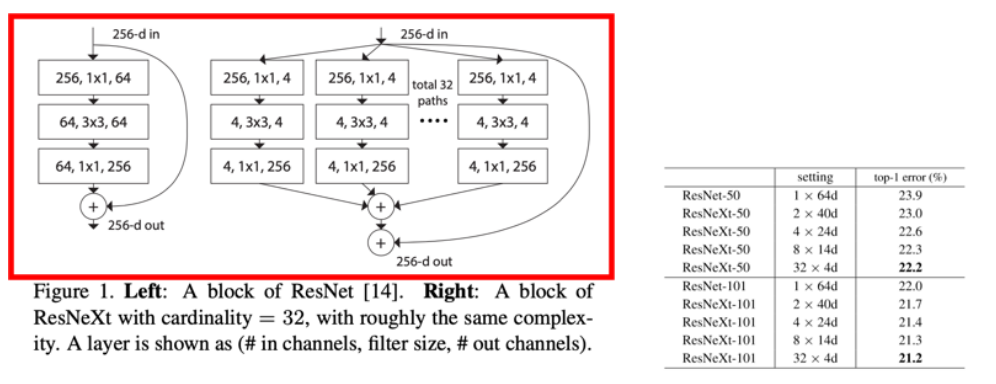
너비를 늘린 것으로 ResNet에서 한 layer의 폭을 넓혀서 만든것이 ResNext인데 성능의 개선이 된 것을 확인할 수 있다.
Depth scaling
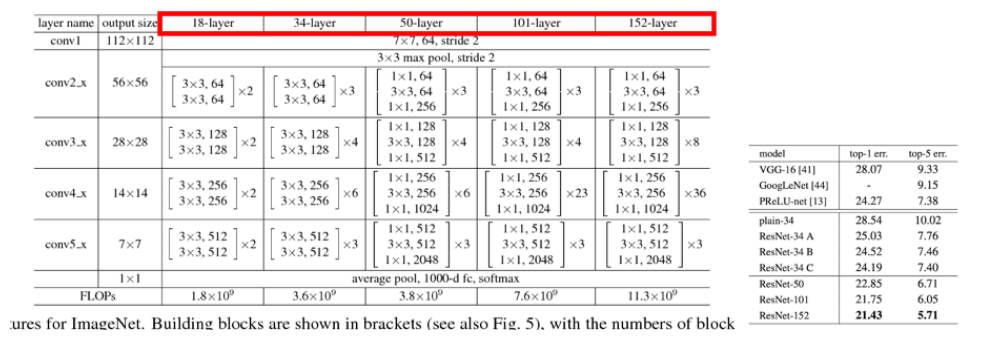
layer를 더 깊게 한 것으로 ResNet에서 성능 향상을 확인할 수 있다.
Resolution scaling
이미지의 해상도를 높힌 것으로 입력 해상도가 작을수록 CNN을 거치면서 소실되거나 추출되지 않는 정보가 생기기 때문에 성능이 증가한다.
Compound scaling
ConvNet Layer i는 function으로 정의 될 수 있다. 입력값은 각 layer 함수를 거쳐서 최종 출력값이 나오게 되는데 수식으로 나타내면 다음과 같다.
이를 일반화하면 다음과 같다.
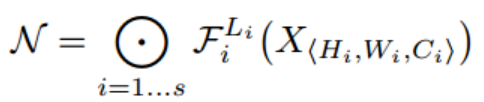
위 식은 CNN을 표현한 것으로 Conv Layer 여러개를 쌓은 형태이다.
여기서 는 입력값을 나타내고 은 출력값을 는 spatial dimension을 는 channel dimension을 나타낸다.
각 layer에서 수행하는 연산 F를 고정하고 layer,channel,이미지 크기에 집중하여 search space가 감소한다.
w,d,r는 각각 width,depth,resolution을 의미하고 이 상수들의 관계를 연구한 것이 EfficientNet이다.
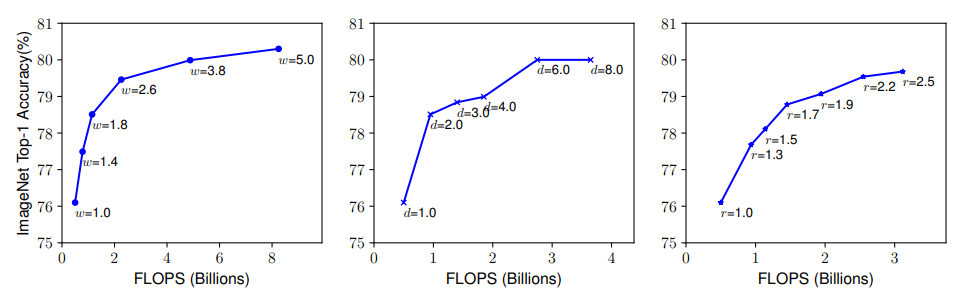
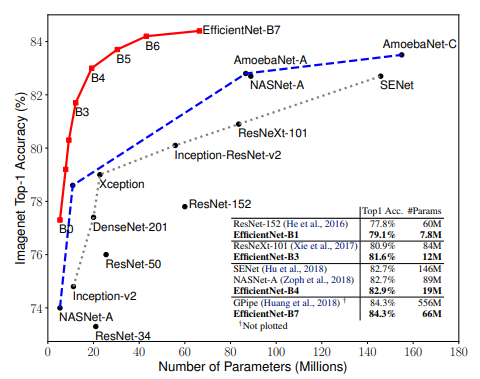
EfficientNet은 기초적인 CNN모델을 만들어서 왼쪽부터 Width(Channel 수), Depth(layer 수), Resolution(해상도)를 높혀가면서 실험을 했다. 모든 곡선은 비슷한 방향으로 수렴해가는 것을 확인할 수 있다. 기존의 모델들은 이 3가지중 한가지를 확장하는 식으로 ConvNet의 성능을 개선시켜왔다.
Depth
깊이를 확장하면 더 풍부하고 복잡한 feature를 capture할 수 있다. 그리고 새로운 task에 대해서 잘 일반화시킬 수 있다. 그러나 대신 학습시키기 어렵고 기울기 소실의 문제가 발생한다. 물론 skip connection, batch-normalization등으로 기울기 소실은 어느 정도 해소 가능하지만 그렇게 하면 정확도가 낮아진다.
Width
일반적으로 소형 모델에서 사용한다. 더 넓은 네트워크는 더 세분화된 features들을 capture하기 쉽고 학습이 용이하다.그러나 매우 넓고 얇은 네트워크는 더 높은 수준의 feauture를 capture 하는 것이 어렵다.
Resolution
더 높은 해상도를 사용하면 ConvNet은 잠재적으로 더 세분화된 패턴을 capture할 수 있다. 그러나 매우 높은 해상도의 경우에는 정확도 이득이 감소한다.
결론
네트워크의 깊이 너비 그리고 이미지 해상도를 높히는 것은 정확도가 향상되지만 더 큰 모델에서는 정확도 이득이 감소한다.
그림을 보면 3 모델 모두 정확도가 80% 까지는 빠르게 증가되고 그 이후로의 성능향상은 한계가 있는 것을 확인할 수 있다.
Compound Scaling
위의 결과로 이 논문에서는 width,depth,resolution을 적정하게 조합하는 compound scaling을 진행했다.
Φ가 1일 때의 $α x β^2 x γ^2 \approx 2를 만족하는 α,β,γ를 grid search(모델 하이퍼 파라미터에 넣을 수 있는 값들을
순차적으로 입력한뒤에 가장 높은 성능을 보이는 하이퍼 파라미터들을 찾는 탐색 방법)를 통해 찾는다.
width 와 resolution에 제곱을 하는 이유는 depth가 2배 증가하면 FLOPS는 2배가 되지만 width와 resolution은 그렇지 않기 때문이다.
width는 이전 layer의 출력, 현재 layer의 입력 두곳에서 연산이 되므로 wdith가 2배가 되면 4배의 FLOPS가 되고 resolution은 가로 x 세로이기 때문에 resolution이 2배가 되면 4배의 FLOPS가 된다.
grid search를 통해 α,β,γ를 찾으면 Φ(0,0.5,1,2,3,4,5,6)를 사용하여 최종적으로 width, depth, resolution에 곱할 facor를 만들게 된다.
여기서 Φ는 사용자 리소스(GPU 성능)에 따라서 사용자가 조절할 수 있다.
-> Φ의 변화로 인해 모델이 b0~b7까지 설계하였다.
위와 같은 total FLOPS 설정 덕분에, total FLOPS는 만큼 증가한다.
논문에서 찾은 최적의 α값은 1.2 β값은 1.1 γ값은 1.15이고 이때 FLOP이 2배에 가까우면서 최고의 성능이 나왔다.
Architecture
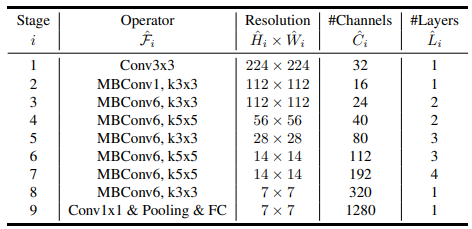
scaling 을 하지 않은 기본 baseline 구조이다. Operator의 MBConv는 Mobilenet v2에서 제안된 inverted residual block을 의미하고 1,6은 expand ratio이다.
Inverted Residual Block은 bottleneck 이후 채널을 확장시킨다.
Inverted 구조는 메모리 사용측면에서 효율적이다.
활성화 함수로 ReLU가 아닌 Swish를 사용했는데 매우 깊은 신경망에서 ReLU보다 높은 정확도를 달성한다고 한다.
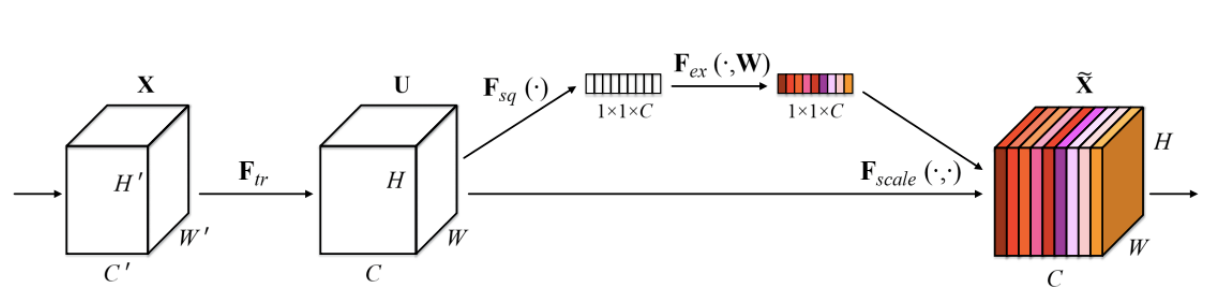
squeeze-and-excitation 을 추가했는데 이것은 pooling을 통해 1x1 size로 줄여서 정보를 압축한 뒤에 그 정보들을 weighted layer와 비선형 activation funcion으로 각 channel별 중요도를 계산하여 기존 input에 곱해주는 방식이다.
