VGGNet
요약: 네트워크의 깊이가 모델의 성능에 중요한 영향을 미친다는 것을 설명한 논문
Abstract

초록에서는 3x3 Conv filter를 여러개 쌓아서 성능을 높혔고 large-scale image recognition에서도 좋은 결과를 내었다고 설명하고있다.
Introduction

역시 마찬가지로 깊이가 매우 중요하며 이를 위해서 여러 파라미터들을 수정하고 안정적으로 convolution layer들을 쌓아서 깊이를 늘렸다. 모든 층에 아주 작은 3x3 conv filter들을 사용해서 가능하게 되었다.
ConvNet Configurations
Architecture

먼저 구조를 살펴보면 다음과 같이 정리할 수 있다.
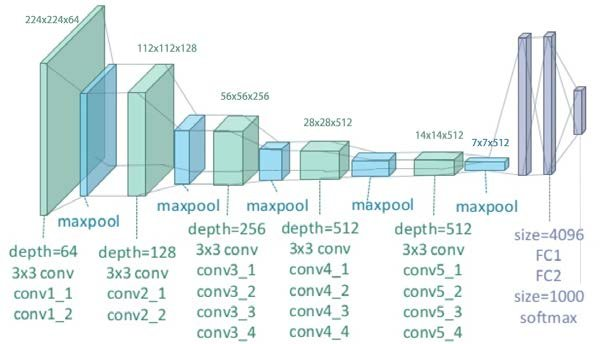
입력값 : 224 x 224 RGB 이미지
입력된 이미지는 3x3 Conv filter(좌/우, 상/하, 중앙의 개념을 포착하기 위해 가장 작은 크기)를 적용한 ConvNet을 통과한다. 이때 비선형을 위해 1x1 Conv filter도 적용한다.
공간해상도를 유지시키기 위해서 stride,padding이 각각 1씩 적용이 된다.
Pooling layer는 5개의 max pooling layer로 구성이 되고 2x2 size에 stride는 2이다.
Conv layers 뒤에는 3개의 FC-layer가 있다. 처음 2개는 4096개의 채널을 가지고 마지막 하나는 1000개의 채널을 갖는다.
마지막으로 Softmax layer를 적용한다.
모든 hidden layer에서 ReLU 활성화 함수를 사용하고 LRN(Local Response Normalization)은 성능에 영향을 미치지 않고 오히려 메모리 사용량이 늘고 시간이 오래 걸리기 때문에 사용하지 않았다.
Configurations

깊이에 따라 구조가 조금씩 바뀌며 11~19층까지의 구조를 가진 모델들로 나뉜다. Conv layer의 폭은 64부터시작해서 2의 제곱만큼씩 늘어나서 최대 512까지 늘어난다. 깊어져도 오히려 더 넓은 Conv layer를 사용한것보다 더 적은 파라미터가 나왔다고 한다.
Discussion


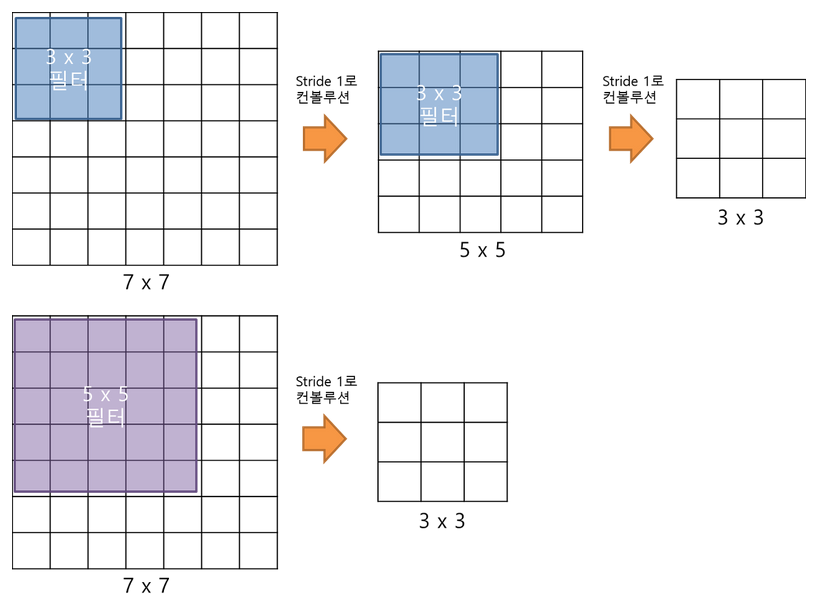
커다란 Conv filter 대신 여러 개의 3x3 Conv filter를 사용하는 이유는 작은 사이즈로 여러번 나눠서 적용하는 것이 더 많은 ReLU를 통과하게 되어서 non-linear한 결과값을 더 잘 도출하게 되기 때문이다. 그리고 파라미터의 수도 줄어들게 된다.
3x3 Conv filter 2개를 사용했을 때 필요한 파라미터의 수 : 2(C) = 18C이고 5x5 Conv filter 1개를 사용했을 때 필요한 파라미터의 수는 25C 이 되므로 파라미터가 감소하는 것을 확인할 수 있다.
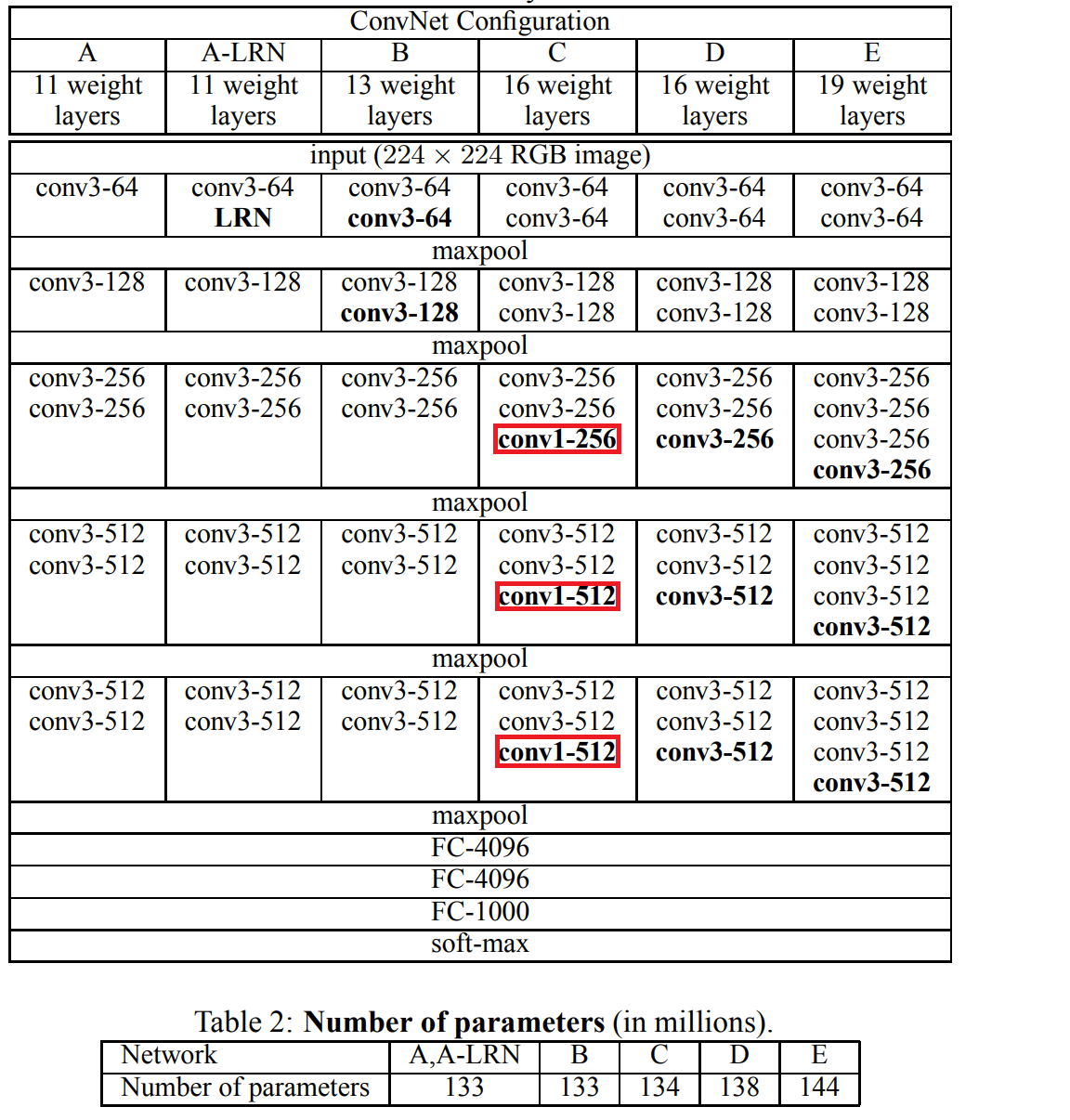
추가로 C모델에서는 1x1 Conv layer를 추가하여 ReLU를 거치면서 추가적인 비선형성을 가질 수 있다.
import torch
import torch.nn as nn
class VGG_A(nn.Module):
def __init__(self, num_classes: int = 1000, init_weights: bool = True):
super(VGG_A, self).__init__()
self.convnet = nn.Sequential(
# Input Channel (RGB: 3)
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, padding=1, stride=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # 224 -> 112
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1, stride=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # 112 -> 56
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, padding=1, stride=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1, stride=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # 56 -> 28
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, padding=1, stride=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1, stride=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # 28 -> 14
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1, stride=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1, stride=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # 14 -> 7
)
self.fclayer = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes),
# nn.Softmax(dim=1), # Loss인 Cross Entropy Loss 에서 softmax를 포함한다.
)
def forward(self, x:torch.Tensor):
x = self.convnet(x)
x = torch.flatten(x, 1)
x = self.fclayer(x)
return xClassification Framwork
Training

Training에서는 학습시에 설정했던 파라미터에 대한 설명이 나와있다.
batch_size : 256
momentum : 0.9
weight decay : 0.0005
drop out : 0.5
epoch = 74
lr = 0.01 (validation error가 높아질수록 10배씩 감소)
또한 VGGNet은 AlexNet과 동일하게 학습이 진행되는데 AlexNet보다 더 깊고 많은 parameter를 가져도 작은 filter size와 특정 layer에서의 pre-initialization덕분에 더 적은 epoch를 가진다.
Pre-initialization
A모델을 먼저 학습을 하고 다음 모델을 구성할 때 A에서 학습된 layer를 사용하여 최적의 초기값을 설정하는 것이다. 이렇게 함으로써 gradient vanishing문제도 해결하고 epoch도 단축시킬 수 있었다고 한다.
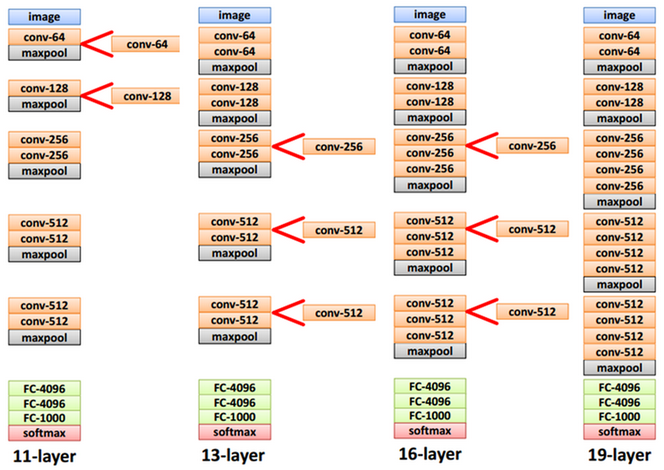
ll-layer 중간에 conv layer를 추가해서 13-layer를 만들고 다시 conv layer를 추가해서 16,19 layer들도 차례로 만들었다.

VGG 모델을 학습시킬 때에는 반드시 input size에 맞게 바꿔줘야한다. S는 training image의 Scale 파라미터인데 input image의 가로 세로 두 변중 더 작은것을 이 S에 맞춰준다. S를 224가정을 하고 사이즈를 변경할 때 이 때 원본 사이즈의 가로와 세로 비율과 동일하게 맞춰준다. 그 후에 224x224 사이즈로 crop하여 input사이즈를 맞춘다.




S를 설정하는 방식에는 크게 2가지로 접근했다.
Single Scale Training
S를 256 혹은 384로 고정하는것이다. 먼저 256으로 학습을 진행시킨 뒤에 빠른 속도를 위해 384로 학습을 진행할 때에는 pre-trained된 weights를 사용하고 보다 더 작은 lr를 사용한다.
Multi-Scale Training
S를 고정시키지않고 256~512중에 랜덤하게 설정하는 것이다. 이미지들은 대부분 사이즈가 제각각이기 때문에 이 방식으로 하면 더 좋은 학습결과를 기대할 수 있다. 이 방식을 Scale Jittering이라고 한다.
Testing

앞서 train단계에서 사용했던 S파라미터와 마찬가지로 test단계에서는 Q라는 파라미터를 사용한다. Q와 S가 반드시 같을 필요는 없지만 각각의 S값마다 다른 Q값을 적용했을 때 모델의 성능이 좋아졌다고 한다.
기존 CNN 모델에서 FC layer를 사용할 때 Node의 개수가 Hyperparameter로 정해져있기 때문에 Convolution으로 Feature 추출해서 FC layer로 전달할 때 사용되는 Parameter 수도 정해져있었다. 그래서 Image의 크기가 바뀌면 Conv layer와 FC layer 사이에 필요한 파라미터의 수가 변하게 되어서 학습을 진행할 수 없었다. VGGNet에서는 그러한 문제를 다음과 같은 방법으로 해결했다.
Fully Connected Layer가 Conv Layer로 변환된다. 첫번째 FC layer는 7x7 Conv layer로 마지막 두 layer는 1x1 Conv layer로 변환된다. FC layer와 1x1 Conv layer가 서로 대치될 수 있는 이유는 FCN은 모든 노드가 다음 layer의 모든 노드들과 연결되기 때문이다.
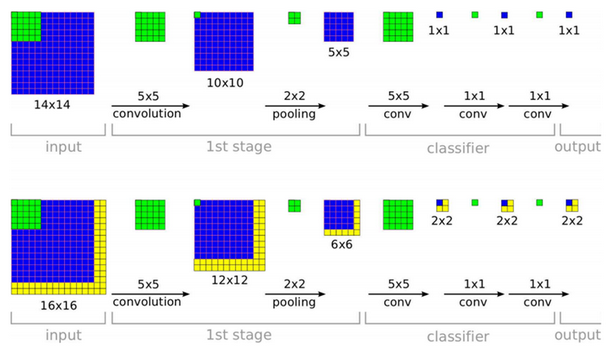
Train할때에는 반드시 입력이미지의 사이즈를 맞춰야 했지만 FC layer가 1x1 Conv layer로 변환되었기 때문에 Test에서는 굳이 사이즈를 맞추지 않아도 된다. 하지만 최종 output feature map size는 input image size에 따라 달라진다. output feature map size가 1x1이 아닌 경우를 class score map이라고 하며 mean or average pooling을 적용한다.
Classification Experiments
Single Scale Evaluation
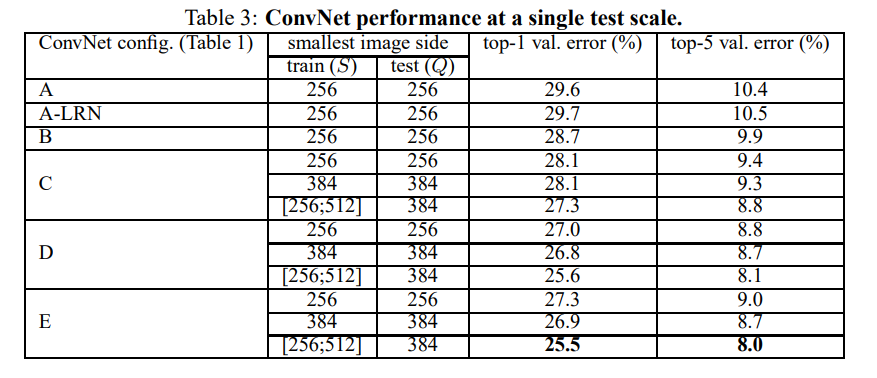
top-1 error는 Multi-class classification error이고 top-5 error는 예측한 상위 5개의 결과중에 정답이 없는 비율을 의미한다.
깊이가 깊어질수록 결과가 좋아지고 scale jittering하면 결과가 더 좋게 나온다는 것을 확인할 수 있다.
Multi-Scale Evaluation
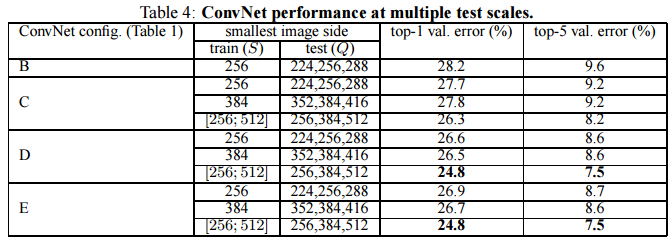
Q값을 S-32,S,S+32로 변화시켜서 확인한 결과값이다.
마찬가지로 scale jittering한 결과값이 single scale 보다 더 좋은 error 수치를 기록하고있다.
Multi-Crop Evaluation
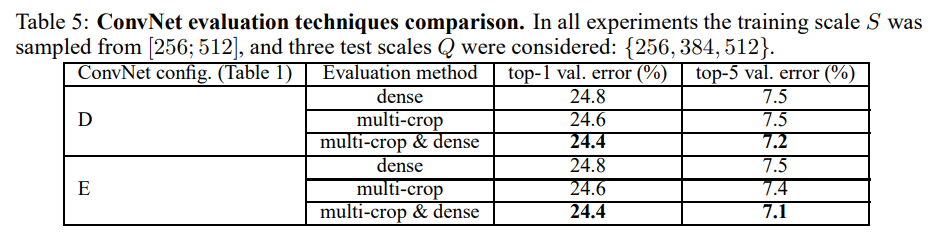
multi-crop과 dense를 같이 사용하면 좋은 결과를 얻을 수 있다.
ConvNet Fusion
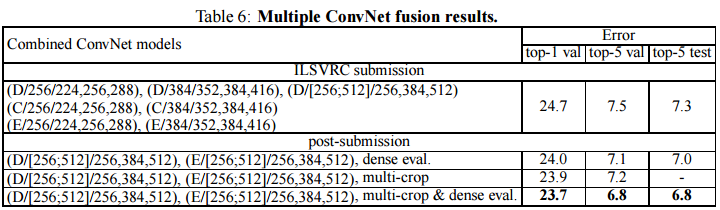
더 나은 성능을 위해 모델을 앙상블한 결과값을 나타낸 것이다. 모델 7개를 앙상블해서 최종결과로 제출했고 추후에 D,E만을 앙상블하여 error값을 더 낮췄다고 한다.
