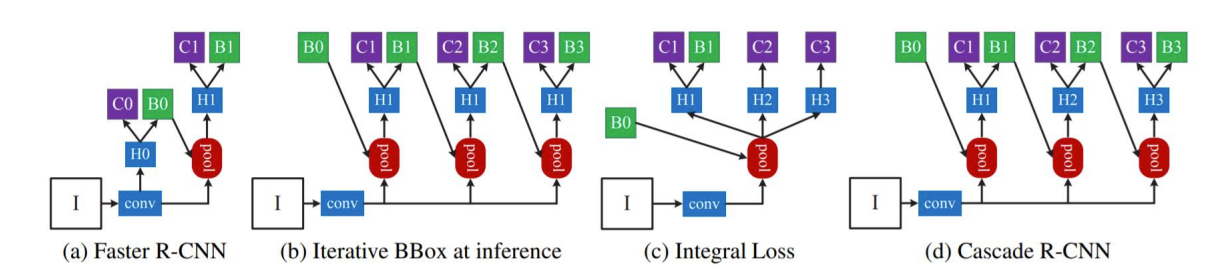
Cascade RCNN
Faster RCNN을 학습할 때 배경과 객체를 나누는 기준이 threshold가 0.5였는데 이것을 바꿔서 실험을 해 보았다.
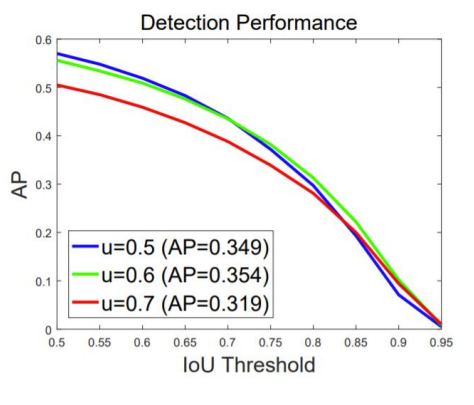
- Input IoU가 높을 수록 높은 IoU threshold에서 학습된 모델이 더 좋은 결과를 내었다.
- 전반적인 AP의 경우에는 IoU threshold 0.5로 학습된 것이 성능이 제일 좋았다.
- AP의 IoU threshold가 높아질수록 IoU threshold가 0.6,0.7로 학습된 것이 성능이 좋다.
- high quality detection을 수행하기 위해선 IoU threshold를 높여서 학습할 필요가 있었다.
- 성능하락의 문제가 있었기 때문에 Casecade RCNN이 나왔다.
Method
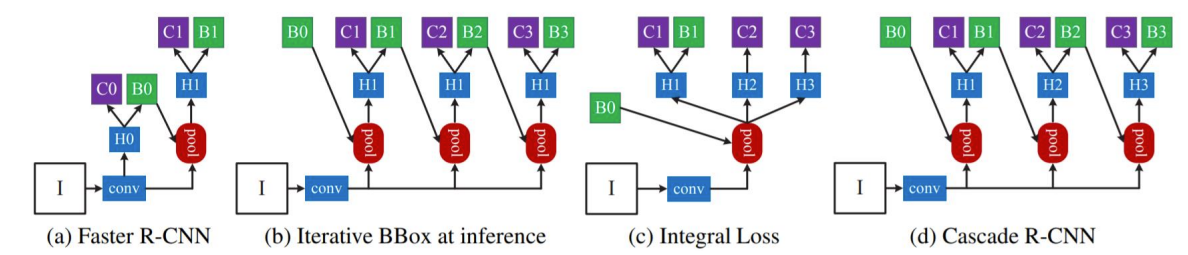
(b)와(c)를 활용하여 (d)를 만들었다.
- 여러 개의 RoI head(H1,H2,H3)를 학습했다.
- Head 별로 IoU threshold를 다르게 작성했다.
- 최종 결과로 , 가 나왔다.
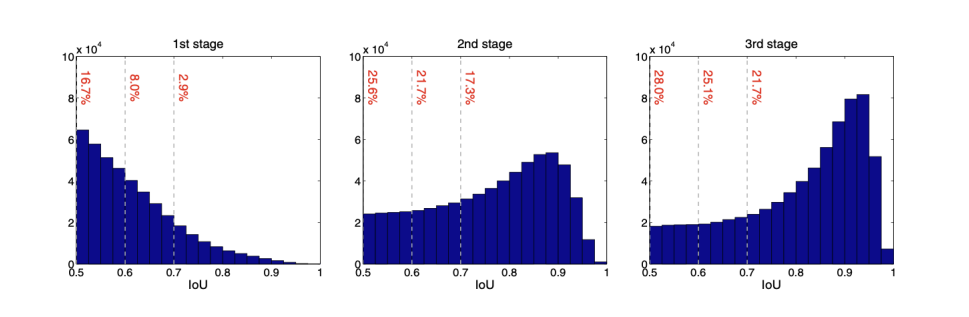
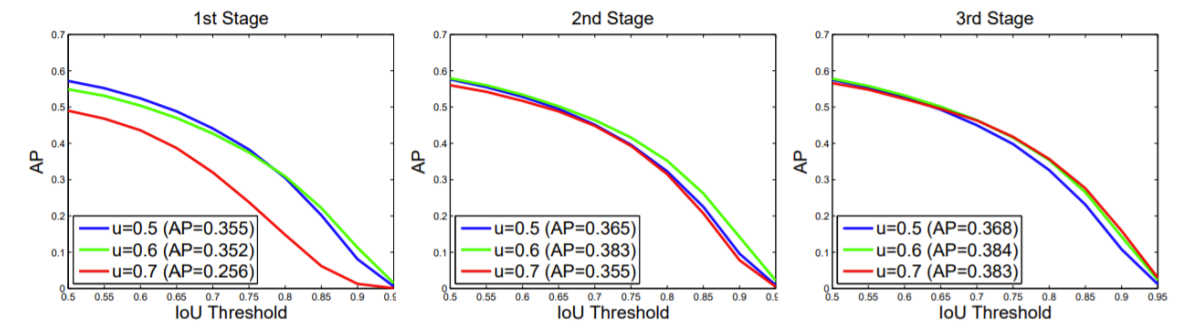
- bbox pooling을 반복수행할수록 성능이 향상된다.
- IoU threshold가 다른 Classifier가 반복될 때 성능이 향상된다.
- IoU threshold가 다른 RoI head를 cascade로 쌓을 때 성능이 향상된다.
Deformable Convolutional Networks(DCN)
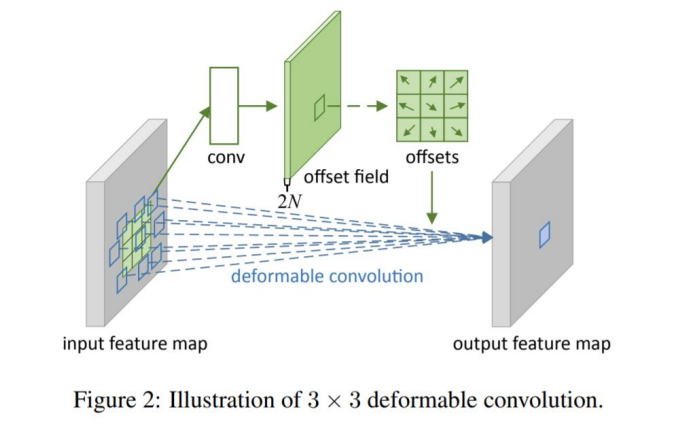
일정한 패턴을 지닌 Conv가 geometric transformations에 한계가 있기 때문에 DCN이 등장했다.
Methods
- offset을 추가해서 연산을 진행한다.
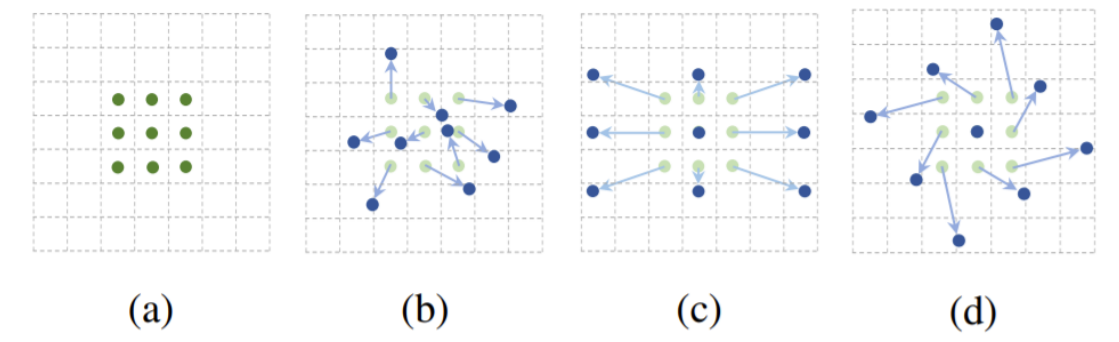

배경과 작은객체 큰 객체를 서로 비교한다.

- 일정한 패턴을 지닌 convolution neural networks는 geometric transformations에 한계를 파악했고 offset을 학습시켜 위치를 유동적으로 변화시키는 쪽으로 발전했다.
- 주로 object detection과 segmentation에서 좋은 효과를 나타내었다.
End-to-End Object Detection with Transformer(DETR)
Transformer를 처음으로 Object Detection분야에 적용시켰다.
- 기존의 Object Detection의 NMS같은 hand-crafted post process 단계를 transformer를 이용하여 없앴다.
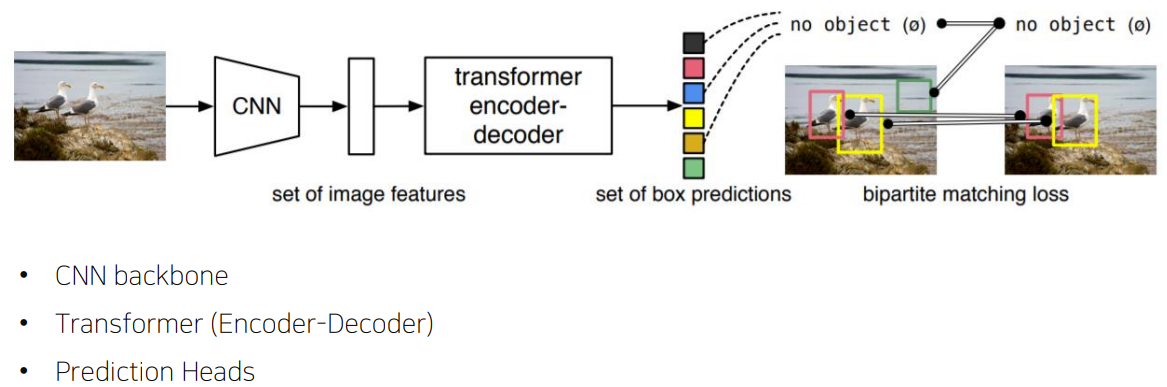
Neck 구조는 없다.
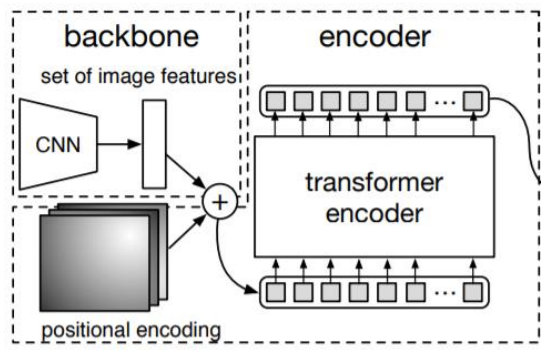
- Transformer 특성상 많은 연산이 필요하고 highest level feature map만 사용한다.
- Flatten 2D
- Positional embedding
- Encoder
Backbone
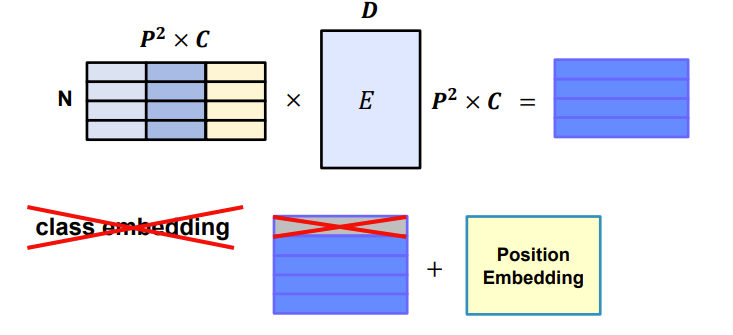
- 224x224 크기의 입력 사이즈를 받는다.
- 7x7 feature map size를 가진다.
- 49개의 feature vector를 encoder 입력값으로 사용한다.
Decoder
Encoder에서 나온 벡터를 Decoder에 넣는다. 이때 Output vector의 word 개수를 정해야한다.
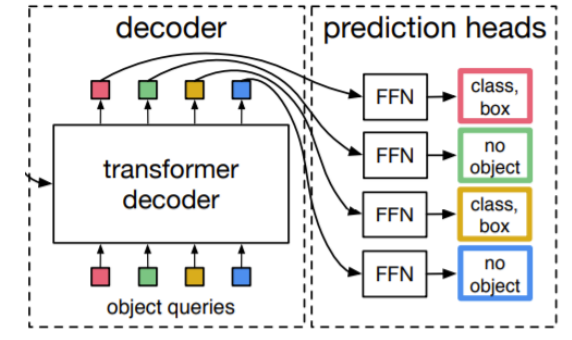
Train
- Ground Truth에서 부족한 object의 개수만큼 nan으로 padding 처리한다.
- Ground Truth와 Prediction이 N:N mapping이 되는 결과가 나온다.
- 각 예측값이 unique하게 나타나기 때문에 post-process과정이 필요없다.
Swin Transformer
ViT의 문제점
- 많은 양의 Data를 학습해야만 성능이 나온다.
- Transformer 특성상 computational cost가 크다.
- 일반적인 backbone으로 사용하기 어렵다.
-> CNN과 유사한 구조로 설계하고 cost를 줄이기 위해 window 개념을 사용했다.
Architecture
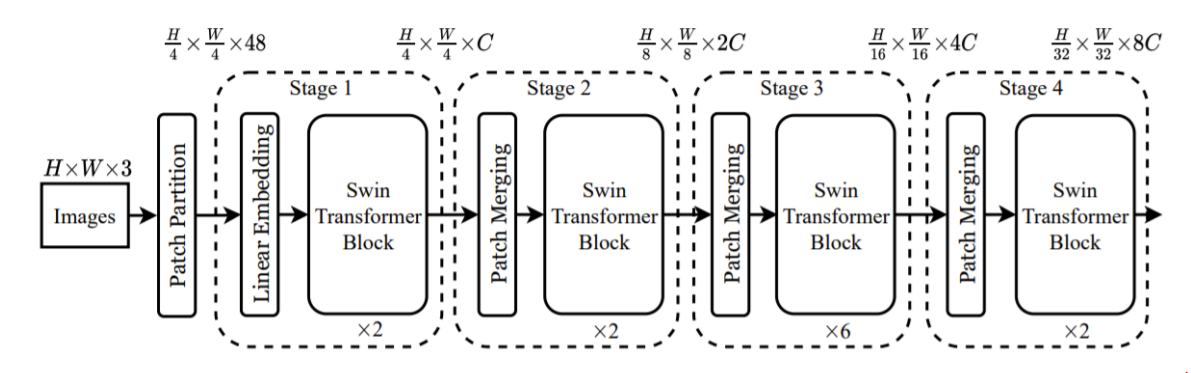
transformer를 N개로 나눠서 stage별로 transformer를 수행했다. feature map 사이즈를 줄여주었다.
- Patch Partitioning
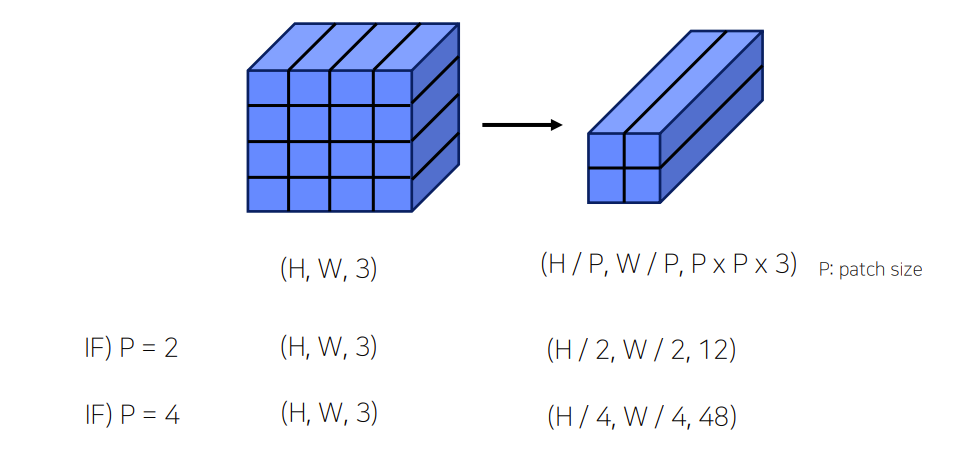
- Linear Embedding
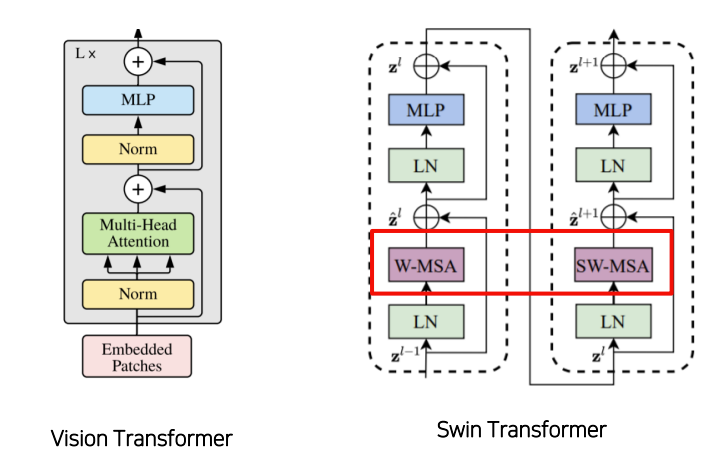
- Swin Transformer Block
2번의 Attention이 하나의 Transformer로 묶인다.
ViT느 Multi Head Attention을 사용하는 반면 Swin은 Window Multihead Self Attention과 Shifted Window Multihead Attention을 사용한다.
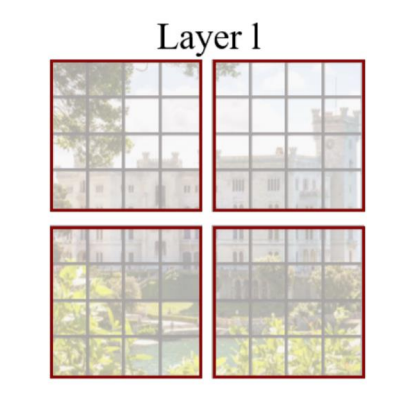
- Window Multihead Attention
- window 단위로 embedding을 나눈다.
- 기존 ViT같은 경우 모든 embedding을 Transformer에 입력한다.
- Swin Transformer는 window 안에서만 Transformer 연산을 수행한다.
- 이미지 크기에 따라 증가되던 computational cost가 window 크기에 따라 조절이 가능하다.
- receptive field가 제한된다는 단점이 존재한다.
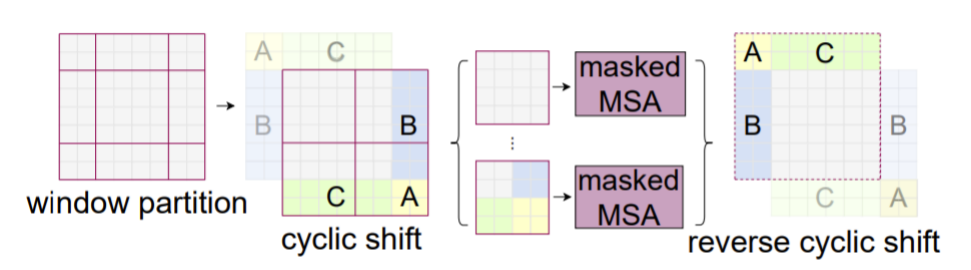
shifted window multihead attention은 window multihead attention의 단점ㅇ르 보완하기위해 w,h방향으로 shift하여 다시 연산을 진행한다. 이렇게 해서 receptive field가 다양해지는 효과를 기대할 수 있지만 가장자리에 window 조각들이 생기는 단점이 발생한다.
그렇기 때문에 남는 부분을 masking 처리하여 self-attention 연산이 되지 않도록 한다.
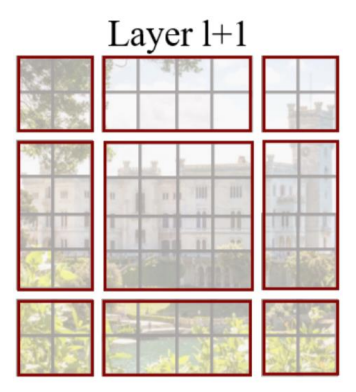
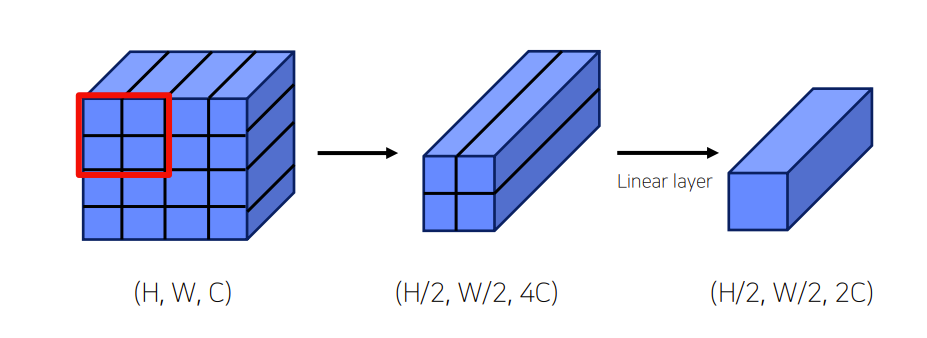
- Patch Merging
Summary
- 적은 데이터에도 학습을 잘 한다.
- window를 사용하여 computation cost를 줄였다.
- Object detection, segmentation 등의 backbone으로 활용된다.
