[Point Review] HyperDet3D: Learning a Scene-conditioned 3D Object Detector
Contribution
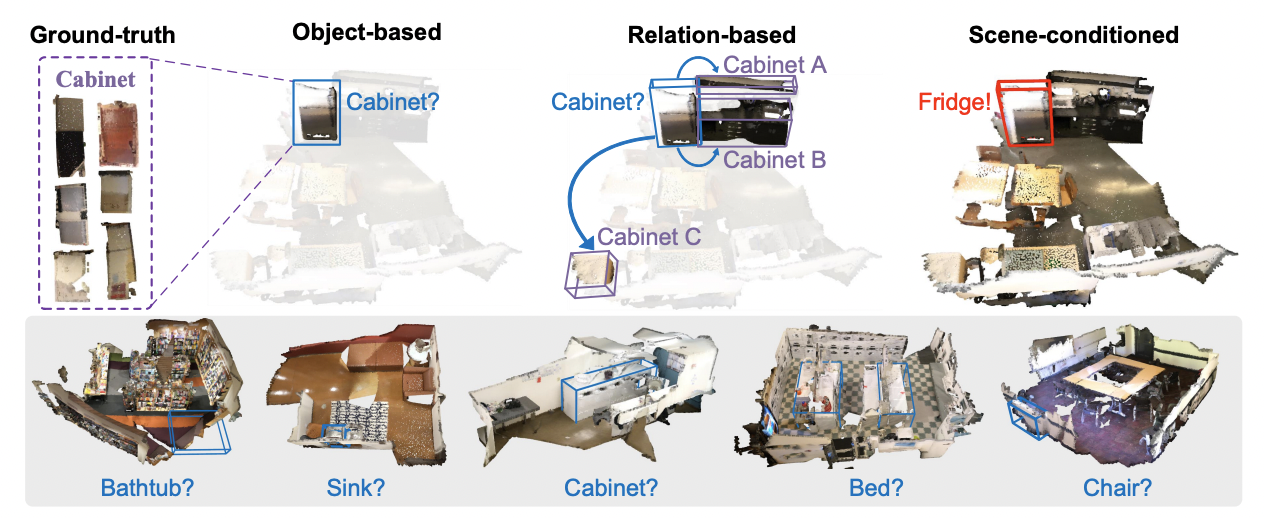
- 기존의 point cloud 3D object detection은 2D plane에 투영시켜 2D detector를 적용하는 view-based methods와 3D convolution을 적용하는 volumetric convolution-based methods를 활용해왔다.
- 이러한 방법들은 object 혹은 relation만을 강조하지만 유사한 특성을 가지는 object들을 판별하기 어려운 경우가 있다.
-> "scene-level 정보를 prior로 주어 ambiguity를 제거하자"
Methods
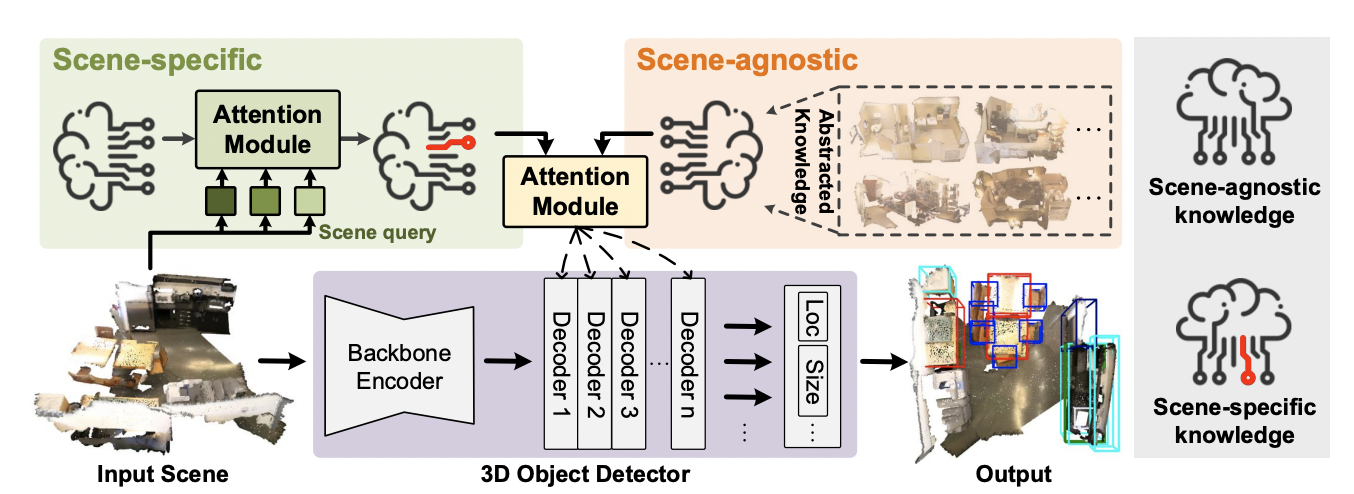
Overview
- HyperDet3D는 backbone encoder, object decoder layer, detection head로 이루어진다.
- Backbone은 PointNet++을 사용했으며 input인 denese point cloud를 initial object candidates로 downsampling 하며 feature를 추출한다.
- Object decoder layer에서는 scene-conditioned prior knowledge를 활용해 candidate features를 refine 한다.
- Detection head에서는 bounding box를 regression한다.
Scene-Conditioned HyperNetworks
- HyperNetwork는 다른 네트워크에 사용하기 위한 parameter를 학습하는 네트워크로 learnable embedding z 혹은 intermediate features x를 받아 learnable parameters W를 얻는다.
W=H(z)
- 또한, HyperNetwork는 test 시에 input에 따라 learnable parameter가 변형되어 scene-specific하게 적용할 수 있다.
- 본 논문에서는 object candidate의 feature representation o를 받아 scene-level 정보를 주고자 한다.
o^=Wo+b
- Scene-Agnostic HyperNetwork에서는 scene에 대한 embedding vector Zs를 hypernetwork hθs에 통과시켜 scene-agnostic knowledge Wa를 얻는다.
- Scene-Specific HyperNetwork에서는 input scene Pi를 query로 활용해 attention mechanism을 통해 zws를 매칭시킨다.
- 두 HyperNetWork에서 얻은 Ws와 Wa는 element-wise multiplication 하여 활용한다.
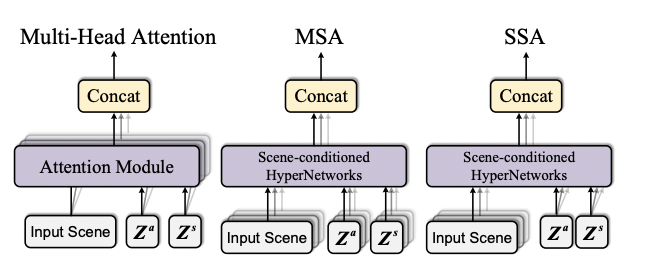
- 기존의 multi-head attention에서는 여러 개의 parallel한 attention module을 활용하지만 본 논문에서는 target weight W가 input의 영향을 받으므로 Za,Zs를 reinitialize하여 여러번 사용한다.
Disentangled Detection Head
- Offset(△pi)을 regression하여 center ci를 학습하는 기존의 방법과 달리 Dientangled variant of Detection Head(DDH)를 제안한다.
- Offset을 2개의 branch로 나눠 하나는 길이 r을, 다른 하나는 orientation(quaternion)을 나타내는 4차원 vector를 regression 한다.
Results
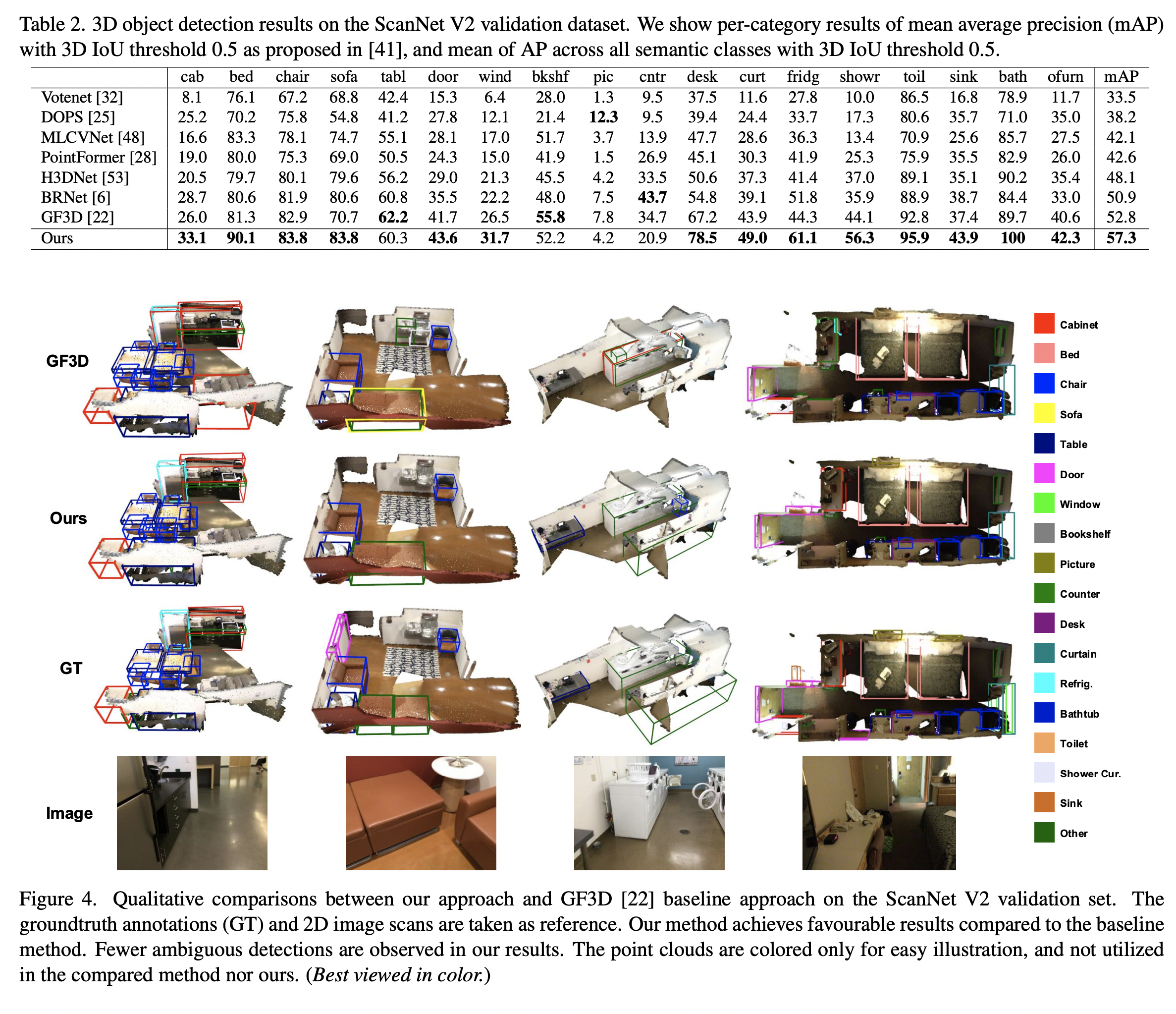
Reference
