[Point Review] OmniFusion: 360 Monocular Depth Estimation via Geometry-Aware Fusion
Point Review
목록 보기
12/26
Baseline
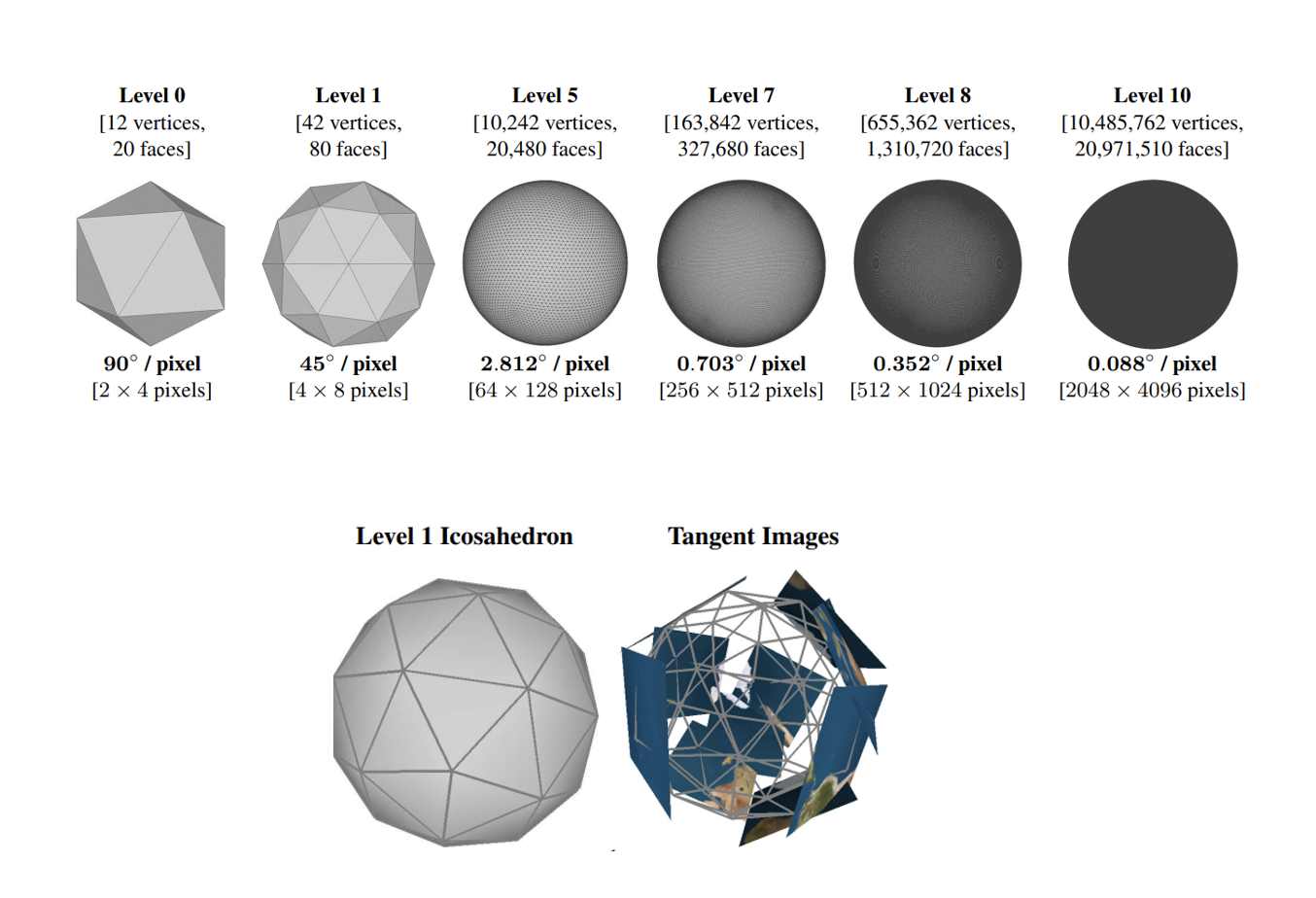
- ERP에서는 왜곡이 심하기 때문에 구면에서의 tangent 이미지를 활용하는 방법이 "Tangent images for mitigating spherical distortion"에서 소개되었다.
- Face의 개수는 level에 따라 달라지며 level이 너무 낮을 경우 왜곡 보정이 잘 안되며 level이 너무 높을 경우 연산량이 크다는 trade-off가 있기 때문에 일반적으로 level-5를 주로 사용한다.
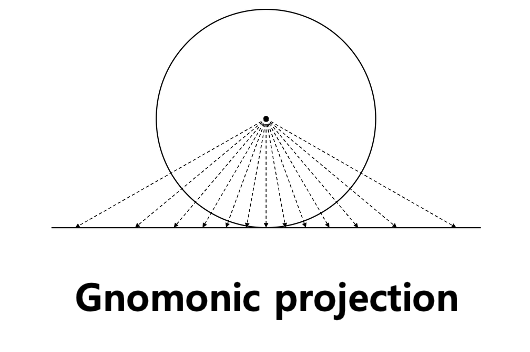
- Tangent image를 만들기 위해서는 해시계 투영법(Gnomonic projection)을 활용한다.
- 구의 원점으로부터 tanget plane으로 뻗어나가는 직선에 걸치는 구면의 픽셀이 투영된다고 볼 수 있다.
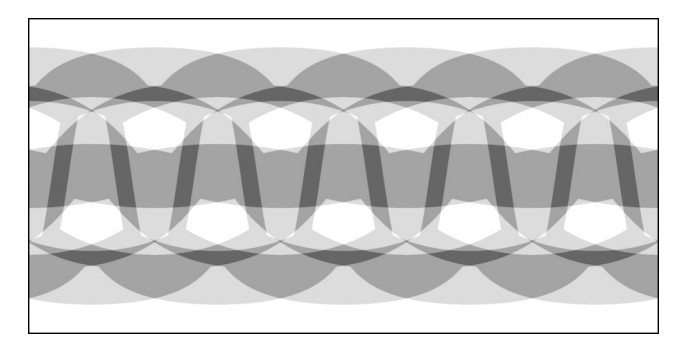
- "360MonoDepth: High-Resolution 360° Monocular Depth Estimation"에서는 tangent plane을 활용한 depth estimation을 제안하는데 겹치는 영역에 대해서는 평균값을 활용한다.
- 위 그림에서 가장 어두운 영역은 2개의 image가 겹치는 부분이고, 가장 밝은 영역은 5개의 이미지가 겹치는 영역이다.(이 논문에서는 20개의 tangent image를 사용한다.)
- 극에 가까울수록 영역이 좁기 때문에 많은 이미지가 겹친다.
Methods
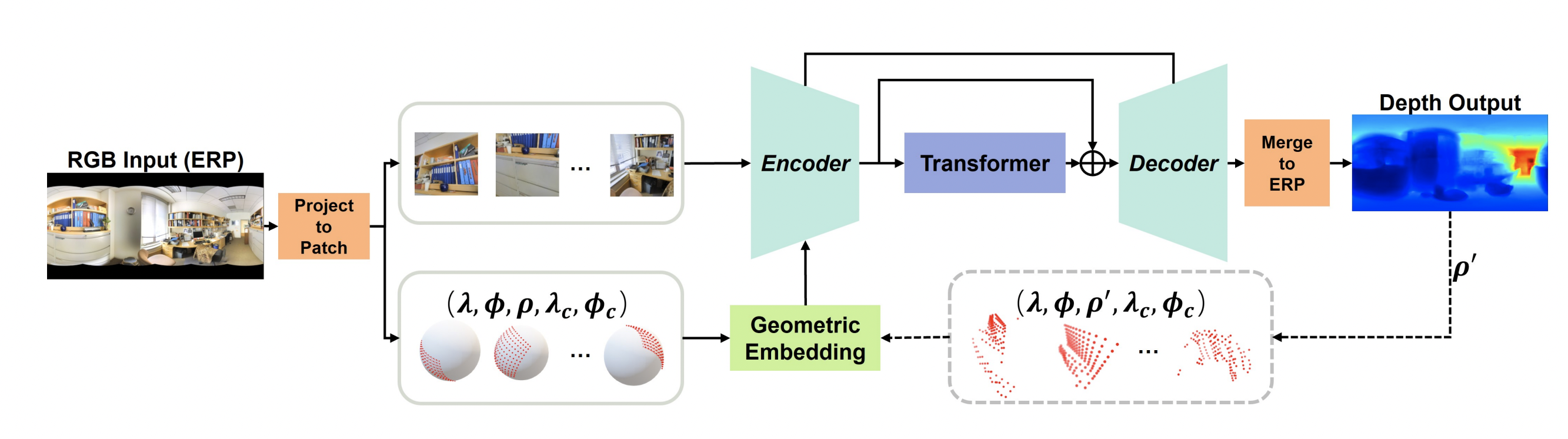
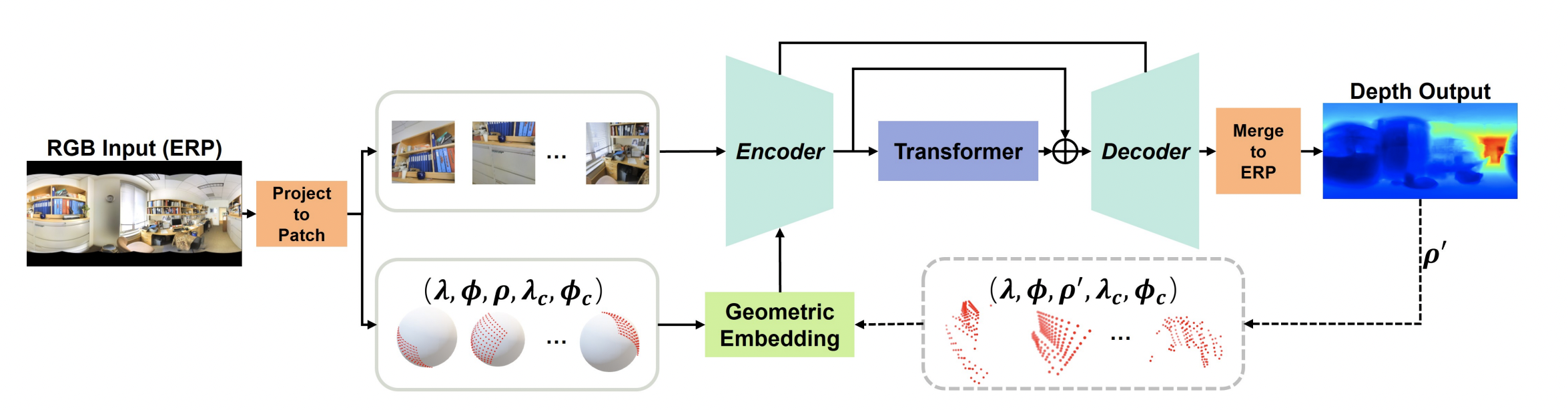
- 극으로 갈 수록 tangent image가 많이 겹치므로 3,6,6,3의 총 18개의 patch를 만든다.
- 각 path는 geometric embedding과 함께 encoder로 들어간다.
- Decoder를 통해 각 패치의 depth가 나오며 baseline에서 소개했던 방식으로 merge 한다.
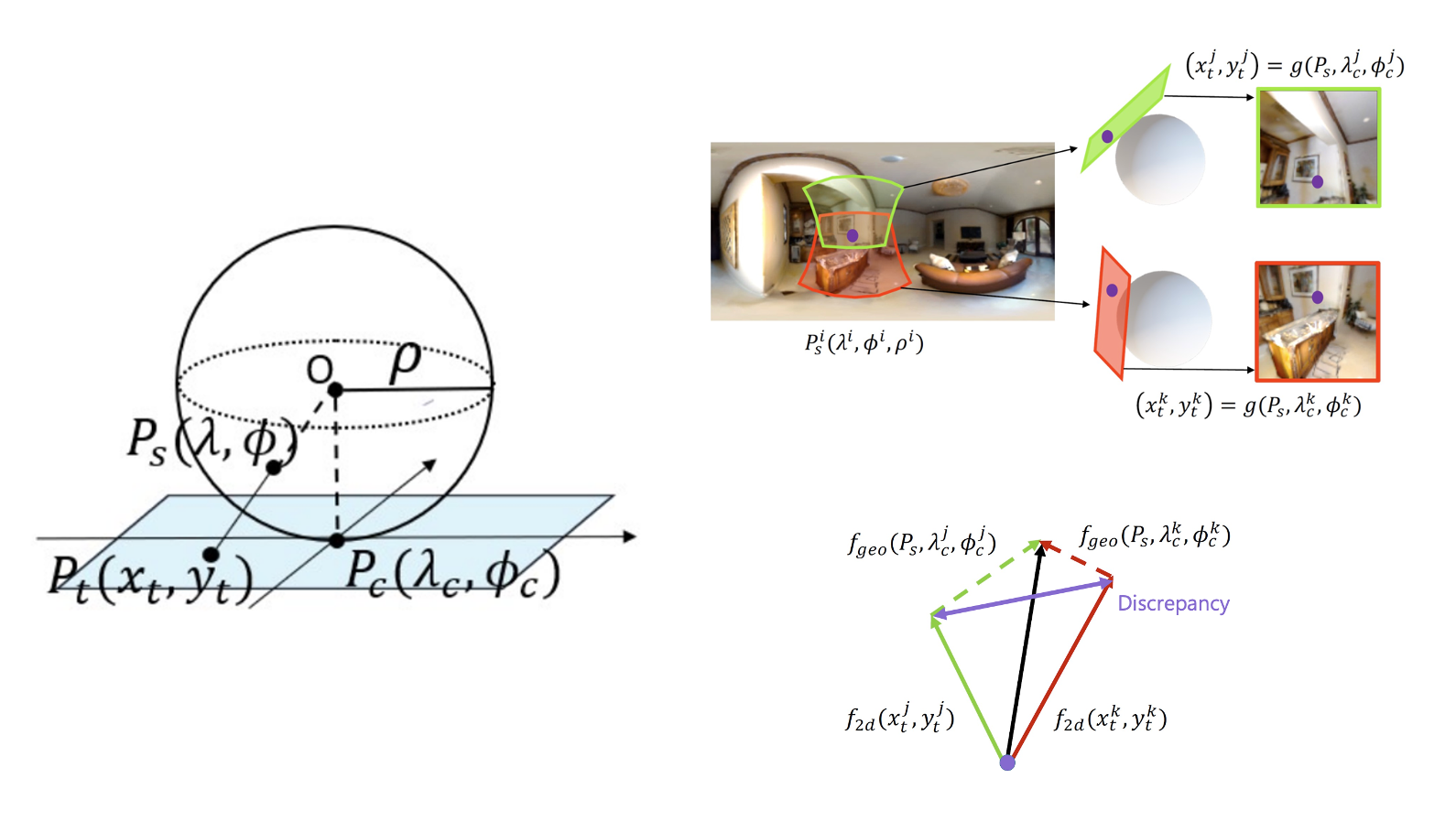
- Geometric한 정보를 넣어주기 위해 로 구성된 embedding을 만들어주며 픽셀별 위경도, 구의 반지름, path의 중심의 위경도를 의미한다.
- Geometric embedding은 2개의 tangent image에서 보이는 구면 상 하나의 point가 고차원의 feature space로 갈 때 서로 멀어지는 것을 방지하는 역할을 한다.
- 1st iteration에서는 각 patch들이 독립적이므로 geometric feature가 고정되어 있으며 2nd iteration에서는 update 된다.
- 는 focal length로 depth와 비례하며 1st iteration에서는 1로 고정값을 둔다.
