[Point Review] PixelSynth: Generating a 3D-Consistent Experience from a Single Image
Point Review
목록 보기
6/26
Contribution
single-image scene synthesis에서의 key challenge는
- large view change를 extrapolation을 통해 잘 나타내는 것
- 여러 view에서의 output이 consistency를 가지는 것
- 3D-awareness(depth에 따라 view가 변할 때 움직이는 정도가 다르기 때문)
-> VQVAE를 활용해 크게 변한 support set을 생성한 뒤 projection하여 그 사이의 view들을 나타낸다.
Method
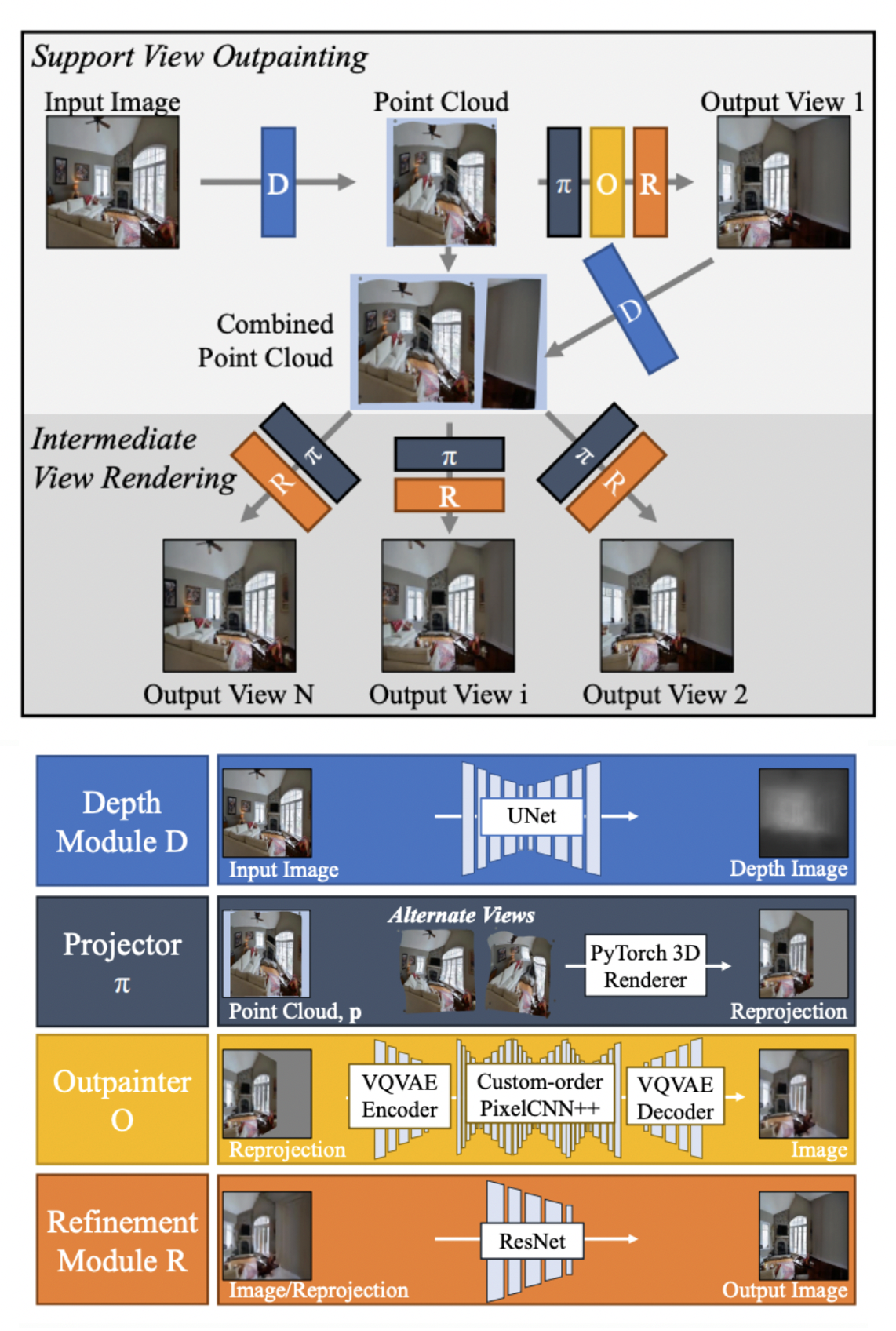
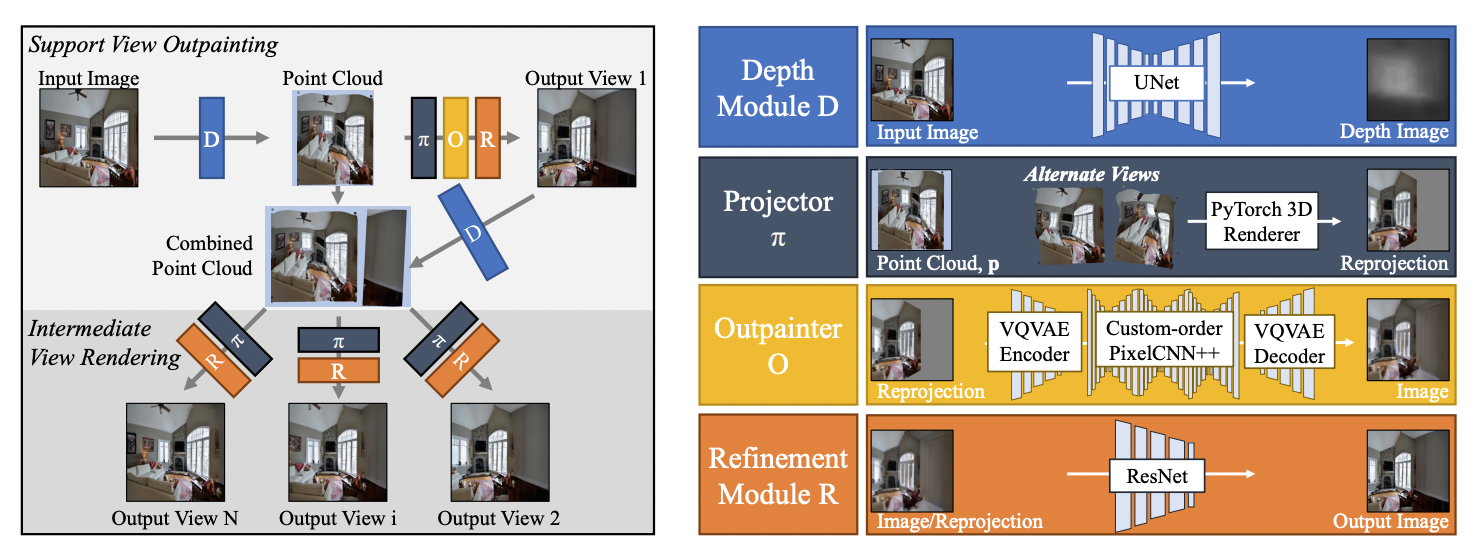
- input 이미지는 Depth module 을 통과시켜 ponit cloud 형태로 만들어준다.
- 이후 projection을 하고 빈 공간은 VQVAE를 통해 생성한 뒤 Refinement module 을 통해 부족한 디테일과 inconsistence들을 보완해준다.
- Output view1을 support set이라 칭하며 를 거쳐 input image와 combined된 point cloud를 얻는다.
- 확장된 정보를 얻었으므로 그 사이에 있는 view들은 projector 와 을 통해 얻을 수 있다.
Results

