Contributions
-
FC layer에서 고정된 크기의 이미지가 필요한데 crop, warp 과정에서 손실이 있음
-> Spatial Pyramid Pooling을 통해 피쳐맵들을 동일한 크기로 조절
- R-CNN에서는이미지마다 selective search를 통해 2000개의 ROI를 생성하여 전부 CNN을 적용하여 시간이 오래 걸림
-> 전체 이미지를 CNN에 통과시켜 속도 향상
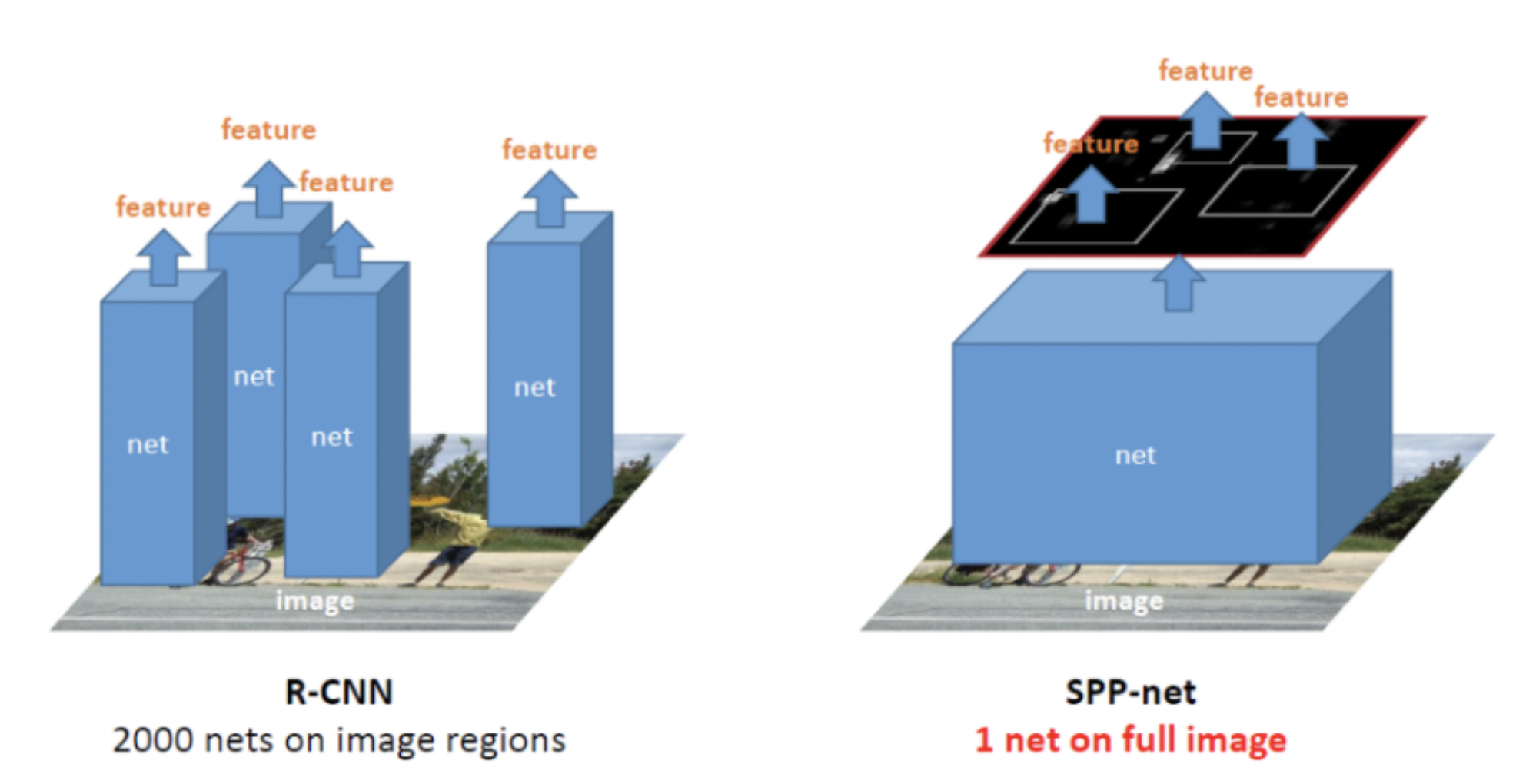
Process
- 이미지를 CNN에 통과시켜 feature map을 얻는다.
- Selective search 통해 얻은 ROI들을 SPP layer에 통과시켜 고정된 특징 벡터를 추출한다.
- 특징벡터를 FC layer에 전달한다.
- SVM으로 Classification 수행
- Box regression으로 box 위치 및 크기 조정
Spatial Pyramid Pooling
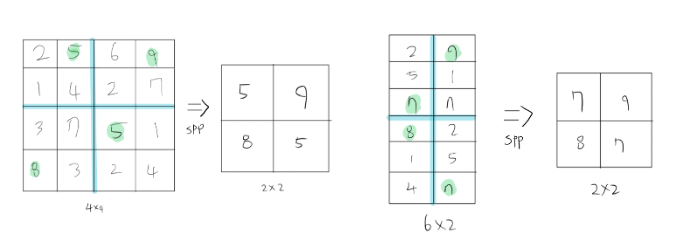
SPP의 원리는 위와 같다. 각기 다른 비율과 크기의 ROI를 Max pooling을 통해 고정된 크기의 벡터로 만든다.
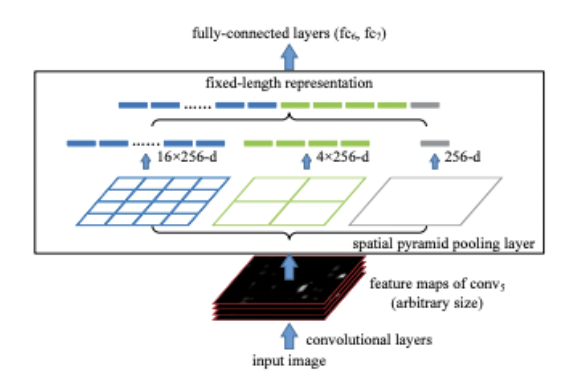
위의 예시에서는 4x4, 2x2, 1x1의 맥스풀링 필터가 있다. 다양한 필터로 여러 영역을 볼 수 있기 때문에 피라미드 구조를 지닌다고 할 수 있으며 64x64의 feature map이 들어온다면 4x4 필터에서 bin의 크기는 16x16가 될 것이다. output으로 나온 벡터는 1차원으로 만들어 FC layer로 들어간다.
