Redis
면접 회고를 목적으로 몰랐던 개념을(모르고리즘 시리즈와는 별개로) 망했어요 시리즈로 한 번 정리해보도록 하지
(하기 내용은 우아한 테크 세미나 강의를 보고 따라 정리함)
[우아한테크세미나] 191121 우아한레디스 by 강대명님
Redis 소개
- In-Memory Data Structure Store : 프로세스로 존재
- Open Source(BSD 3 License) : 공개하지 않고, 수정해서 쓸 수 있다
- Support data structures
- Strings, set, sorted-set, hashes, list
- Hyperloglog, bitmap, heospatial index
- Stream
- only 1 Committer
Cache
-
Cache를 왜 쓰나?
- 나중에 요청올 결과를 미리 저장해두었다가 빠르게 서비스를 해주는 것을 의미
-
Factorial
- 다이나믹 프로그램 : 앞의 연산을 미리 저장해 놓고 다음 번에 똑같은 연산을 하지 말자
- 캐쉬의 목적!
-
접근 속도가 다를 때
- CPU Cache
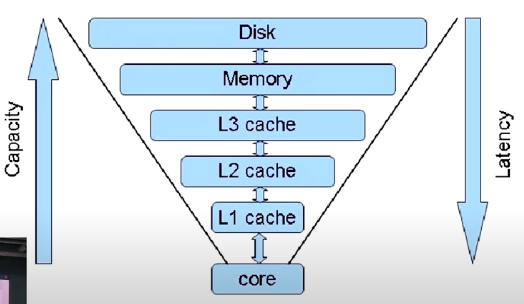
- 용량은 위로 갈 수록 커지고 속도는 아래로 갈수록 빨라짐
- Redis는 Memory에 있음
- 디스크 접근 속도가 메모리에 비하면 큰 차이가 남
- 메모리에 올려놓고 쓰는 것이 디스크에서 읽어 오는 것보다 훨씬 빠르다
- 용량은 디스크가 더 크다
-
어디서 많이 사용하나?
- 추상적인 웹서비스 구조 Client → webserver(API) → DB(DB 안에는 많은 ㄷ이터들이 있고, 이 때 주로 디스크에 내용이 저장) DB도 내부적으로 캐시가 있다. 메모리 사이즈보다 크면 디스크를 사용.
- 추상적인 웹서비스 구조 Client → webserver(API) → DB(DB 안에는 많은 ㄷ이터들이 있고, 이 때 주로 디스크에 내용이 저장) DB도 내부적으로 캐시가 있다. 메모리 사이즈보다 크면 디스크를 사용.
-
파레토 법칙
- 우리 사회에서 일어나는 현상의 80%는 20%의 원인으로 인하여 발생한다
- 전체 요청의 80%는 20%의 사용자 → 적은 메모리이지만 효율적으로 캐싱으로 할 수 있는 이유!
-
Cashe 구조
- Look aside Cache
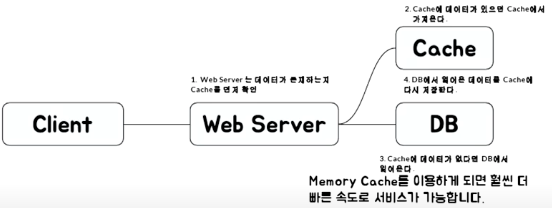
- Write Back
인메모리가 쓰기나 읽기가 빠름. 쓰기가 빈번한 것은 디스크에 저장을 해야 하는데, 일단 캐시에 먼저 저장해두었다가 특정 시점마다 db에 저장함 예를 들어, insert query를 한 번씩 500번 날리는 것과, 500개 붙인 것을 한번 날리는 것 중 어느것이 더 빠를까? 후자가 훨씬 빠르다!
단점 : 메모리에 저장 되어 있기 때문에, 리부팅 되면 데이터가 사라질 수 있다 로그를 캐쉬에 넣어 놨다가 특정 주기에 한번에 db에 저장함
- Look aside Cache
-
왜 Collection이 중요한가?
- 개발의 편의성
- 파이썬 생산성이 높은 이유 : 제공해주는 라이브러리가 많다 기본적인 자료구조
- redis도 만들어 진 것을 가져다 쓸 수 있음
- 랭킹 서버를 직접 구현한다면?
- 가장 간단한 방법 : DB 유저의 score를 저장하고 score를 order by로 정렬 후 읽어오기 → 개수가 많아지면 속도에 문제가 발생할 수 있음(결국 디스크를 사용하기 때문)
- In-Memory 기준으로 랭킹 서버의 기준으로 랭킹 서버의 구현이 필요함
- Redis의 Sorted Set을 이용! → Replication도 가능
- 가장 간단한 방법 : DB 유저의 score를 저장하고 score를 order by로 정렬 후 읽어오기 → 개수가 많아지면 속도에 문제가 발생할 수 있음(결국 디스크를 사용하기 때문)
- 개발의 난이도
- 친구 리스트를 관리 해보자(Race Condition)
- 친구 리스트를 key / value 형태로 저장해야 한다면?
-
현재 유저 123의 친구 key는 friends : 123, 현재 친구 A가 있는 중
GOOD
시간순서 T1(친구 B 추가) T2(친구 C 추가) 최종상태 1 friends:123 읽기 A 2 친구 B 추가 A 3 friends:123 쓰기 A, B 4 friends:123 읽기 A, B 5 친구 C 추가 A, B 6 friends:123 쓰기 A, B, C HOW?
시간순서 T1(친구 B 추가) T2(친구 C 추가) 최종상태 1 friends:123 읽기 A 2 friends:123 읽기 A 3 친구 B 추가 A 4 친구 C 추가 A 5 friends:123 쓰기 A, B 6 friends:123 쓰기 A, C HOW?
시간순서 T1(친구 B 추가) T2(친구 C 추가) 최종상태 1 friends:123 읽기 A 2 friends:123 읽기 A 3 친구 B 추가 A 4 친구 C 추가 A 5 friends:123 쓰기 A, C 6 friends:123 쓰기 A, B Context Switching 때문에 T1, T2가 어떻게 일어날지 모름
-
- 친구 리스트를 key / value 형태로 저장해야 한다면?
- Redis의 경우는 자료구조가 Atomic 하기 때문에, 해당 Race Condition을 피할 수 있다 그래도 잘못 짜면 발생한다 예) 따닥 (고급용엌ㅋㅋㅋㅋ)
- 친구 리스트를 관리 해보자(Race Condition)
- 외부의 Collection을 잘 이용하는 것으로, 여러가지 개발 시간을 단축시키고, 문제를 줄여줌
- 개발의 편의성
-
Redis는 어디서 사용하는가?
- Remote Data Store
- A서버, B서버, C서버에서 데이터를 공유하고 싶을 때
- 한대에서만 필요하면 전역 변수를 쓰면 되지 않을까?
- Redis 자체가 Atomic을 보장해준다(싱글 스레드라...)
- 주로 많이 쓰는 곳들
- 인증 토큰(string 또는 hash)
- Rangking 보드로 사용(Sorted Set)
- 유저 API Limit
- 잡 큐(list)?????
- Remote Data Store
-
Redis Collections
자료 구조 선택이 중요한 이유 : Big O
→ 서비스 속도!
→ O(1), O(n)
-
Strings (key/value) : 단일 key, 멀티 key
- Set
Set token:1234567 askdljfkl;asjdfl
- Get
Get token:1234567
- mset ...............
Mset token:1234567 asdjkfjask;djf email:1234567 lilo@gmail.com
- mget ..........
Mget goken:1234567 email:1234567
- prefix를 붙일 때 앞으로 붙일 수도 있고, 뒤에다가 붙일 수도 있음 → 분산이 바뀔 수 있다
insert into users(name, email) values(’lilo’, ‘lilo@gmail.com’);- Using Set
Set name:lilo liloSet email:lilo lilo@gmail.com
- Using mset
Mset name:lilo lilo email:lilo lilo@gmail.com
- Using Set
- Set
-
List (앞이나 뒤에 데이터를 넣는 것은 빠르지만 중간에 삽입하는 경우는 list를 쓰면 안된다)
-
Lpush
<key> <A>- key : (A)
-
Rpush
<key> <B>- key : (A, B)
-
Lpush
<key> <C>- key : (C, A, B)
-
Rpush
<key> <D, A>- key : (C, A, B, D, A)
key : (C, A, B, D, A)
-
LPOP
<key>- Pop C, Key : (A, B, D, A)
-
RPOP
<key>- Pop A, Key : (A, B, D)
-
RPOP
<key>- Pop D, Key : (A, B)
-
-
Set (중복된 데이터를 넣지 않을 때, 찾는 건 빠름)
- SADD
<Key> <Value>- Value가 이미 Key에 있으면 추가되지 앟는다
- SMEMBERS
<key>- 모든 Value를 돌려줌
- 100만게 다 가져온다 조심
- SISMEMVER
<key> <value>- value가 존재하면 1, 없으면 0
- 특정 유저의 친구리스트, 팔로우 목록 (unique 한 것들)
- 특정 유저를 Follow 하는 목록을 저장해둔다면
- SADD
-
Sorted Set (순서를 보장함, score 순으로 정렬 가능)
- 제일 많이 쓴다
- ZADD
<Key> <Score> <Value>- score값으로 정렬되서 저장된다(ascending)
- Value가 이미 key에 있으면 해당 Score로 변경된다
- ZRANGE
<Key> <StartIndex> <EndIndex>- 해당 Index 범위 값을 모두 돌려줌
- Zrange testkey 0-1
- (인덱스로 표현)
- 모든 범위를 가져옴
- 정렬
select * from rank order by score limit 50, 20;→zrange rank 50 70select * from rank order by score desc limit 50, 20;→zrevrange rank 50 70
- score 기준
select * from rank where score >= 70 and score <100;→ zrangebyscore rank 70 100`select * from rank where score > 70;→zrangebyscore rank (70+inf
- 유저 랭킹보드로 사용
- 주의!!! score는 정수가 아니고 double 실수형이다. 실수가 표현할 수 없는 정수값들이 존재
-
Hash
-
Key 밑에 sub key가 존재
-
Hmset
<key> <subkey1> <value1> <subkey2> <value2> -
Hgetall
<key>- 해당 key의 모든 subkey와 value를 가져옴
-
Hget
<key> <subkey> -
Hmget
<key> <subkey1> <subkey2> ........ <subkeyN>Insert into users(name, email) values('lilo', 'lilo@gmail.com');→
hmset lilo name lilo email lilo@gmail.com
-
-
COLLECTION 주의 사항
- 하나의 컬렉션에 너무 많은 아이템을 담으면 좋지 않다
- 1000개 이하 몇 천개 수준으로 유지하는 것이 좋음
- Expire는 Collection의 item 개별로 걸리지 않고 전체 Collection에 대해서만 걸림
- 즉 해당 10000개의 아이템을 가진 Collectiondp expire 가 걸려있다면 그 시간 후에 10000개 아이템이 모두 삭제
- 하나의 컬렉션에 너무 많은 아이템을 담으면 좋지 않다
-
Redis 운영
-
메모리 관리를 잘하자
-
Redis가 메모리를 많이 쓰면 open the hellgate
-
Redis는 In-Memory Data Store
-
Physical Memory 이상을 사용하면 문제가 발생
- Swap이 있다면 Swap 사용으로 해당 메모리 Page 접근시 마다 늦어짐 메모리 페이지를 디스크에 저장해두고 필요하면 다시 로딩하는 것 Swap이 한 번이라도 발생한 메모리 페이지는 계속 발생, 그 메모리 페이지에 접근해야 하는 key가 있으면 그 key를 접근 할 때마다 디스크를 읽고 쓴다 → 성능 떨어짐 Redis를 쓰는 이유는 인메모리라서 쓰는데, 디스크를 쓰게 되는 순간부터 느려짐
- Swap이 있다면 Swap 사용으로 해당 메모리 Page 접근시 마다 늦어짐 메모리 페이지를 디스크에 저장해두고 필요하면 다시 로딩하는 것 Swap이 한 번이라도 발생한 메모리 페이지는 계속 발생, 그 메모리 페이지에 접근해야 하는 key가 있으면 그 key를 접근 할 때마다 디스크를 읽고 쓴다 → 성능 떨어짐 Redis를 쓰는 이유는 인메모리라서 쓰는데, 디스크를 쓰게 되는 순간부터 느려짐
-
Maxmemory를 설정하더라도 이보다 더 사용할 가능성이 큼 → 메모리 관리 필요
메모리 allocator에 의존해서 사용하는데, memory allocator의 구현에 따라서 성능이 왔다갔다 함
memory allocator가 지웠다고 하지만 memory를 가지고 있을 때도 있음
Redis가 자기가 사용하는 memory를 잘 모름(메모리 파편화)
→ jemlloc에 힌트를 주는 기능이 있으나, 버전에 따라서 다르게 동작 할 수 있음
-
많은 업체가 현제 메모리를 사용해서 Swap을 쓰고 있다는 것을 모를때가 많음
-
큰 메모리를 사용하는 instance 하나 보다는 적은 메모리를 사용하는 instance 여러 개가 안전함
→ fork를 할 때 read만 많으면 상관없는데 write가 heavy한 Redis는 메모리를 복사 할 때(copy on wright) 최대 두 배까지 쓸 수 있음
-
메모리가 부족할 떄는?
- Cache is CASH!!!
- 좀 더 메모리 많은 장비로 Migration
- 메모리가 빡빡 하면 migration 중에 문제 발생할 수도 있음
- fork 할 때,,,,
- 75% 정도 쓸 때 옮기는 걸 고민해야함
- 있는 데이터 줄이기
- 데이터를 일정 수준에서만 사용하도록 특정 데이터를 줄임
- 기본적으로 Collection들은 다음과 같은 자료구조를 사용
- Hash → Hash Table을 하나 더 사용
- Sorted Set → Skiplist와 Hash Table을 이용
- Set → Hash Table 사용
- 해당 자료구조들은 메모리를 많이 사용함
- Ziplist를 이용하자(선형으로 저장함)
- 속도는 느려지지만 메모리는 훨씬 적게 사용함(20-30% 차이남)
- 많이 쓰면 원래의 자료구조로 돌아감
- 자료구조를 저장 할 때 내부적으로 ziplist로 대체해서 저장하도록 설정만 바꿔주면 된다
- In-Memory 특성상, 적은 개수라면 선형 탐색을 하더라도 빠르다 적당한 사이즈까지는 꼭 특정 알고리즘 안 쓰고 full search 하더라도 굉장히 빠름
zlbytes zltail zllen entry ... entry zlend
- Cache is CASH!!!
-
-
O(N) 관련 명령어는 주의하자
-
Redis는 싱글 뜨레드
- Redis가 동시에 여러 개의 명령을 처리할 수 있을까? 한 번에 하나!
- 한번에 하나의 명령만 수행 가능하기 때문에 긴 시간이 필요한 명령을 수행하면 안됨
- 단순한 get/set의 경우, 초당 10만개 TPS 이상 가능(초당 10만개 처리)
-
만약에 하나가 1초 걸린다 → 99999개 명령은 1초 기다림
→ timeout * 99999개 → 서비스 폭발 → 망한다!!!
-
TCP에서 패킷이 끊어져서 들어오는데 processInputBuffer라는 곳에서 패킷을 하나의 command로 만들어서 커맨드가 완성됐는지 확인 → processCommand & reset이라는 것을 타고 들어오는데 그 때 완성된 커맨드 하나를 실행시키는 구조 → 처리되는 동안 뒤에 패킷은 쌓이고 있음 → 이 하나가 loop를 탈출해야 다른 명령 처리 가능
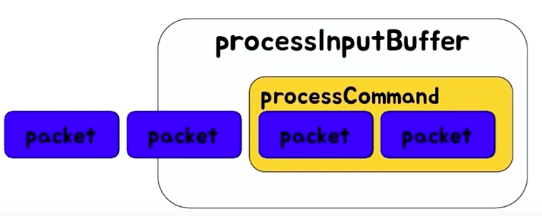
-
- 대표적인 O(N) 명령들
- KEYS : 모든 키를 순회하는 명령 → 각종 서버들이 exeption을 발생시키는 것을 볼 수 있음 → scan 명령을 사용하는 것으로 하나의 긴 명령을 짧은 여러 번의 명령으로 바꿀 수 있다
- FLUSHALL, FLUSHDB → 데이터 다 날리는 거
- 아이템이 몇 만개 든 hash, sorted set, set에서 모든 데이터 다 가져오는 경우 → Collection의 일부만 가져오거나(sorted set에 기능이 있음) → 큰 collection을 작은 여러개의 collection으로 나눠서 저장
- Userranks → Userrank1, Userrank2, Userrank3
- 하나당 몇 천개 안쪽으로 저장하는게 좋음
- Delete Collections → 백만개 지울 동안 아무것도 못함
- Get All Collections
- KEYS : 모든 키를 순회하는 명령 → 각종 서버들이 exeption을 발생시키는 것을 볼 수 있음 → scan 명령을 사용하는 것으로 하나의 긴 명령을 짧은 여러 번의 명령으로 바꿀 수 있다
-
-
Redis Replication
- Async Replication → Replication Lag이 발생할 수 있다
- A 데이터가 바뀌고 B 데이터가 바뀌는데 그 틈 사이에 데이터가 다를 수 있음
- master에는 데이터에 있고, slave에는 데이터가 없는 경우 있음
- ‘Replicaof’ or ‘slaveof’
- Replicaof hostname port
- Replication 설정 과정
- Secondary에 replicaof or slaveof 명령을 전달
- Secondary는 Primary에 sync 명령 전달
- Primary는 현재 메모리 상태를 저장하기 위해
- Fork : 메모리 부족이 발생할 수 있음
- Fork 한 프로세서는 현재 메모리 정보를 disk에 dump
- 해당정보를 secondary에 전달
- Fork 이후의 데이터를 secondary에 계속 전달
- Redis-cli —rdb 명령으로 dump 뜨다가 fork 되서 죽음 → 현재 상태의 메모리 스냅샷을 가져오므로 같은 문제 발생(fork)
- AWS 나 클라우드 Redis는 fork없이 replication 데이터 전달하는 방법이 있는데 느림
- 많은 대수의 Redis 서버가 Replica를 두고 있다면 네트워크 이슈나, 사람의 작업으로 동시에 replication이 재시도 되도록 하면 문제가 발생
-
redis.conf 권장설정 Tip
- Maxclient 설정 값을 늘린다
- RDB / AOF 설정 off → 성능상, 안전성
- 특정 commands disable
- Keys
- AWS의 ElasticCache는 이미 하고 있음
- 전체 장애의 90% 이상이 KEYS와 SAVE 설정(default)을 사용해서 발생
- SAVE : 1분안에 key가 만개가 바뀌었다 → 메모리 덤프해
- 적절한 ziplist 설정
Redis 데이터 분산
-
데이터의 특성에 따라서 선택할 수 있는 방법이 달라진다
- Cache
- Persistent(store) → open the hellgate
-
Application
-
modular server(id 값 % 서버갯수(n)의 값이 modular 번호)
서버가 꽉 찾음 → 서버 증설해야 함 → 서버 추가할 때마다 기존 데이터 움직임 → rebalancing 됨
서버가 죽었을 때/장애가 생겼을 때 → 또 rebalancing 생김
→ 장비가 늘어나거나 줄었을 때 발생할 수 있는 문제
-
Consistent Hashing
-
key 값을 해싱해서 나보다 크면서 가장 가까운 서버로 이동
(큰값이 없으면 가장 첫번째로)
예) 15000이 나오면 10000, 20000, 30000 서버 중에 20000으로 간다
→ 20000 서버가 죽었을 때 17500만 30000으로 이동하고 다른 데이터들은 그대로
→ 서버가 죽거나 증설했을 때 해당 서버의 데이터만 이동하면 됨
→ 1/n만큼만 움직인다 키의 해쉬 값이 해쉬가 일정하면 값이 일정하기 때문에 가능
-
twemproxy를 사용하는 방법
-
Sharding
-
데이터를 어떻게 나눌 것인가?
-
데이터를 어떻게 찾을 것인가?
-
하나의 데이터를 모든 서버에서 찾아야 한다면?
-
Range
-
그냥 특성 range를 정의하고 해당 range에 속하면 거기에 저장
1-10000 10001-200000 20001-30000 id = 5001 id = 15400 id = 23000 id = 1000 id = 11002 id = 13003 이벤트를 해서 2번에 몰렸다가 다 탈퇴 → 2번 서버가 놈 → 다른 데이터가 2번으로 이동을 못함
→ 서버의 상황에 따라 놀고 있는 서버와 안놀고 있는 서버와 극심하게 나눠질 수 있음
→ 확장은 편하지만 중간에 빠져나가거나 초창기 유저가 저장 되어 있는 서버만 계속 일함
-
-
Indexed server
- 해당 Key가 어디에 저장되어야 할 지 알려주는 관리 서버가 따로 존재
- 놀고 먹는 서버 쪽으로 많이 넣어주고 열심히 일하는 서버 데이터를 빼서 다른 쪽으로 넣어줌
- 모든 정보를 인덱스 서버가 가지고 있기 때문에 인덱스 서버가 죽으면 서비스가 안 된다
-
modular
- 서버 증축을 2의 배수로 늘림 → 자기가 가야 할 서버가 결정됨
- 문제는 2→4→8→16→32대씩 늘려야 함
-
-
-
-
-
Redis Cluster
