(하기 내용은 우아한 테크 세미나 강의를 보고 따라 정리함)
[우아한테크세미나] 191121 우아한레디스 by 강대명님
Redis 데이터분산
- Redis Cluster
- Hash 기반으로 Slot 16384로 구분
- Hash 알고리즘은 CRC16을 사용
- Slot = crc16(key) % 16384
- Key가 Key{hashkey} 패턴이면 실제 crc16에 hashkey가 사용된다
- 특정 Redis 서버는 이 slot range를 가지고 있고, 데이터 migration은 이 slot 단위의 데이터를 다른 서버로 전달하게 된다.(migrateCommand 이용)
- 장점
- 자체적인 Primary, Secondary Failover Primary가 죽어 버리면 자동으로 Secondary가 승격됨
- Slot 단위의 데이터 관리 이 key는 어디로 보내라~ 이렇게 명시적으로 지정할 수 있음
- 자체적인 Primary, Secondary Failover Primary가 죽어 버리면 자동으로 Secondary가 승격됨
- 단점
- 메모리 사용량이 더 많음
- Migration 자체는 관리자가 시점을 결정해야 함
- Library 구현이 필요함
- Hash 기반으로 Slot 16384로 구분
- Redis Failover
-
Coordinator 기반 Failover
- Zookeeper, etcd, consul 등의 Coordinator 사용
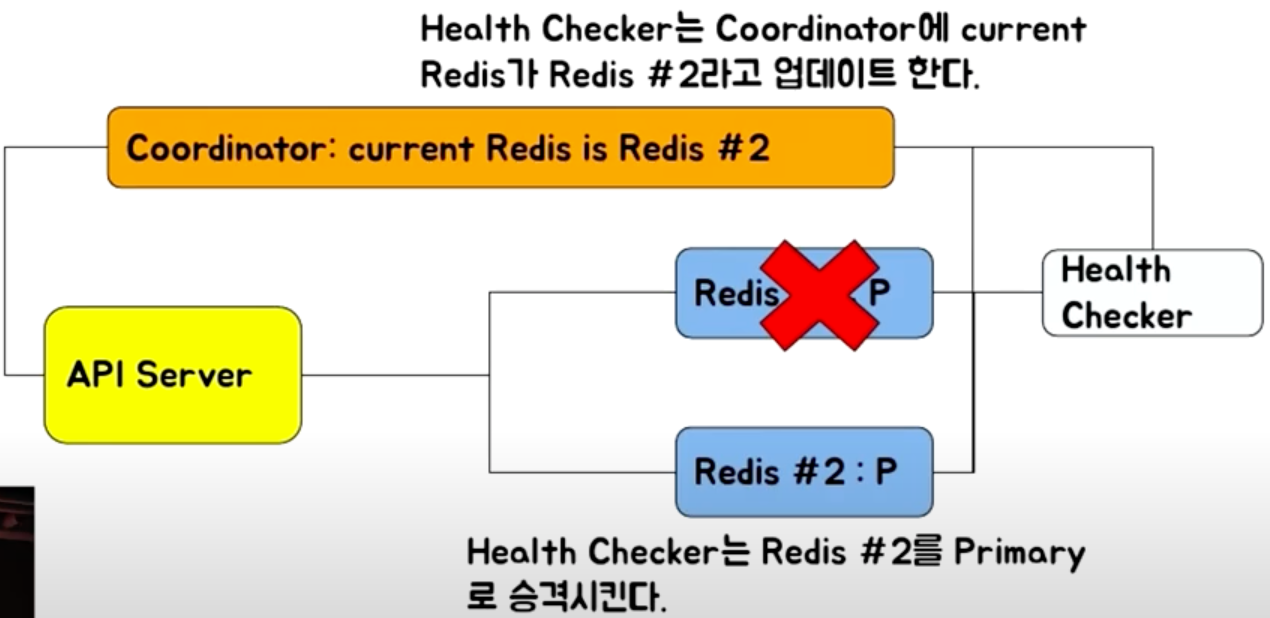
- Health Checker는 Redis #2를 Primary로 승격시킨다
- Health Checker는 Coordinator에 current Redis가 Redis #2라고 업데이트 한다
- Coordinator는 API Server에 current Redis가 변경되었다고 알려준다
- API Server는 내가 접속해야 하는 서버는 2번이구나!(code를 짜 줘야 함)
- Coordinator 기반으로 설정을 관리한다면 동일한 방식으로 관리가 가능
- 해당 기능을 이용하도록 개발이 필요하다
- 이미 사용하고 있는 경우는 불가능 → VIP
-
VIP(virtual IP) Failover
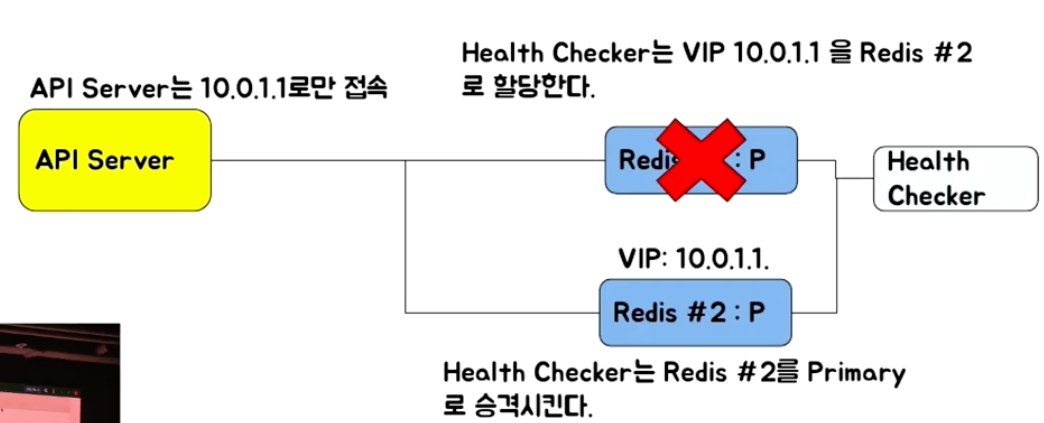 - (장애가 나지 않았을 때도) Health Checker는 Redis #1에 있던 기존 연결을 모두 끊어준다(클라이언트의 재접속 유도)
-
DNS 기반 Failover
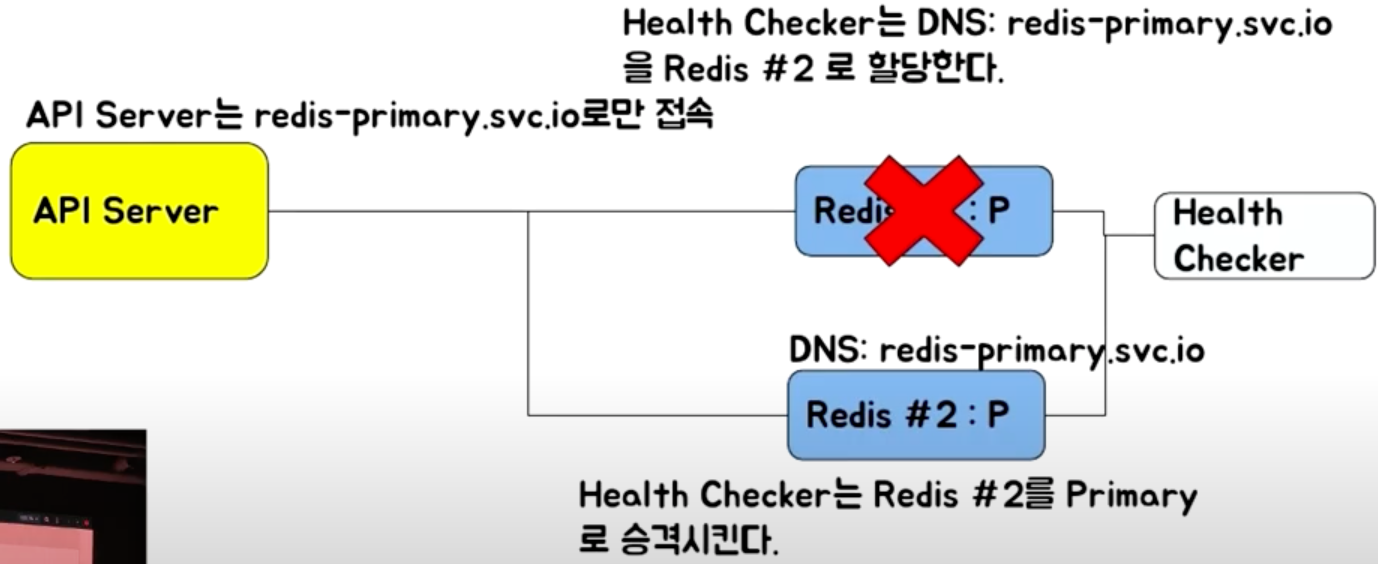
- 도메인을 바꿔주는 방식 Health Checker는 Redis #1에 있던 기존 연결을 모두 끊어준다(클라이언트의 재접속 유도)
- 도메인을 바꿔주는 방식 Health Checker는 Redis #1에 있던 기존 연결을 모두 끊어준다(클라이언트의 재접속 유도)
-
VIP와 DNS 모두 코드를 바꿔야 할 필요가 없기 때문에, 매뉴얼한 작업 없이 자동으로 복구
-
끊어지는 사이에 복구되는데 몇 초 ~ 몇 십초 정도 걸리지만 자동으로 복구 가능
-
클라이언트에 추가적인 구현이 필요없다
-
VIP 기반은 외부로 서비스를 제공해야 하는 서비스 업자에게 유리(예를 들어 클라우드 업체)
-
DNS 기반은 DNS Cache TTL을 관리해야 함
- 사용하는 언어별 DNS 캐싱 정책을 잘 알아야 함
- 툴에 따라서 한 번 가져온 DNS 정보를 다시 호출하지 않는 경우도 존재(어떤 솔루션들은 DNS를 캐싱해버린다. 자바는 디폴트로 30초를 가져가는데 30초가 지나야 캐싱할 수 있는데, 옵션에 따라서 캐시를 무한대로 가져간다면 DNS를 바꿔도 접속이 안 됨. 솔루션이 DNS를 캐싱하는 경우에는 바꿀수가 없는데, VIP를 바꾸면 됨. 아마존은 DNS 사용함. DNS는 바꾸기가 쉬움)
-
Redis Cluster의 사용
-
- Monitoring Factor
- Redis Info를 통한 정보
- RSS : Physical memory를 얼마나 쓰고 있느냐 (1순위)
- Used Memory : 실제 Redis가 생각하는 자기가 쓰고 있는 memory
- Connection 수
- 초당 처리 요청 수
- System
- CPU
- Disk
- Network rx/tx
- CPU가 100%를 칠 경우
- 처리량이 매우 많다면?
- 좀 더 CPU 성능이 좋은 서버로 이전
- 실제 CPU 성능에 영향을 받음
- 그러나, 단순 get/set은 초당 10만 이상 처리가능
- O(N) 계열의 특정 명령이 많은 경우
- Monitor 명령을 통해 특정 패턴을 파악하는 것이 필요
- Monitor 잘못 쓰면 부하로 해당 서버에 더 큰 문제를 일으킬 수도 있음(짧게 쓰는게 좋음)
- 처리량이 매우 많다면?
- Redis Info를 통한 정보
결론
- 기본적으로 Redis는 매우 좋은 툴
- 그러나 메모리를 빡빡하게 쓸 경우, 관리하기가 어려움
- 32기가 장비라면 24기가 이상 사용하면 장비 증설을 고려하는 것이 좋음
- Write가 Heavy 할 때는 migration도 매우 주의해야 함
- Client-output-buffer-limit 설정이 필요(메모리가 커질 수록 크게 잡아야 함)
- Redis as Cache Cache일 경우는 문제가 적게 발생
- Redis가 문제가 있을 때 DB등의 부하가 어느 정도 증가하는 지 확인 필요
- Consistent Hashing도 실제 부하를 아주 균등하게 나누지는 않음 Adaptive Consistent Hashing을 이용해 볼 수 있음
- Redis as Persistent Store Persistent Store의 경우(절대 지워지면 안된다면?)
- 무조건 Primary / Secondary구조로 구성이 필요함
- 메모리를 절대로 빡빡하게 사용하면 안됨
- 정기적인 migration이 필요(fork해야 함)
- 가능하면 자동화 툴을 만들어서 이용
- monitoring을 잘해야!!!
- RDB / AOF가 필요하다면 Secondary에서만 구동

킴릴로
은혜님 짱!