
데이터베이스의 기본
일정한 규칙, 규약을 통해 구조화되어 저장되는 데이터의 모음이며 실시간 접근과 동시 공유가 가능하다.
DBMS (DataBase Management System) : DB를 제어, 관리하는 통합 시스템
1️⃣ 엔터티 (entity)
여러 개의 속성을 지닌 명사
속성 (attribute) : 릴레이션에서 관리하는 구체적이며 고유한 이름을 갖는 정보. 서비스의 요구 사항에 맞춰 속성이 정해진다.
강한 엔터티 : 혼자서 존재할 수 있는 엔터티 (ex. 건물)
약한 엔터티 : 다른 엔터티의 존재 여부에 따라 종속적인 엔터티 (ex. 방)
2️⃣ 릴레이션 (relation)
데이터베이스에서 정보를 구분하여 저장하는 기본 단위
데이터베이스는 엔터티에 관한 데이터를 릴레이션 하나에 담아서 관리한다.
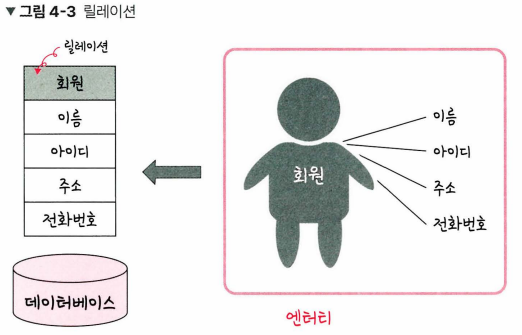
회원이라는 엔터티가 DB에서 관리될 때 릴레이션으로 변화된 것을 볼 수 있다.
관계형 DB에서의 릴레이션 : 테이블
NoSQL DB에서의 릴레이션 : 컬렉션
테이블과 컬렉션
관계형 DB (ex. MySQL) : 레코드 - 테이블 - DB 로 이루어짐
NoSQL DB (ex. MongoDB) : 도큐먼트 - 컬렉션 - DB 로 이루어짐
3️⃣ 속성 (attribute)
릴레이션에서 관리한다. 구체적이며 고유한 이름을 갖는 정보이다.
- ex) 자동차의 엔터티의 속성 : 바퀴 수, 색깔, 차종 … 이중에서 관리해야 할 필요가 있는 속성들만 엔터티의 속성이 된다.
4️⃣ 도메인 (domain)
릴레이션에 포함된 각각의 속성들이 가질 수 있는 값의 집합
- ex) 성별 속성의 도메인 : {남, 여} 집합
5️⃣ 필드와 레코드
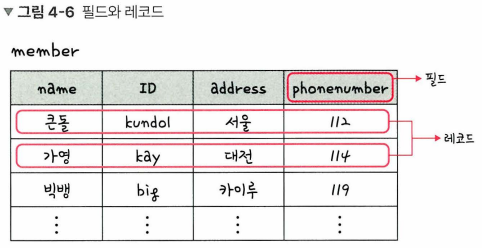
회원 엔터티 : member라는 테이블로 속성인 이름, 아이디 등을 가지고 있다.
레코드 (튜플) : 테이블에 쌓이는 행(row) 단위의 데이터
필드 타입
필드는 타입을 가지며, DBMS마다 다르다. 아래 내용은 MySQL 기준이다.
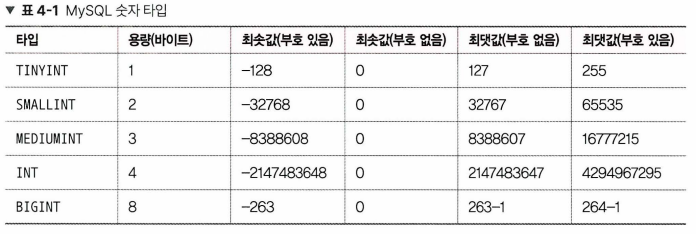
숫자 타입
날짜 타입
DATE: 날짜만 사용 (3 bytes)DATETIME: 날짜 및 시간 모두 사용 (8 bytes)TIMESTAMP: 날짜 및 시간 모두 사용 (4 bytes)
문자 타입
CHAR: 고정 길이 문자열 (0 ~ 255)VARCHAR: 가변 길이 문자열 (0 ~ 65535)- 입력된 데이터에 따라 용량을 가변시켜 저장
큰 데이터 저장 타입
TEXT: 큰 문자열 저장- ex) 게시판의 본문
BLOB: 이미지, 동영상 같은 큰 데이터 저장- 그러나 보통은 S3 저장 후 경로를 VARCHAR로 저장
문자열 열거 타입
ENUM: ENUM(x-small, small, medium, large, x-large) 형태로 쓰이며 단일 선택만 가능- 잘못된 값을 삽입하면 빈 문자열이 대신 삽입
- x-small 등이 0,1 등으로 매핑되어 메모리를 적게 사용하는 이점
- 최대 65,535개의 요소
SET: ENUM과 비슷하지만, 여러 개의 데이터를 선택할 수 있고 비트 단위의 연산을 할 수 있음- 최대 64개의 요소
6️⃣ 관계 (relationship)
DB엔 여러개의 테이블이 있고, 서로의 관계가 화살표로 정의되어 있다.
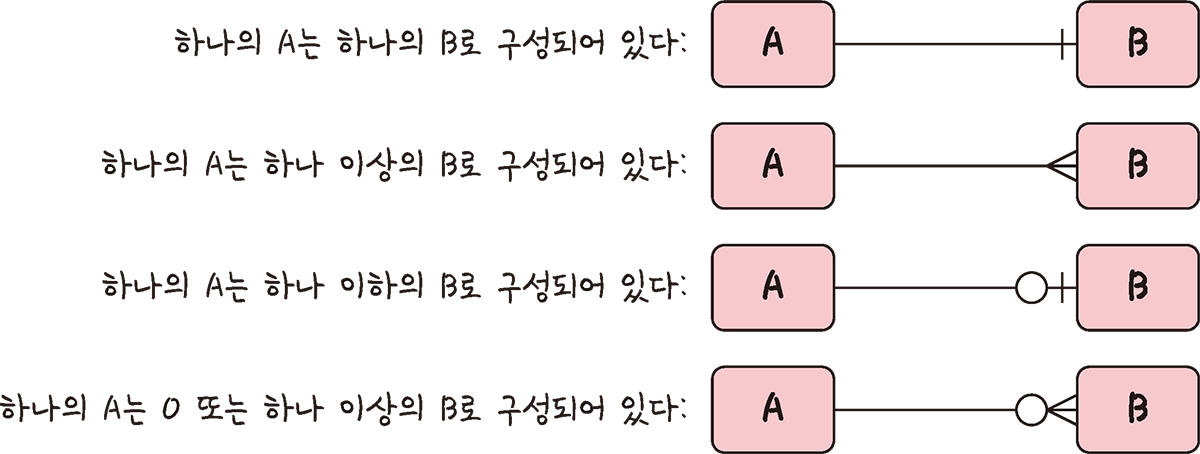
1 : 1 관계
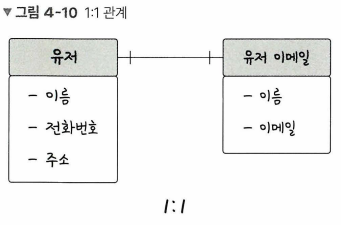
- ex) 유저는 하나의 이메일을 갖는다.
- 테이블을 두개로 나눠 구조를 더 이해하기 쉽게 만듦
1 : N 관계
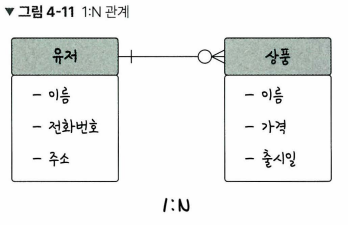
- ex) 쇼핑몰 운영시 한 유저가 여러개의 상품을 장바구니에 넣음
- 한 개체가 다른 많은 개체를 포함하는 관계
N : M 관계
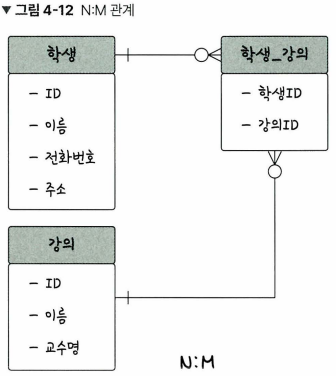
- ex) 학생과 강의의 관계. 한 학생이 여러 강의를 들을 수도 있으며 강의도 여러 학생을 포함할 수 있음
- 테이블 두개를 직접 연결 ❌
- 1 : N, 1 : M 테이블 두개로 나눠서 설정한다.
7️⃣ 키
테이블 간 관계를 명확히 하고, 테이블 자체의 인덱스를 위해 설정된 장치
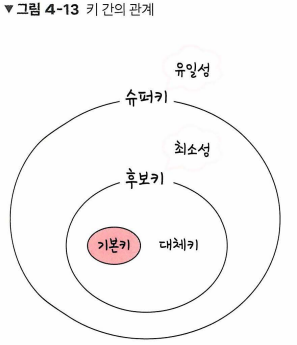
유일성 : 중복되는 값이 없음
최소성 : 필드를 조합하지 않고 최소 필드만 사용해 키를 형성할 수 있는 것
기본키 (Primary Key)
유일성과 최소성을 만족하는 키. 자연키와 인조키 중 설정한다.
자연키 (Natural Key) : 중복되지 않은 값들을 ‘자연스레’ 뽑다가 나오는 키 - 언젠가는 변하는 속성을 가진다.
- ex) 유저 테이블의 속성 중, 주민번호가 중복되지 않기에 선택
인조키(Artificial Key) : 인위적으로 생성한 키 (고유 식별자 부여) - 인위적으로 생성한 키
따라서 보통은 인조키를 기본키로 사용한다.
외래키 (Foreign Key)
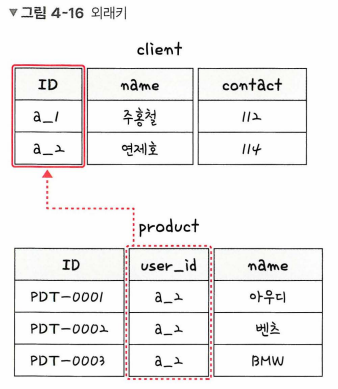
다른 테이블의 기본키를 그대로 참조하는 값
개체와의 관계를 식별하는 데 사용하기에 중복되어도 괜찮다.
후보키 (Candidate Key)
기본키가 될 수 있는 후보로, 유일성과 최소성을 동시에 만족한다.
대체키 (Alternate Key)
후보키가 두 개 이상일 경우, 기본키 이외의 남은 후보키를 칭한다.
슈퍼키 (Super Key)
각 레코드를 유일하게 식별할 수 있는 유일성을 갖춘 키
데이터베이스의 종류
1️⃣ 관계형 데이터베이스 (RDBMS)
행과 열을 가지는 표 형식의 데이터를 저장하는 형태의 DB
- SQL 언어로 조작한다.
- ex) MySQL, PostgreSQL, 오라클, SQL Server, MSSQL …
- 표준 SQL을 지키지만, 각 제품에 특화된 SQL을 사용한다.
MySQL
대부분의 운영체제와 호환되며 현재 가장 많이 사용하는 DB
- C, C++로 만들어짐
- MyISAM 인덱스 압축 기술, B-Tree 기반 인덱스, 스레드 기반 메모리 할당 시스템, 매우 빠른 조인, 최대 64개의 인덱스 제공
- 대용량 DB를 위해 설계되어 있다.
- 롤백, 커밋, 이중 암호 지원 보안 등의 기능 제공
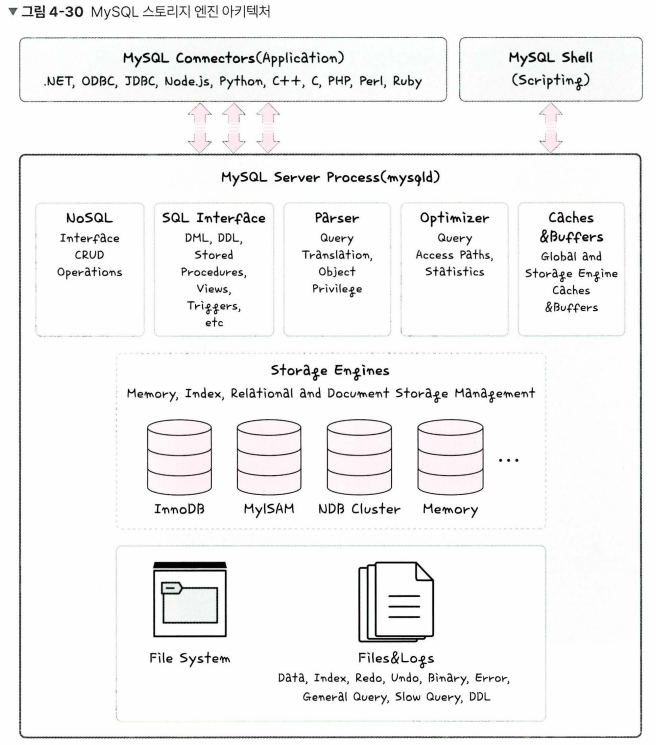
- 스토리지 엔진 : DB의 심장과도 같은 역할
- 모듈식 아키텍처로 쉽게 스토리지 엔진을 바꿀 수 있다.
- 데이터 웨어하우징, 트랜잭션 처리, 고가용성 처리에 강점을 두고 있다.
- 쿼리 캐시 지원 : 조회한 쿼리문을 저장하고 있다가, 같은 쿼리문을 요청받으면 캐싱된 값을 반환한다.
PostgreSQL
MySQL 다음으로 선호되는 DB
- VACUUM : 디스크 조각이 차지하는 영역을 회수할 수 있다.
- 최대 테이블의 크기 : 32TB
- SQL 뿐만 아니라 JSON을 이용해 데이터 접근 가능
- 지정 시간 복구 기능, 로깅, 접근 제어, 중첩된 트랜잭션, 백업 등 가능하다.
2️⃣ NoSQL 데이터베이스
SQL을 사용하지 않는 DB를 말하며, 대표적으로 MongoDB와 redis가 있다.
- 데이터간의 관계를 정의하지 않는다.
- RDBMS는 데이터 관계를 키로 정의하고 JOIN을 수행하지만, NoSQL은 JOIN 연산이 불가능하다.
- 대용량의 데이터를 저장할 수 있다.
- 분산형 구조이다.
- 데이터를 분산 저장해 특정 서버에 장애가 발생했을 때도 데이터 유실, 서비스 중지가 발생되지 않도록 한다.
- 고정되지 않은 테이블 스키마를 갖는다.
- 데이터를 저장하는 컬럼이 각 다른 이름과 다른 데이터 타입을 갖는 것이 허용된다.
MongoDB
- JSON을 통해 데이터에 접근할 수 있으며 Binary JSON(BSON) 형테로 데이터가 저장된다.
- 확장성이 뛰어나며 빅데이터를 저장할 때 성능이 좋다.
- 고가용성, 샤딩, 레플리카셋을 지원한다.
- 스키마를 정해놓지 않고 데이터를 삽입할 수 있기에 다양한 도메인 DB를 기반으로 분석하거나 로깅 등을 구현할 때 강점이다.
- 도큐먼트를 생성할 때마다 다른 컬렉션에서 중복된 값을 지니기 힘든 ObjectID가 생성된다.
redis
인메모리 데이터베이스이자 키 - 값 데이터 모델 기반의 데이터베이스
- 기본적인 데이터 타입은 문자열(String)이며 최대 512MB까지 저장가능
- set, hash지원
- pub / sub 기능을 통해 채팅 시스템, 다른 DB 앞단에 두어 캐싱 계층, 세션 정보 관리, sorted set 자료구조를 이용한 실시간 순위표 서비스에 활용가능하다.
인덱스는 아래 링크에 정리해두었기에, 따로 정리는 안하겠습니다.
CS 스터디 - DB index
가볍게 읽는 DB INDEX (with B-Tree)
refer
