KGCN : Knowledge Graph Convolutional Networks for Recommender Systems (2019)
[GNN] Paper review
목록 보기
1/2

0. Abstract
1. Introduction
2. Related Work
- KGCN은 개념적으로 GCN에 영향을 받았으며, 일반적으로 GCN은 2가지 유형(Spectral Vs. Non-spectral)으로 구분할 수 있음
- KGCN은 지식그래프(KG)에 Non-spectral 방법론을 적용한 것
- KGCN은 PinSage와 GAT 방법론과도 연관되어 있음
- PinSage와 GAT는 homogeneous graph에 적용한 방법론
- KGCN은 hetrogeneous graph에 적용하여 추천시스템을 위한 새로운 관점을 제시
3. KGCN
3.1. Problem Formulation
3.2. KGCN Layer
3.3. Learning Algorithm
4. Experiments
4.1. Datasets
4.2. Baselines
- KGCN을 다른 방법론들과 비교
- KG-free methods
- SVD is a classic CF-based model using inner product to model user-item interactions.
- LibFM is a feature-based factorization model in CTR scenarios. We concatenate user ID and item ID as input for LibFM.
- KG-aware methods
- LibFM + TransE extends LibFM by attaching an entity representation learned by TransE to each user-item pair.
- PER treats the KG as heterogeneous information networks and extracts meta-path based features to represent the connectivity between users and items.
- CKE combines CF with structural, textual, and visual knowledge in a unified framework for recommendation. We implement CKE as CF plus a structural knowledge module in this paper.
- RippleNet is a memory-network-like approach that propagates users’ preferences on the KG for recommendation.
- KG-free methods
4.3. Experiments Setup
4.4. Results
4.4.1. Impact of neighbor sampling size
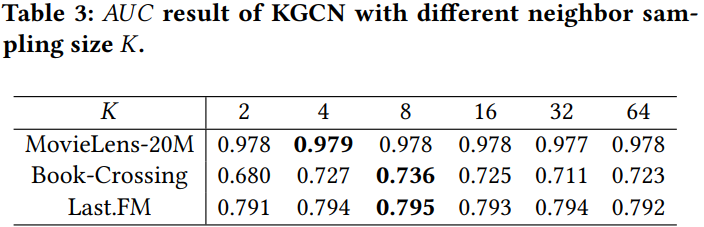
- K = 2, 4, 8, 16, 32, 64에 대해서 실험한 결과,
K=4 or K=8일 때의 결과가 가장 좋았음 - K가 너무 작으면 이웃들의 정보를 잘 반영할 수 없고, 너무 크면 오히려 noise를 발생시키기 때문
4.4.2. Impact of depth or receptive field
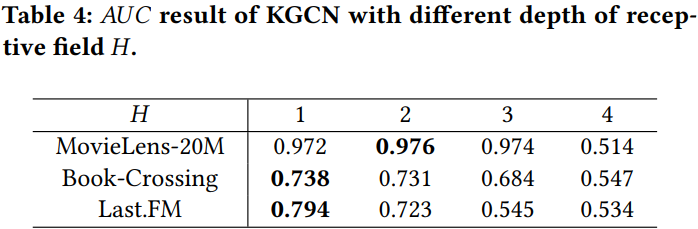
- H = 1, 2, 3, 4에 대해서 실험 진행. KGCN은 K(neighbor sampling size)보다 H(depth)에 더 영향을 많이 받음
- H가 커질수록 noise가 많이 발생.
H=1 or H=2정도가 적당
4.4.3. Impact of dimension of embedding

- embedding 차원 d가 커지면 커질수록 성능이 좋아지는 경향을 보이다가, 일정 수준이 지나면 over-fitting이 발생
5. Conclusions And Future Work
[참고]
https://velog.io/@lse7530/GNN-Knowledge-Graph-Convolutional-Networks-for-RecommenderSystems
https://themore-dont-know.tistory.com/5

The brightest star in the night sky