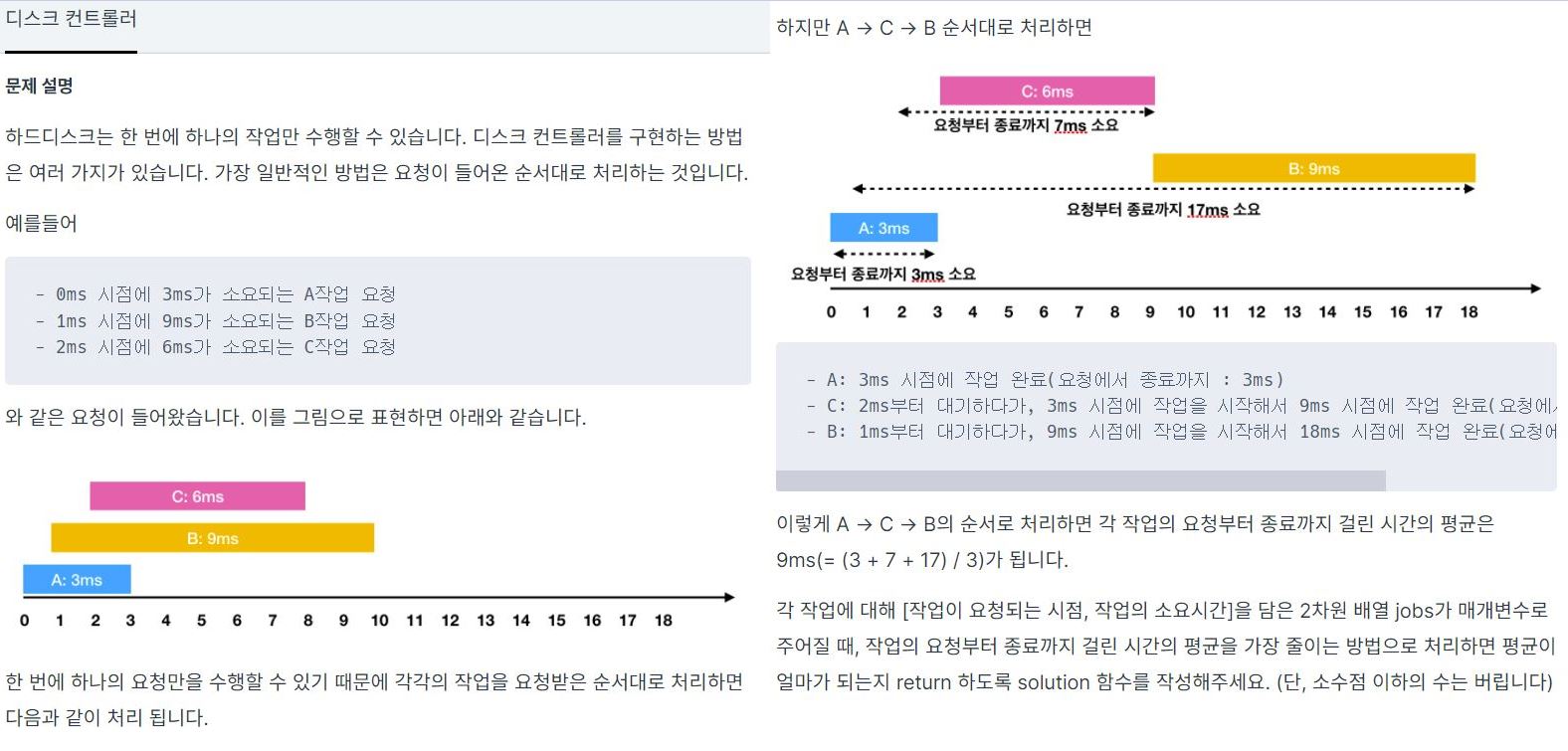
문제는 위와같이 한 번에 하나의 작업만 수행할 수 있는 하드디스크에 작업이 들어왔을 때, 요청부터 종료까지 걸린 시간이 평균을 가장 줄이는 방법으로 처리하는 평균을 구하는 문제이다.
1. 작업 시간이 제일 작은 것부터 나오는 min heap을 구현
struct compare {
bool operator() (vector<int>a, vector<int>b) {
return a[1]>b[1];
}
};
priority_queue <vector<int>, vector<vector<int>>, compare> pq;priority_queue를 구현할 때 제일 첫 번째 인자는 queue에 담길 자료형, 두 번째 인자는 vector<vector< int>> 컨테이너, 마지막은 사용자 정의 비교 연산자 compare을 사용했다.
compare 비교 연산자는 작업 시간이 제일 작은 것 부터 나오는 queue를 구현하기 위해 작성했다.
위 코드에서 a는 부모 노드이고 b는 현재 노드다. 만약 a가 b보다 크다면 true를 return해서 swap을 진행한다. 이를 반복하다 보면 조상 노드는 가장 작은 원소가 차지한다.
2. 들어온 시간 순으로 jobs를 정렬
sort(jobs.begin(), jobs.end());3. 변수 선언
int total_time = 0; //요청부터 종료까지 각각 소요된 시간의 합
int current_time=0; //현재 작업이 진행되고 있는 시간
int jobSize=jobs.size();
int job_cnt=0; //몇 번 째 jobs인지 check하기 위한 변수4. priority queue와 jobs가 빌 때까지 반복
5. 현재 시간(current_time)이 jobs에 작업이 들어온 시간 (jobs[job_cnt][0])을 넘기거나 같다면 queue에 대기(push)
if (job_cnt<jobSize && jobs[job_cnt][0]<=current_time) {
pq.push(jobs[job_cnt++]);
continue;
}
6. priority queue가 비어있지 않다면 우선 순위가 가장 높은 작업 (작업의 시간이 제일 작은 작업)부터 수행(pop)
if (!pq.empty()) {
current_time+=pq.top()[1];
total_time+=current_time-pq.top()[0];
pq.pop();
}현재 시간(current_time)에 현재 수행될 작업의 시간 (pq.top()[1])을 더해준다.
전체 시간의 합(total_time)에 현재 작업이 대기한 시간부터 작업이 수행된 시간을 더해준다.
7. priority queue가 비어있다면 현재 시간(current_time)을 남아있는 jobs의 작업이 들어오는 시간 (jobs[job_cnt][0])으로 바꿔줌
else {
current_time=jobs[job_cnt][0];
}
전체코드
#include <string> #include <vector> #include <queue> #include <algorithm> using namespace std; int solution(vector<vector<int>> jobs) { int total_time = 0; int current_time=0; int jobSize=jobs.size(); int job_cnt=0; struct compare { bool operator() (vector<int>a, vector<int>b) { return a[1]>b[1]; } }; priority_queue <vector<int>, vector<vector<int>>, compare> pq; sort(jobs.begin(), jobs.end()); while (job_cnt<jobSize || !pq.empty()) { if (job_cnt<jobSize && jobs[job_cnt][0]<=current_time) { pq.push(jobs[job_cnt++]); continue; } if (!pq.empty()) { current_time+=pq.top()[1]; total_time+=current_time-pq.top()[0]; pq.pop(); } else { current_time=jobs[job_cnt][0]; } } return total_time/jobSize; }

백엔드 개발자 지망생에서 Test Engineer. 를 지나 AI Engineer를 향해 가는 Software Engineer (https://juyoungkimmy-kim.github.io/ 블로그 이주))