캐시(Cache)
Cache란 자주 사용하는 데이터나 값을 미리 복하새 놓은 임시 저장소를 가리킨다.
아래와 같은 저장공간 계층 구조에서 확인할 수 있듯이, 캐시는 저장 공간이 작고 비용이 비싼 대신 빠른 성능을 제공한다.

Cache는 아래와 같은 경우에 사용을 고려하면 좋다
- 접근 시간에 비해 원래 데이터를 접근하는 시간이 오래 걸리는 경우
- 반복적으로 동일한 결과를 돌려주는 경우(이미지 / 썸네일 등)
Cache에 데이터를 미리 복사해 놓으면 계산이나 접근 시간 없이 더 빠른 속도로 데이터에 접근이 가능하다.
결국 Cache란 반복적으로 데이터를 불러오는 경우에, DBMS 혹은 서버에 요청하는 것이 아니라
Memory에 데이터를 저장하였다가 불러다 쓰는 것을 의미한다.
원하는 데이터가 캐시에 존재할 경우 해당 데이터를 반환하며, 이러한 상황을 Cache Hit이라 한다.
원하는 데이터가 존재하지 않을 경우 DBMS 또는 서버에 요청을 해야하며 이를 Cache Miss라고 한다.
캐시의 필요성

위 그래프는 파레토 법칙 이다.
파레토 법칙은 '이탈리아 인구의 20%가 이탈리아 전체 부의 80%를 가지고 있다. '고 주장한 이탈리아의 경제학자 빌프레도 파레토의 이름에서 따왔다고 한다.파레토 법칙은 '2080법칙'이라고도 하는데 '전체 결과의 80%가 전체 원인의 20%에서 일어나는 현상'을 의미한다.
프로그래밍에서도 마찬가지로 자주 그리고 반복해서 사용하게 되는 데이터들이 있다.
많이 사용되는 20%의 데이터를 캐싱한다면 데이터를 빠르게 접근하여 사용할 수 있으므로 프로그램의 성능도 향상될 것이다.
어떤 정보를 캐시에 담아야 할까
모든 데이터를 캐시에 담기에는 캐시라는 저장 공간은 작다. 그렇기 때문에 파레토 법칙에 해당하는 소수의 데이터를 선별해야 한다. 이때 사용되는 것이 지역성이다.

시간적 지역성
특정 데이터가 한번 접근되었을 경우, 가까운 미래에 또 한번 데이터의 접근할 가능성이 높은 것을 의미한다.
메모리 상의 같은 주소에 여러 차례 쓰기를 수행할 경우 상대적으로 작은 크기의 캐시를 사용해도 효율성을 꾀할 수 있다.
공간적 지역성
특정 데이터와 가까운 주소가 순서대로 접근되었을 경우를 공간적 지역성이라고 한다.
CPU 캐시나 디스크 캐시의 경우 한 메모리 주소에 접근할 때 그 주소뿐 아니라 해당 블록을 전부 캐시에 가져오게 된다. 이때 메모리 주소를 오름차순이나 내림차순으로 접근한다면, 캐시에 이미 저장된 같은 블록의 데이터를 접근하게 되므로 캐시의 효율성이 크게 향상된다.
순차 지역성
공간 지역성과 함께 설명되기도 한다. 데이터가 순차적으로 엑세스되는 경향을 보인다.
프로그램 내의 명령어가 순차적으로 구성된다.
캐시 사용 구조
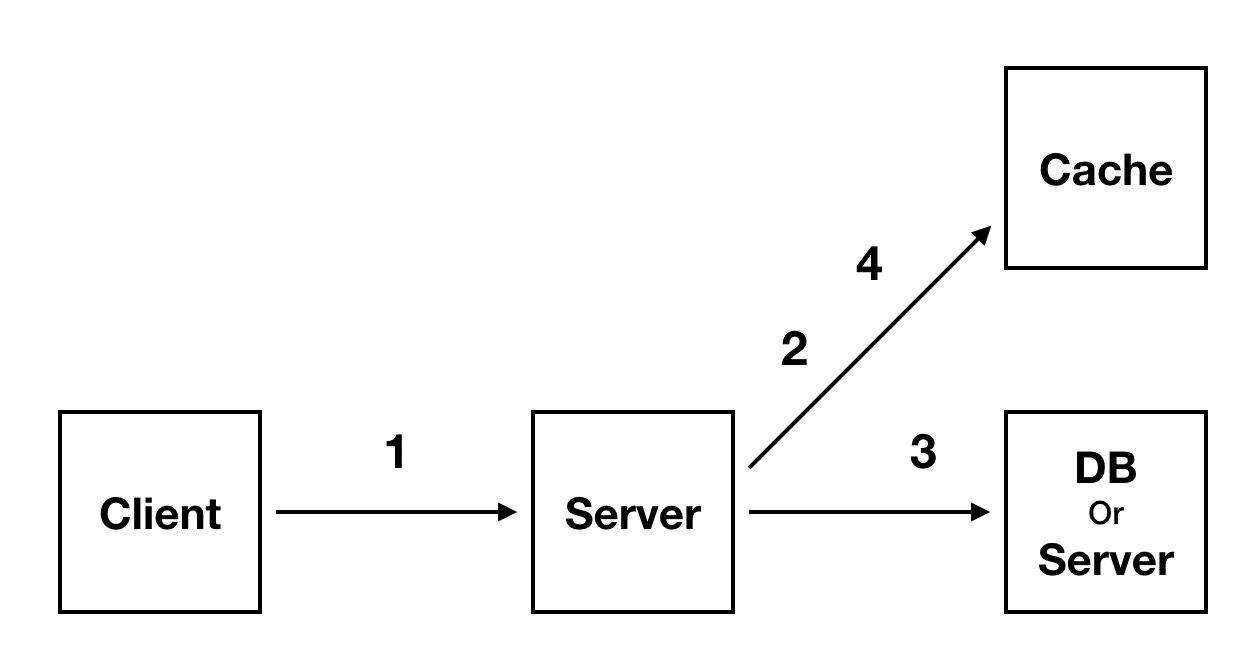
- Client로 부터 요청을 받는다.
- Cache와 작업을 한다.
- 실제 DB와 작업한다.
- 다시 Cache와 작업한다.
Cache는 일반적으로 위의 이미지와 같은 flow로 사용된다.
동일한 flow에서 어떻게 사용하냐에 따라서 look aside cache(Lazy Loading)와 wrtie back으로 나뉜다.
look aside cache (Lazy Loading)
- Cache에 Data 존재 유무 확인
- Data가 있다면 Cache의 Data 사용
- Data가 없다면 Cache의 실제 DB Data 사용
- DB에서 가져온 Data를 Cache에 저장
look aside cache는 캐시를 한번 접근하여 데이터가 있는지 판단한 후, 있다면 Cache의 데이터를 사용하며 없다면 실제 DB 또는 API를 호출하는 로직으로 구현된다.
대부분의 Cache를 사용한 개발이 해당 프로세스를 따르고 있다.
write back
- Data를 Cache에 저장
- Cache에 있는 Data를 일정 기간동안 Check
- 모여있는 Data를 DB에 저장
- Cache에 있는 Data 삭제
write back은 cache를 다르게 이용하는 방법이다,
DB는 접근 횟수가 적을수록 전체 시스템의 퍼포먼스는 좋아진다. 데이터를 쓰거나 많은 데이터를 읽게 되면 DB에서 Disk를 접근하게 된다. 이렇게 되면 Application의 속도 저하가 일어날 수 있다. 따라서 wrtie back은 데이터를 Cache에 모으고 일정한 주기 또는 일정한 크기가 되면 한번에 처리하는 것이다.
