이번에 소개할 논문은 “An Efficient Explanation of Individual Classification using Game Theory”입니다.
많이 알려진 SHAP은 Feature Importance를 계산하기 위해서 shapely value의 개념을 사용합니다.
본 논문은 그 이전에 shapely value를 활용한 explanation method를 제안하는 논문입니다.
논문 링크 : https://dl.acm.org/doi/abs/10.5555/1756006.1756007
Introduction
본 논문은 shapely value를 활용한 explanation을 설명하기 위해서 4 단계로 진행됩니다.
- Coaltional Game Theory의 개념을 도입했을 때 기존 Explanation의 한계를 개선할 수 있다.
- 위의 세팅에서 Feature Importance는 Shapely value로 계산될 수 있다.
- Alternative form과 sampling 기법을 통해 적당한 시간 복잡도로 shapely value를 계산할 수 있다.
- Feature Contribution을 통해 Instance level에서 모델을 이해하고 신뢰성을 비교할 수 있다.
Explaination & Coal Gameme Theory.
1. Explanation?
Explanation은 모델의 예측을 이해하기 쉽게하고, 신뢰할 수 있게 하기 위해서 필요합니다.
본 논문에서는 모델의 종류와 무관하게 적용될 수 있는 General Explanation
그리고 각 데이터의 prediction에 대해서 instance level의 Explanation을 따릅니다.
따라서 Explanation은 Prediction에 대한 각 Feature의 Contribution을 제시하는 방식으로 이뤄집니다.
2. Coalitional Game Theory?
Game Theory는 player가 협력적인 경우와 비협력적인 경우로 나눌 수 있습니다.
그 중 Coalitional Game은 각 player가 연합(Coalition)해 value를 payoff로 배분하는 형태의 게임입니다.
Shapely Value는 Coalitional Game에서 value를 각 Player에게 동등한(symmetric) contribution을 가정하고 분배하는 payoff를 계산하는 식입니다.
Shi(v)=S⊆N∖{i},s=∣S∣∑n!(n−s−1)!(v(S∪{i})−v(S))
사진 (개념 대응되는)
3. Coalitional Game to Explanation
Coaltional Game의 setting을 아래와 같이 설정한다면 Feature Importance를 계산하는 문제에 적용할 수 있습니다.
- player : Feature
- value function: set of player → prediction difference
- payoff : 각 변수의 contribution
기존의 general explanation 기법은 변수 1개 단위로 다루어 feature간의
conditional dependent한 경우 즉 Interaction을 설명하지 못하는 한계가 있었습니다.
Coaltional Game Theory의 value function은 player의 subset에 대해 값을 부여합니다.
따라서 player에서 player의 set으로 value 계산의 단위를 변경해 변수들의 Interaction을 다룰 수 있을 것입니다.
Define Explanation method
Definitions
(PredictionDifference)Δ(S)=∣∣∣AN∖S∣∣∣1y∈AN∖S∑fC(τ(x,y,S))−∣AN∣1y∈AN∑fC(y)⋯(1)
Prediction Difference은 S에 속한 feature값을 알 때 Prediction 기댓값과 모를 때의 Prediction 기댓값의 차이로 정의했다. 변수들이 Prediction에 평균적으로 미친 영향력을 의미한다.
(Interaction)Δ(S)=W⊆S∑I(W)⇆I(S)=W⊆S∑((−1)∣S∣−∣W∣Δ(Q))⋯(2)
Prediction Difference는 변수들의 집합 S에서 발생할 수 있는 모든 Interaction의 합으로 정의된다. 왼쪽 식을 귀납적으로 정리하면 오른쪽 식으로 변환할 수 있다.
(ithfeature′sContribution)φi(Δ)=W⊆N∖{i}∑∣W∪{i}∣I(W∪{i})⋯(3)
따라서 i번째 변수의 Contribution은 변수가 포함된 모든 Interaction에서 동등한 contribution을 했음을 가정해 변수 개수로 나눠준 값의 합으로 정의된다. Interaction은 변수 집합의 power set에 대한 값이 아니기 때문에 모든 변수에 동등하게 분배된다는 (symmetric) 가정은 타당하다.
위 식은 다 전체 데이터에 대한(기대값인데) 왜 instance level로 계산이 가능한거지...?
contribution = shapely value
본 논문은 1 페이지 정도의 과정을 통해서 φi(Δ)의 값이 shapely value의 꼴과 같음을 증명합니다.
φi(Δ)=W⊆N∖{i}∑∣W∪{i}∣∑Q⊆W∪{i}((−1)∣W∪{i}∣−∣Q∣Δ(Q))
첫째로 (2)식과 (3)식을 연립해 Δ(Q)에 관한 식으로 정리합니다.
위 식을 관찰하면 각 subset의 계수는 ∣S∣+1+t(tk) 교대급수 꼴임을 알 수 있습니다.
MΔ(S):=thecoefficientofallsuchappearanceofsetS,k=n−∣S∣−1MΔ(S∪{i})=t=0∑kn−k+t−1t(tk)=B(n−k,k+1)=V(n,k)MΔ(S)=t=0∑kn−k+t−1t−1(tk)=−B(n−k,k+1)=−V(n,k)φi(Δ)=S⊆N∖{i}∑V(n,k)∗(Δ(S∪{i})−Δ(S))
앞선 발견을 수식으로 정리하면 위와 같습니다. 관찰하고자 하는 변수 {i}의 포함 여부에 따라 Δ(S∪{i})와 Δ(S) 두 가지의 계수를 계산했습니다. 따라서 i번째 Feature의 contribution은
φi(Δ)=S⊆N∖{i}∑n!(n−s−1)!s!(Δ(S∪{i})−Δ(S))
으로 앞서 서술한 shapely value의 꼴과 같습니다.
Example : 1∨1
N={1,2},A={0,1}×{0,1},x=(1,1)인 상황에서
기존의 방법론에서는 x∨1은 1∨1=0∨1=1임으로 contribution이 없다.
현재 방법론에서는 아래와 같이 계산됩니다.
- S={1}
- Δ({1})=Δ({2})=Δ({1,2})=1−43=41,Δ(∅)=0
- ∣AN∖S∣1∑y∈AN∖SfC(τ(x,y,S))=21∗(1+1)
- ∣AN∣1∑y∈ANfC(y)=41∗(1+1+1+0)
- I({1})=Δ({1})=41,I({2})=Δ({2})=41
- I({1,2})=Δ({1,2})−I({1})−I({2})=−41
- φ1=I({1})+2I({1,2})=81,φ2=I({2})+2I({1,2})=81
위 전개를 해보기 전에는 왜 instance별로 다른 결과가 나올 수 있는지 이해하지 못했었는데, instance별로 fC에서 다른 값을 가지게 되어 다른 결과가 나오는 것을 확인할 수 있었습니다.
Approximation to calculate features’ contributions
exponential time complexity
φi(Δ)=n!1O∈π(N)∑(Δ(Prei(O)∪{i})−Δ(Prei(O)))
Shapely Value는 위의 alternative 한 form으로 계산이 가능합니다. Feature contribution을 계산하기 위해선 모든 subset S에 대한 Δ 계산이 필요합니다. fC(τ(x,y,S))항에서 각 S마다 새로운 모델 학습이 필요하기 때문에 exponential time complexity 문제가 발생합니다.
extend sampling method
미완
min sample to keep error rate and speed
미완
Examples of Explanation
Feature's Contribution
magitude와 sign 두 가지 관점에서 contribution을 해석할 수 있다. magnitude는 prediction에 영향을 미치는 정도 차이이고, sign의 부호에 따라 output을 증가시키거나 감소시키는 영향을 미친다.
Example
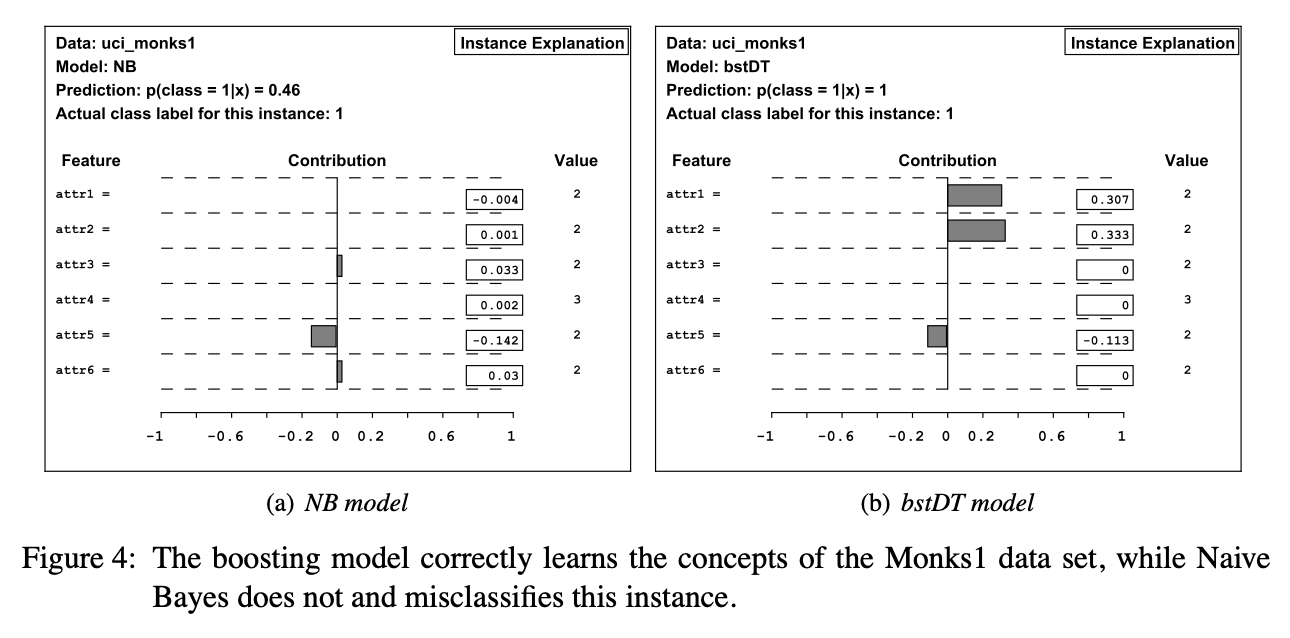
ucl_monks1 dataset의 class 1은 attr1과 attr2가 같거나, attr5=1인 특징이 있습니다. NB model은 bstDT model에 비해 첫번째 특징을 잘 학습하지 못한 것을 확인할 수 있습니다.
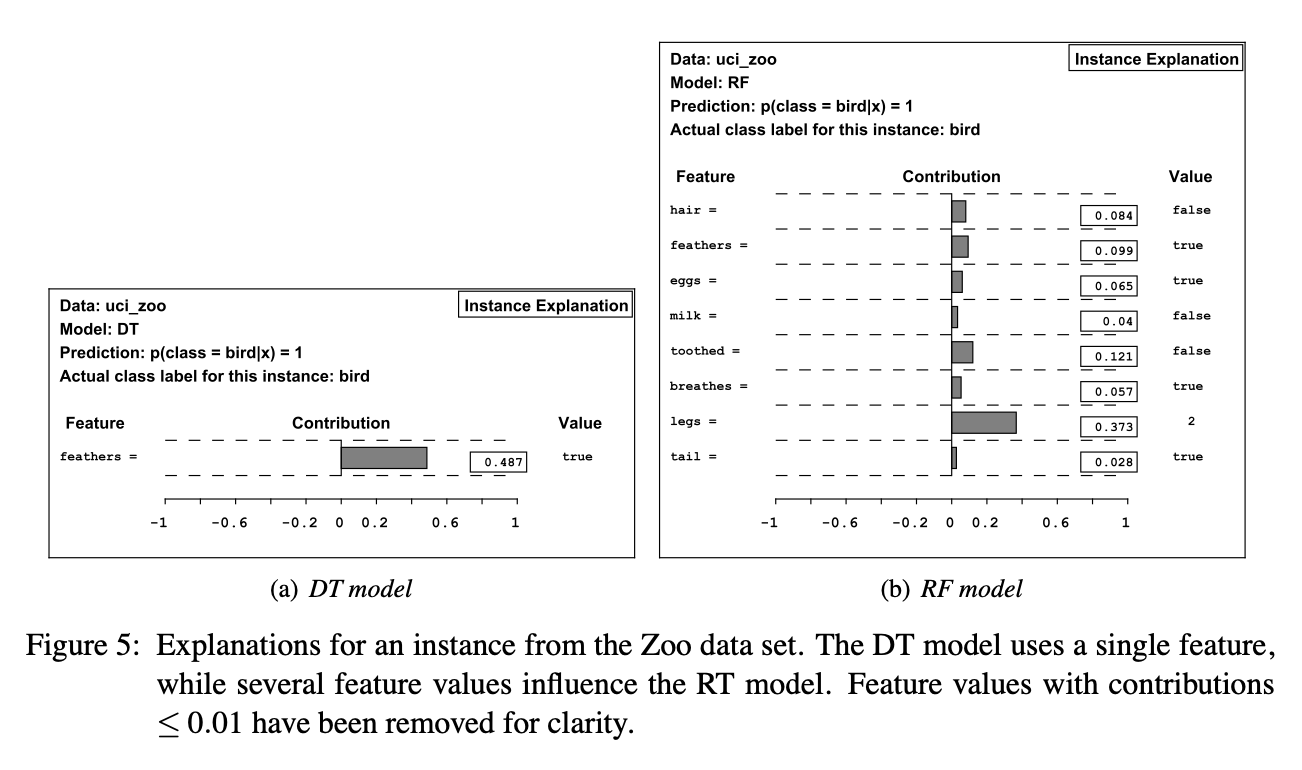
두 모델은 Prediction 항을 보면 같은 예측을 했지만, 판단 근거가 달랐음을 알 수 있습니다. 더 새와 연관된 다양한 feature를 기반으로 예측한 RF 모델이 보다 신뢰성이 높은 모델입니다.
