본 시리즈은 비전공자가 공부한 computer science, 그중에서도 컴퓨터구조를 정리한 글입니다. 틀린내용이 있다면 댓글로 알려주시면 정말정말 감사하겠습니다. 참고한 책은 Computer Organization and Design MIPS Edition입니다
컴퓨터구조 4주차 내용의 첫번째 포스팅입니다
4주차의 내용을 간단하게 소개해보자면 processor의 내용을 마무리하고 Control의 내용을 배우게됩니다
그렇다면 이번주의 내용도 시작해보겠습니다~

능이버섯이지만 해보겠습니다
ALU Control
ALU라는 건 우리가 지금까지 계산을 하기 위해서 사용했던 instruction을 통해서 계산을하는 회로라고 알고있습니다
계산이라는건 뭐 더하기를 한다거나 뺀다거나 이런걸 뜻하겠죠?
그렇다면 add, sub, and, or, slt의 경우엔 말그대로의 연산이 필요하다는걸 아실겁니다. bit끼리의 연산을 하거나 아니면 32bit자체의 연산을 하는 경우가 이런경우겠죠
그렇다면 이런 생각이들 수 있습니다
beq나 j나 lw 혹은 sw같은 경우, 분기를 해야하거나 데이터를 불러오고 저장하는 경우에는 어떤
연산이 사용될까?
사실 우리가 앞에서 말했던 add, sub, and, or, slt의 경우엔 op field와 function field의 bit를 통해서 각각의 연산을 ALU에게 input으로 넣어주면 되는데 lw와 sw의 경우 혹은 beq와 j의 경우엔 조금 애매해집니다(어디까지나 느낌상으로 애매해진다는 겁니다)
사실 lw, sw, beq, j의 경우는 op field의 bit만으로도 연산의 방법이 정해집니다. 그렇다면 ALU연산이 필요없을까요?
정답은 NO입니다
먼저 lw와 sw의 경우를 보면 결국 lw와 sw모두 base register의 값에서 offset을 계산해줘야합니다. 방금 제가 계산이라고 했죠? 결국 ALU연산이 필요하다는말이 됩니다. 결국 offset을 계산하기위해선 add instruction이 필요하게되고 lw sw 연산의 경우에도 ALU의 add가 필요하게 됩니다.
자 그러면 beq의 경우엔 어떨까요? beq는 rs rt의 값을 비교해서 같다면 branch를하고 아니면 다음pc주소의 instruction을 수행하게됩니다. 여기서 ALU의 어떤 연산이 필요할까요?
답은 비교에 있습니다. 사실저같은경우는 컴퓨터의 입장(?)에서 생각하려고 많이 노력하는 편인데요. 대체 두 값이 같다는건 어떻게 알수있을까? 뭐 이런식인거죠. 두 값이 같다는건 두 값의 차이가 0이라는뜻이 되고 이를 조금더 컴퓨터스럽게 이야기해보면 두 값을 빼면 0이된다라고 표현할수도 있습니다.
즉, beq의 branch여부를 판단하는건 rs와 rt의 sub연산의 결과가 0인지 0이 아닌지를 가지고 판단을 하면되기때문에 이러한 instruction 수행에서도 ALU연산이 필요하게됩니다.
조금 장황하게 설명을 한거 같아서 요약정리를 해보면 아래와 같습니다.
- R-foramt의 경우 op field와 function field의 bit를 통해서 ALU연산이 결정된다
- lw, sw의 경우 메모리주소를 계산하기 위해서 ALU에서 add instruction이 필요하다
- beq는 두 값의 equal여부를 판단하기 위해 ALU에서 sub instrution이 필요하다
Execution of Load/Store Instructions
이렇게 어떤 연산에 ALU의 어떤연산이 필요한지 알아봤습니다.
그러면 위에서 설명한 operator중에서 lw와 sw연산이 어떤 회로를 어떻게 겨처서 연산되는지에대해 알아보겠습니다
본격적인 이야기를 하기전에 lw, sw연산을 위해서는 어떤 논리회로가 필요할까를 생각해보면 좋을거같습니다
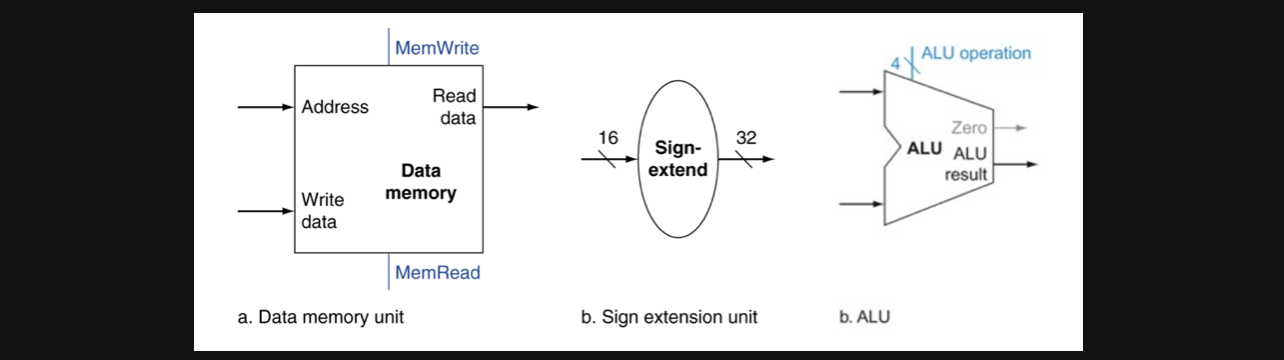
가장 우선적으로는 데이터를 저장하고 읽어오는거기때문에 data memory가 필요할겁니다. 그리고 sign extension을 할수있는 논리회로가 필요할겁니다. 이유는 instruction에서 offset이 16bit로 주어질텐데 이를 32bit와 연산하기 위해서는 32bit로의 변환이 필요하기 때문입니다
그리고 마지막으로 메모리의 주소를 offset과 계산하기 위한 add instruction을 수행하기 위한 ALU가 필요합니다
Part1: Instruction Fetch
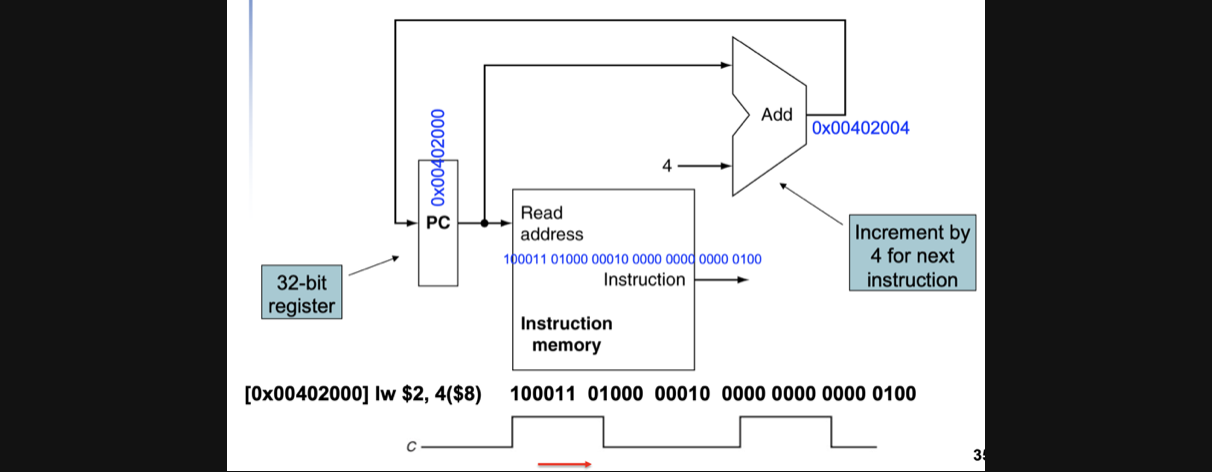
lw sw 연산의 시작은 이전 pc에서 다음 pc의 instruction을 읽어오는 연산부터 시작이기때문에 당연히 pc로부터 instruction을 읽어오는 과정이 우선적으로 필요합니다
이 회로 3주차에서도 꽤나 많이 봤던회로죠? 간단히 설명만 하고 넘어가겠습니다
우선 pc로 부터 address를 읽어오고 그 address에 있는 값을 instruction으로 output해줍니다
그리고 동시에 ALU의 add instruction을 통해서 다음 pc주소를 pc에 넣기위해 대기해주고 다음 clock rise에 다음 pc값을 input으로 넣어주는 작업을 수행하게 됩니다
Part 2: ALU instruction(add/sub/and/or/slt)
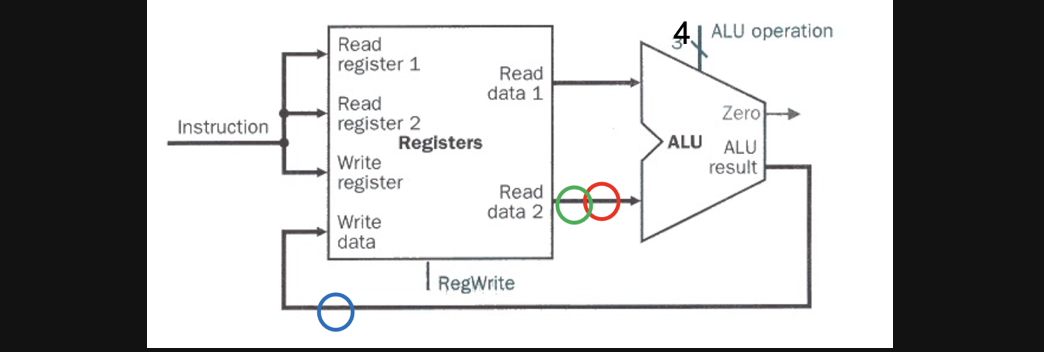
우리가 배운 ALU회로는 지금까지는 이거밖에없었으니까 이 ALU회로를 가지고 시작해봅시다
🔥여기있는 동그라미는 우선 없다고 생각해주세요🔥
Part1을 통해서 instruction이 output으로 나오게 되고 이게 ALU의 값으로 들어와야합니다
그래서 instruction이 register로 들어오게 됩니다.
간단한 예시로 아래와같은 instruction이 들어왔다고 해보겠습니다
lw $2, 4($8) 100011 01000 00010 0000 0000 0000 0100
우선 8번 register에 있는 값을 read register에 넣어주고 결국 값을 2번 register에 넣어줘야하기때문에 read register 1에 8을 넣어주면 아마 8번에 있던 data가 read data 1로 나가게되고 alu의 첫번째 operand의 input으로 들어가게 됩니다
그러면 alu에서 두번째 operand로는 뭐가들어가야할까요? instruction의 뒤에 16비트에 있는 offset이 들어가야하겠죠
하지만 위의 회로로는 alu의 두번째 operand로 offset을 넣어줄수없습니다
왜냐면 위의 그림에서 alu의 두번째 operand에는 register로부터 읽어온 값이 들어가게 설계가 되어있는데 instruction으로부터 값을 읽어오는 설계가 되어있지 않기때문인거죠
위의 그림은 단순히 register에서부터 두개의 operand를 읽어와서 연산을하는 경우에는 필요하고 맞는 회로이지만 적어도 지금처럼 lw나 sw 연산을 수행할 수 있는 회로가 아닌겁니다
part3: for lw/sw instructions
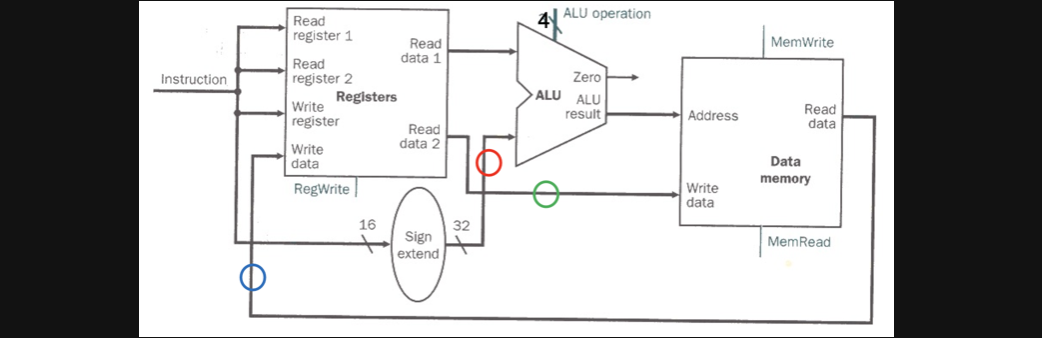
lw와 sw의 offset을 계산해주기위해선 위와같은 회로가 필요합니다
오른쪽부터 차근차근 보겠습니다
빨간색 동그라미를 보면 instruction에서 어떤 값이 sign extenstion을 거쳐서 alu의 두번째 operand로 들어가게 됩니다
그러면 8번 register의 값에서 offset을 더하는 연산이 되고 그 결과를 data memory의 address로 주고 MemeRead를 1로해주면 그 address에 있는 값을 output으로 보내주고 그 값이 파란색 동그라미처럼 Write Data로 들어가서 기존에 write register에 저장됩니다(물론 다음 clock cycle에서겠죠)
자, 여기서 한가지 고민이 생기게됩니다
part2의 ALU나 part3의 ALU나 사실 연산을 하려는건 똑같죠? input에의해서만 output이 결정되기때문에 사실 어떤값이 들어와야할지를 결정하는건 외부적인 요인인거고 ALU는 그냥 들어오는 input두개를 가지고 연산한 하면됩니다
이 말은 즉슨 하나의 통합회로에서 간단한 ALU연산이나 sw/lw를 위한 ALU연산에서 두개의 ALU가 필요가 없다는겁니다
결국은 두개의 ALU를 통합할 방법을 찾아야하고 그 힌트는 위아래그림에 그려져있는 동그란 원에 있습니다
Role of Multiplexers
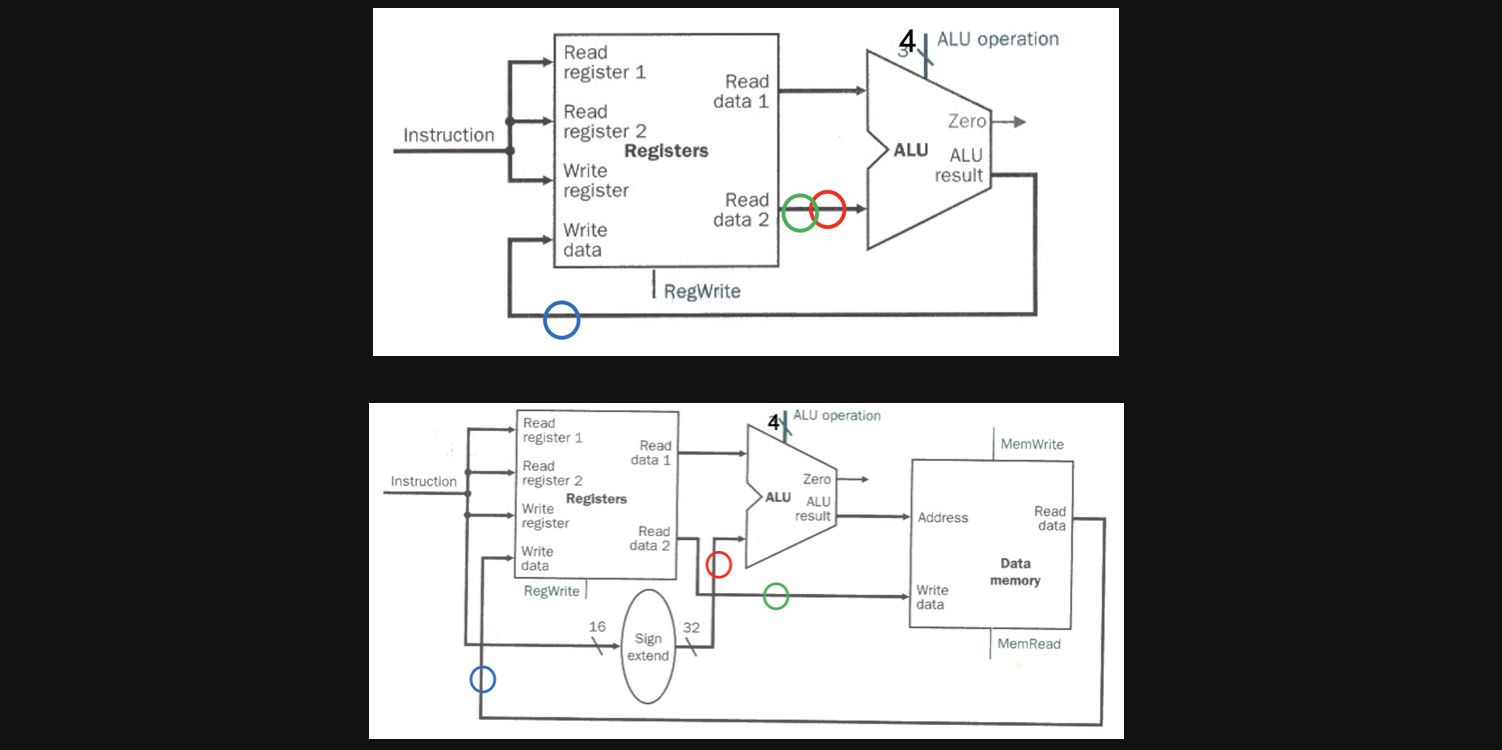
우선 순서대로 파란색 원을 한번 볼까요?
파란색원은 위아래둘다 Write Data로 이어집니다
그런데 데이터가 출발하는 지점이 다르죠 위의 그림에서는 ALU연산의 결과자체가 write할 data가 되고 아래그림에서는 ALU연산의 결과가 data memory의 input이 되어서 그 output이 write할 data가 됩니다
입력이 여러군데서 오는 경우
라고 할 수 있습니다
그러면 빨간색을 볼까요?
빨간색원도 파란색원가 마찬가지입니다 ALU의 두번째 operand가 어디에서부터 오는가이고 결국 입력되어야할 값이 여러군데서 오는 경우라고 할 수 있습니다
마지막으로 초록색 원을보겠습니다
이 친구는 조금 다릅니다 read data2라는 곳에서 동일하게 출발하지만 목적지가 다릅니다
위의 그림에서는 alu의 두번째 operand로 아래 그림에서는 data memory의 write되어야할 data로 들어가게됩니다.
서로 다른 곳의 입력이 되는 경우
라고 할 수 있습니다
ALU를 하나로 통합해야하지만 연산의 입력의 출발점이나 목적지가 한군데로 정해저야하는 경우가 발생합니다. 반대로 말하면 이런 경우를 한번에 할수있는 장치를 사용한다면 ALU를 한가지로 통합할수있게됩니다
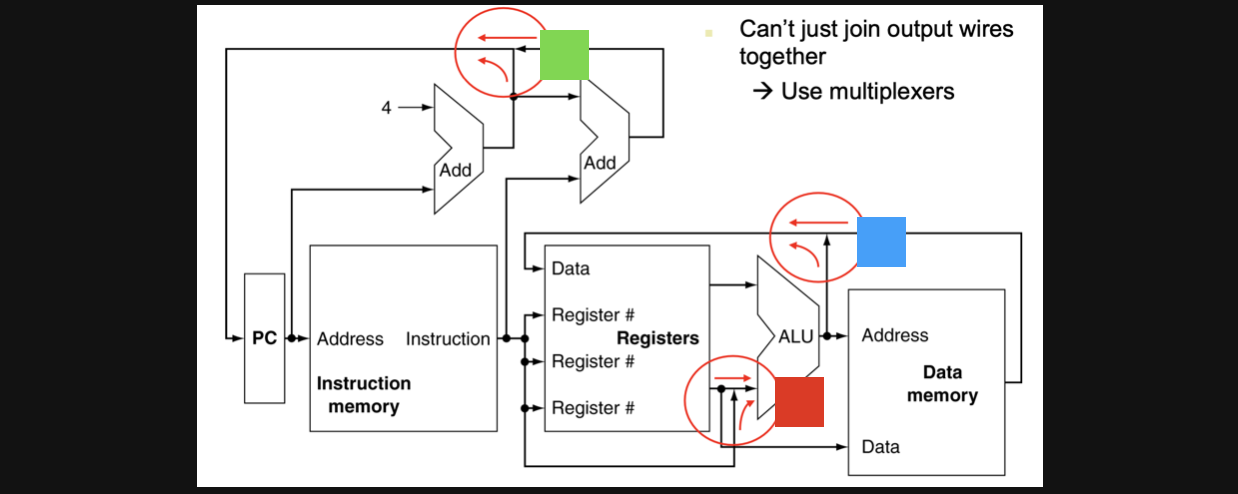
종합해보면 위와같은 그림이 될겁니다 각각의 네모의 색깔이 위에서봤던 원의 색깔이라고 생각하고 보시면 좋을거같습니다
결국 두개의 데이터가 합쳐지는것이 아니라 둘중 하나의 데이터를 선택해야하는 회로가 되어야합니다 그리고 둘중하나를 선택하는 논리회로를 우리가 이전시간에 배웠습니다 바로 multiplex입니다
multiplex 논리회로란?
input이 1,2일때 control이 0이라면 1을 output해주고 control이 1이라면 2를 output으로 해주는 회로
그렇다면 우리가 저기 원으로 표시된 부분을 multiplex회로로 만들어주면 특정상황하다 알맞는 output을 input으로 넣어주는 논리회로가 된다는걸 알 수 있습니다
즉 part2와 part3을 combining해주면 아래와같은 회로가 됩니다
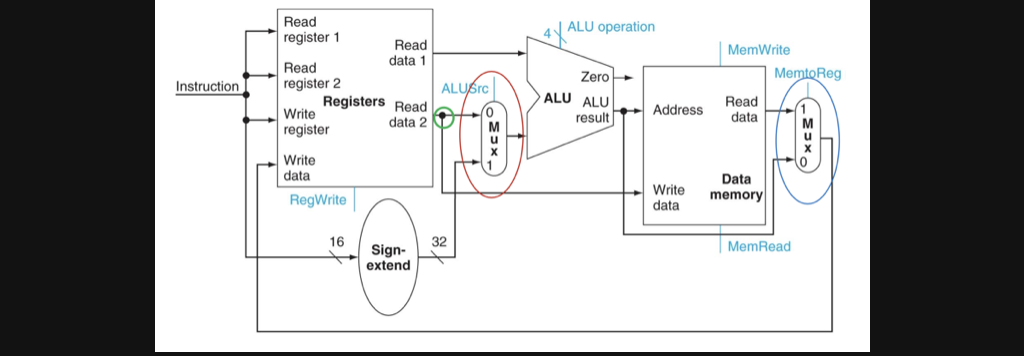
참고로 이후에 배울 내용이지만 우리가 지금은 data path를 만드는걸 배우고있는데 위의 사진에서 multiplex에 input으로 들어가거나 alu에 operator를 결정해주는 하늘색 글씨의 값들은 control이 특정 상황에 맞게 input으로 data를 넣어주는 부분입니다
바로 다음 포스팅에서 배울거니까 지금은 저 하늘색 글씨에 들어가는 숫자에따라 output이 결정되는데 그걸 control이 해주는구나~ 정도로만 알고 넘어가시면 됩니다
adding part 1
한번의 instruction이 끝나면 다음 pc주소를 통한 instruction을 받아야하기때문에 우리가 위에서 ALU를 통합한 논리회로에서 pc에서부터 instruction을 output해주는 회로를 연결시켜주면 기본적인 ALU연산과 lw/sw연산이 가능한 종합적인 논리회로가 완성됩니다
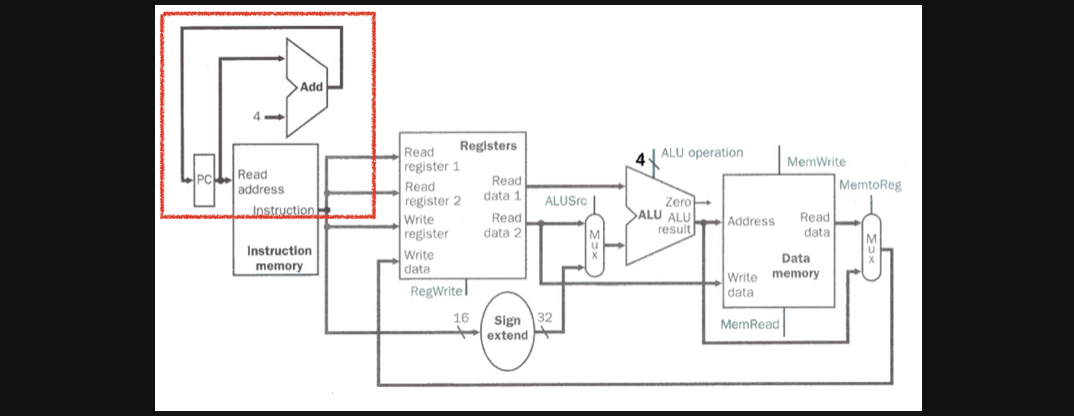
pc주소를 instruction memory에 input으로 넣어주는 동시에 다음 pc를 input으로 넣어주는 논리회로를 조합한 그림입니다
Execution of Branch Instructions
그러면 branch Instruction은 어떤 논리회로로 표현할 수 있을까요?
[0x00403000] beq $3, $4, L 000100 00011 00100 0000 0000 0000 0010
위와같은 instruction이 주어진다고 가정해보겠습니다
branch를 하기전에는 간단한 sub연산이기때문에 당연히 우리가 위에서 만들었던 논리회를 사용할 수 있습니다
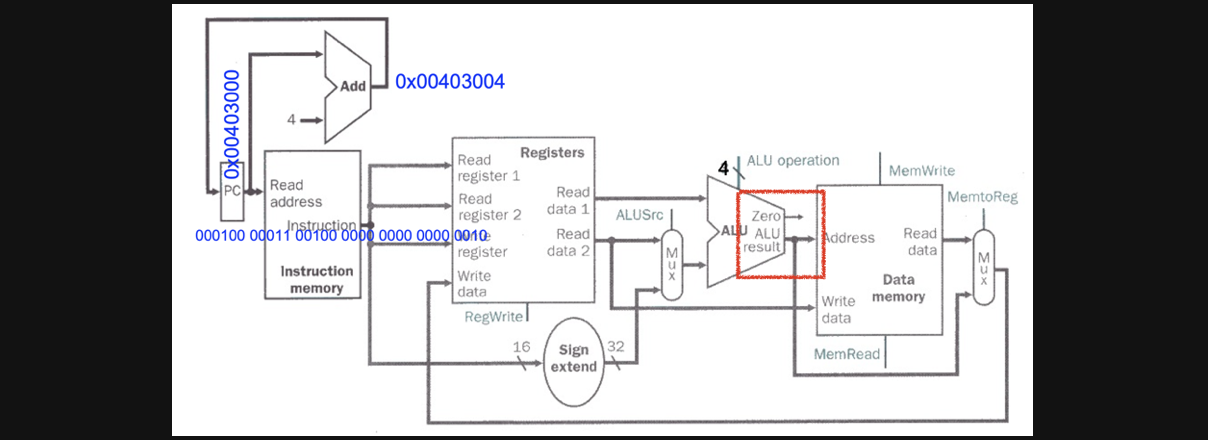
결국 초반부분은 동일합니다 rs rt에 있는 값들을 읽어서 sub연산을 ALU에서 수행해줍니다
하지만 위 그림에서 빨간색 네모를 보면 lw나 sw의 경우엔 그 결과값을 가지고 data메모리에 접근해서 값을 읽거나 쓰거나했지만 사실 beq의 경우엔 이 연산결과가 0이거나 0이 아니면 다음pc로 갈지 아니면 BTA로 갈지 pc만 업데이트를 해주고 다음 clock을 기다리면됩니다
part4: Branch Instructions
그러면 BTA로 branch하는 Instruction은 어떻게 회로로 표현할수있는지 알아보겠습니다
[0x00403000] beq $3, $4, L 000100 00011 00100 0000 0000 0000 0010
beq의 경우에 BTA를 어떻게 구했는지 2주차 포스팅에서 다시 가져와봤습니다

- sign extension을 해준다
- 곱하기 2^2를해준다(= 왼쪽으로 두칸 옮겨준다)
이렇게 두번의 연산을 거치면 되는거니까 논리회로로 구현해보면
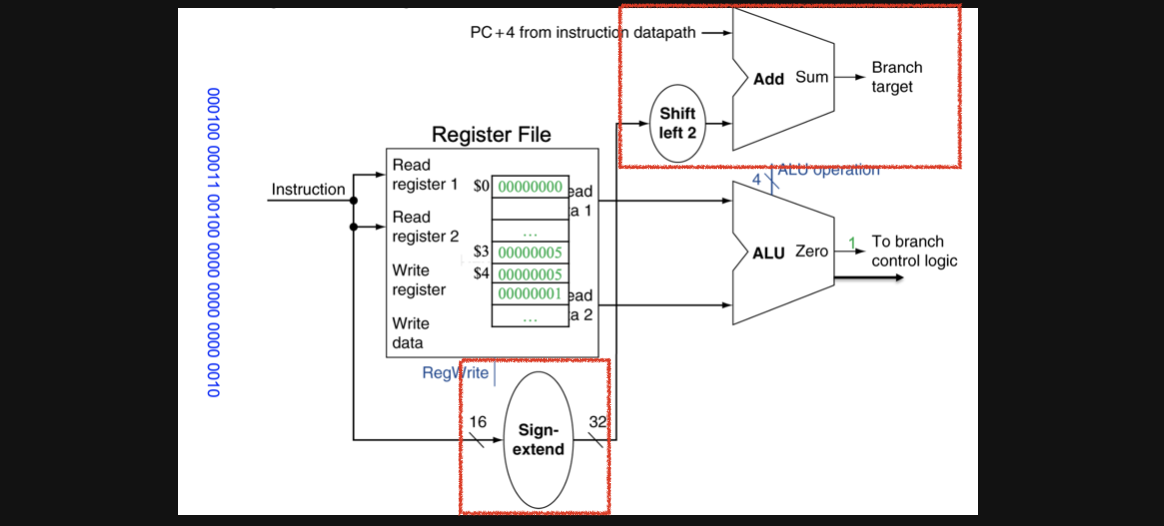
기존에 register에서 두개의 값을가지고 ALU의 input으로 넣어주는 회로에 BTA를 계산해주는 빨간색 네모 회로를 추가했습니다
instruction에서부터 뒤의 16bit를 sign extension해주고 shift left 2칸 해주고 그 값을 현재pc(spim에선 이렇게했는데 실제로는 현재 pc+4에서 시작한다고하네요 편의상 현재pc라고 설명하겠습니다)의 값과 add연산을 해주면 branch할 pc의 주소가 나오고 그 값을 instruction memory에 넣어주면 됩니다.
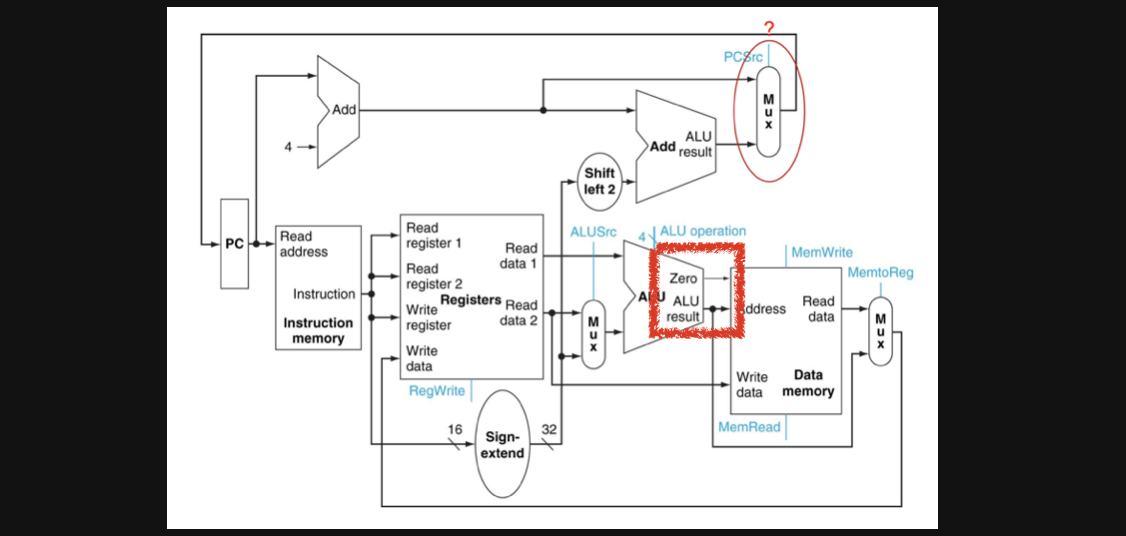
그러면 우리가 다음 pc주소로 갈지 BTA로 갈지 둘중 하나를 선택해야하니까 multiplex로 결정을 해주면 됩니다
multiplex는 결국 어떤걸로 결정되나요?
라는 의문이 드신분들도 있을거같습니다
사실 우리가 두 register의 값을 뺀 결과를 가지고 BTA로 갈지 다음 pc로갈지를 결정하는것이기때문에 위의 사진에 빨간색 네모의 Zero에 의해 결정됩니다(with control, 하지만 control과 연결되는 부분은 다음 포스팅의 control에서 설명해서 실제로 연결은 안되어있는 그림입니다)
뺀값이 0이라면 Zero에 1이 output되고 0이 아니라면 0이 output되어서 이걸기반으로 control이 위 그림의 빨간색 동그라미부분의 multiplex의 값을 결정해서 BTA와 다음 pc 둘중에 하나로 결정되게 됩니다
Full DataPath
위의 모든 연산을 할 수있는 DataPath의 전체적인 그림입니다
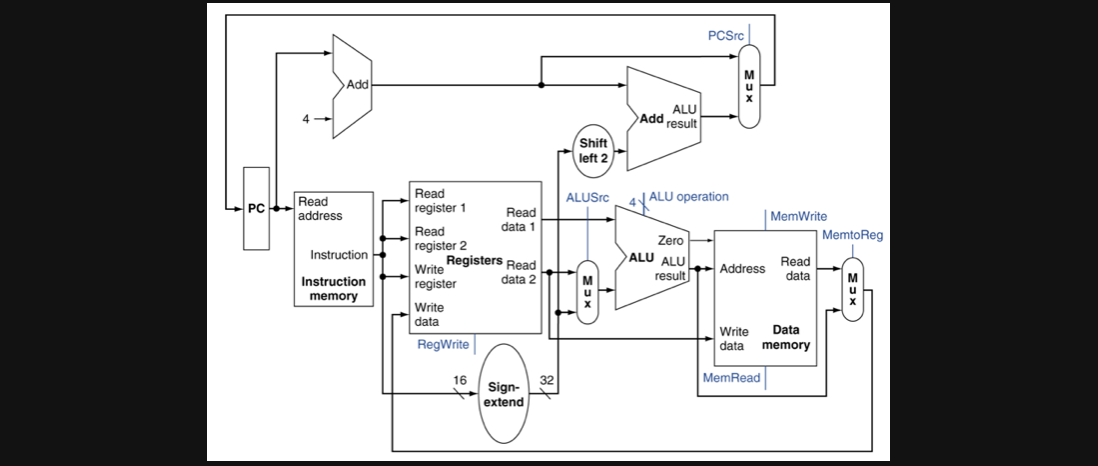
그리고 이 회로가 전체적인 컴퓨터의 관점에서 보면 아래와같은 역할이 하는 회로로 분리해서 확인 할 수 있습니다
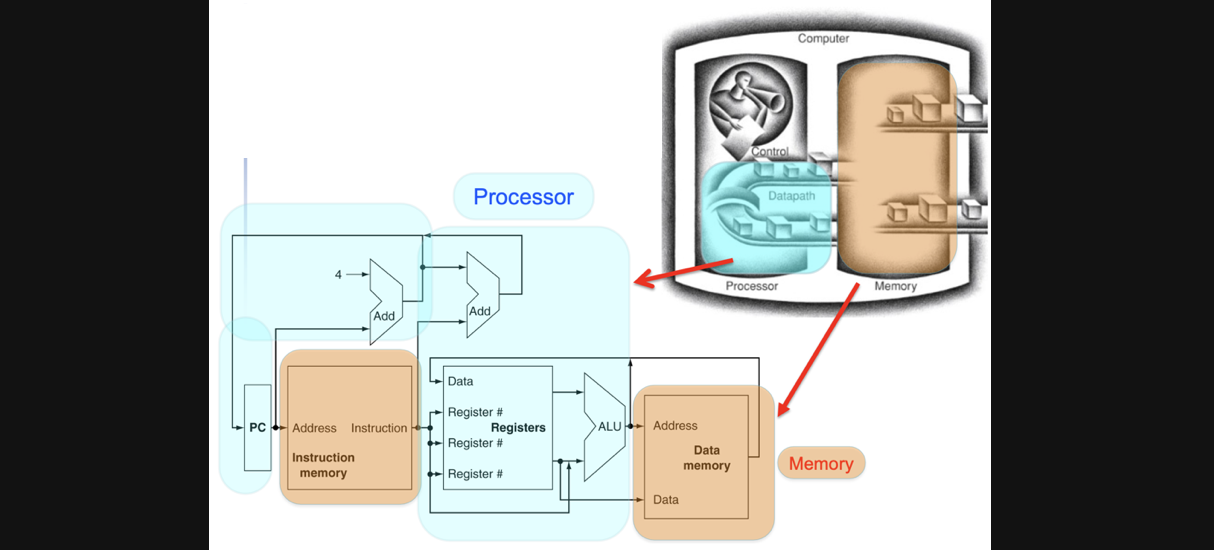
part5: destination register
하지만 위에있는 datapath에서 한가지를 더 고려해줘야 최종적인 논리회로가 완성됩니다
언제까지 최종일건데...

이젠 정말 찐찐찐 최종입니다 ㅎㅎ.....
지금까지 봤던 assembly text를 한번 생각해보시면 늘 rd가 있지않았던거 기억하시나요??? 혹시 기억이 안나신다면 이전 포스팅들을 쭉한번 보고 오시면 어떨때는 destination register의 역할을 rd없이 rs가 할때가 있습니다 그러다보니 rd의 역할을하는 write register를 rs가 할지를 결정해주는 multiplex가 하나 더 필요합니다
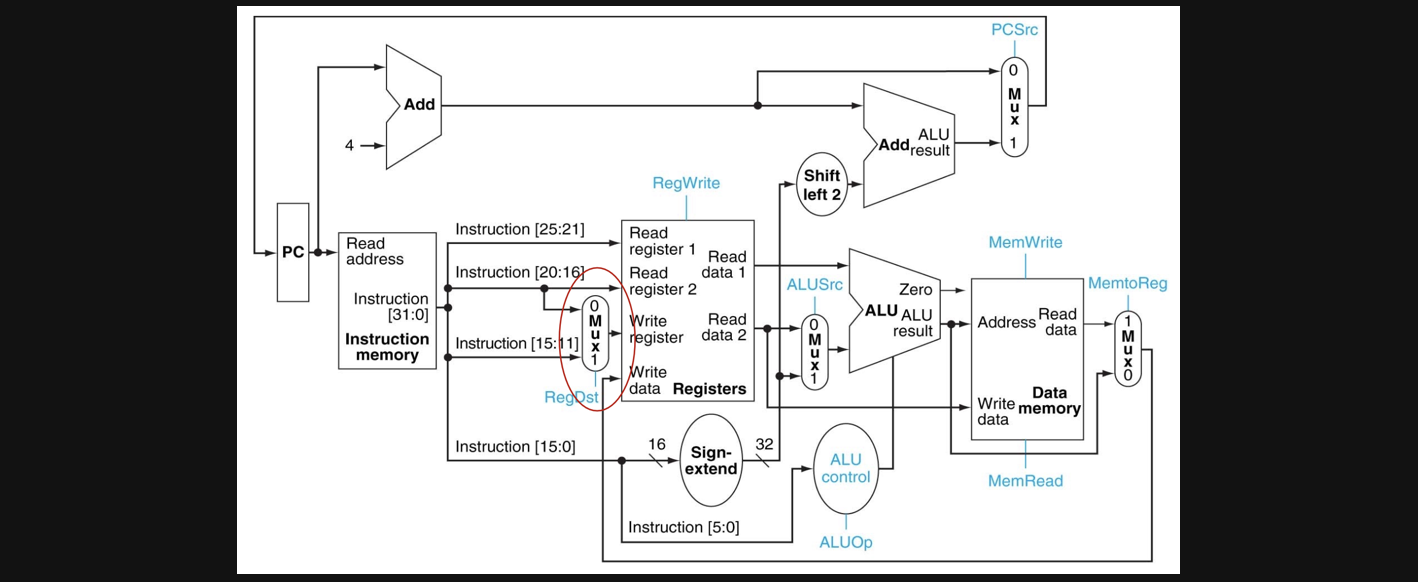
위 그림처럼 register의 write register를 rd로 할지 rs로 할지를 결정해주는 multiplex를 넣어주면 정말 찐찐찐 최종의 dataPath가 완성됩니다!
이로써 processor의 내용을 마무리했습니다!

정말 뿌듯 그잡채네요
사실 엄청 어려웠다기보다는 지금 있는 논리회로의 디자인이 이러한 이유로 이렇게 되었다는 그 흐름을 파악하는게 중요했다고 생각합니다
제가 포스팅하는 내용을 쭉보시면 뭔가 큰 흐름을 가지고 설명하는 느낌이라서 핵심만 촥촥 뽑아서 설명하는 느낌이 아닐겁니다
이유라고 하면 무언가를 공부할때 그 큰 흐름에는 반드시 이유가 있고 스토리가 존재한다고 생각하기도하고 그 스토리를 이해하면 전체적인 그림이 자연스럽게 습득(?)이 된다고 생각하기도 하거든요
그래서 핵심만 요약하는것보단 시간이 2배~3배가 걸리지만 앞으로도 쭉 이렇게 정리를 해볼 예정입니다
전공책을 기반으로 정리하는 글이기때문에 나름대로 최대한 이유가있는 설명을 한다고는하지만 분명히 틀리거나 추가로 들어가야할 내용이 있을수있기때문에 언제든지 댓글로 알려주세요!
그럼 20000!!!!

큰 틀을 알고 싶었는데 이해가
너무 잘 돼요 정말 감사합니다😭