본 시리즈은 비전공자가 공부한 computer science, 그중에서도 컴퓨터구조를 정리한 글입니다. 틀린내용이 있다면 댓글로 알려주시면 정말정말 감사하겠습니다. 참고한 책은 Computer Organization and Design MIPS Edition입니다
오늘은 Control에 대한 내용을 정리하는 포스팅입니다
요즘은 아침 7시에는 컴퓨터 앞에 앉아서 cs와 알고리즘 공부를 시작하려하는데 역시 습관을 바꾸는게 제일 어렵다는 생각이 드네요...

그래도 이번주 cs의 마지막 포스팅이니까(저번주랑 저저번주는 무려 3개였죠...) 힘내서 시작해봅시다
CPU Overview
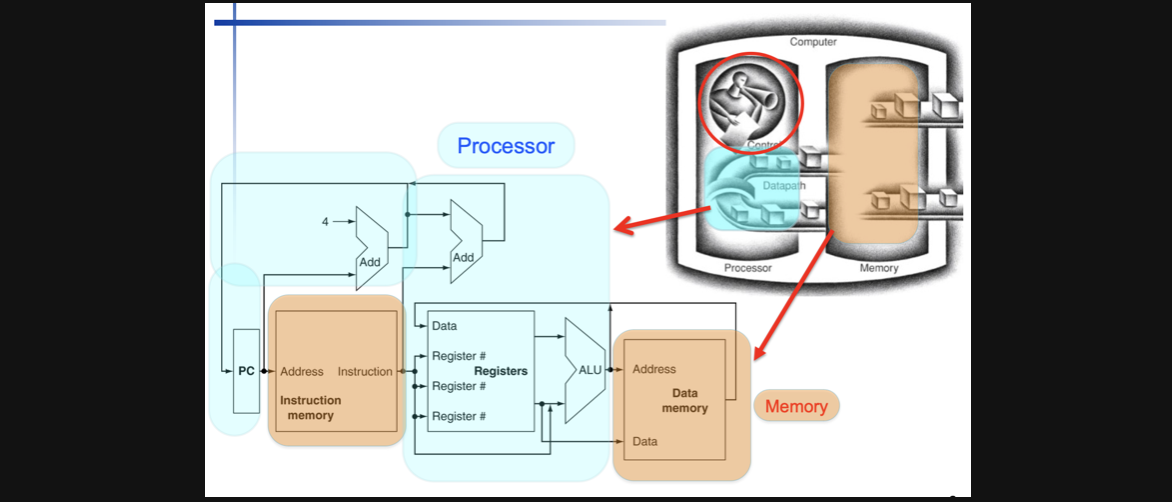
본격적으로 Control에 대한 내용을 알아보기전에 Control은 무슨역할을 하는지 간단하게 알아보고 넘어가보죠
우리가 저번 포스팅에서 배운건 datapath였습니다
여러가지 data가 논리회로를 거쳐서 특정 instruction을 수행하게되는데요
그 과정에서 여러 종류의 instruction을 수행하기위한 하나의 통합된 datapath를 완성했고 그 datapath에는 여러개의 multiplex가 존재했습니다
multiplex가 필요했던 이유는 다양했습니다
input을 결정해야하는 경우, output을 어느 input으로 넣어야할지 결정하는 경우, rd를 결정하는 경우 등등...
이것 외에도 사실 ALU의 연산종류를 결정해야하는 경우, 데이터를 read할지 write할지를 결정해야하는 경우, branch를 해야할지를 결정하는경우에 하나의 결정을 해줄수있는 장치가 필요했었습니다
결론부터 말씀드리면 위의 모든 경우에 결정을 내려줄 수 있는 장치가 Control입니다
Control이 무슨역할을 하며, 왜 필요한지에 대한 스토리를 이해하셨을거라고 생각하고 본격적으로 알아보겠습니다

Architecture
그 전에 잠깐 알아두고 가면 좋은 개념이 있습니다
바로 Harvard Architecture와 Von Neumann Architecture인데요
편의상 하버드아키텍쳐와 폰노이만아키텍쳐라고 하겠습니다
하버드아카텍처는 같은 메모리에서 instruction과 data연산을 수행하는 아키텍처입니다
A single set of address/dtat buses between CPU and memory
라고 설명할 수 있습니다
폰노이만아키텍처는 서로다른 메모리에서 instruction연산과 data연산이 발생합니다
지금까지 우리가 봐왔던 논리회로가 폰노이만아키텍쳐입니다
insturction 연산과 data연산을 다른곳에서 했으니까요
Two sets of address/data buses between CPU and memory
알쓸별잡에서 김상욱교수님이 폰노이만 아키텍처에 대한 이야기를 했었는데 그게 떠올라서 흥미로웠던 기억이 나네요
Control
Roles of Instruction Fields
control에 input은 당연히 instruction의 일부일것이고 그로인해 control의 output이 결정되기때문에 한가지 instruction을 읽는 방법에 대해 알아둘 필요가 있습니다

간단합니다 숫자가 뒤에서 부터 시작한다는겁니다
그리고 control은 어떠한 연산일때는 각각의 multiplex의 control input을 어떤 값으로 해야할지가 정해져있기 때문에 기본적으로는 op field인 31:26에 의해서 output이 결정됩니다
이건 제가 생각을 좀 해봤는데
당연히 op의 값을 가지고 어떤 연산을 해야한다면 결과가 하나가 나와야하고 그 결과를 얻기위해 여러가지 multiplex의 control input과 write read의 control input이 결정해야하기때문인거같아요
Execution of Arthmeitc/Logic Instructions
전체적인 그림을 통해서 ALU의 control input이 어떻게 결정되는지를 알아보겠습니다
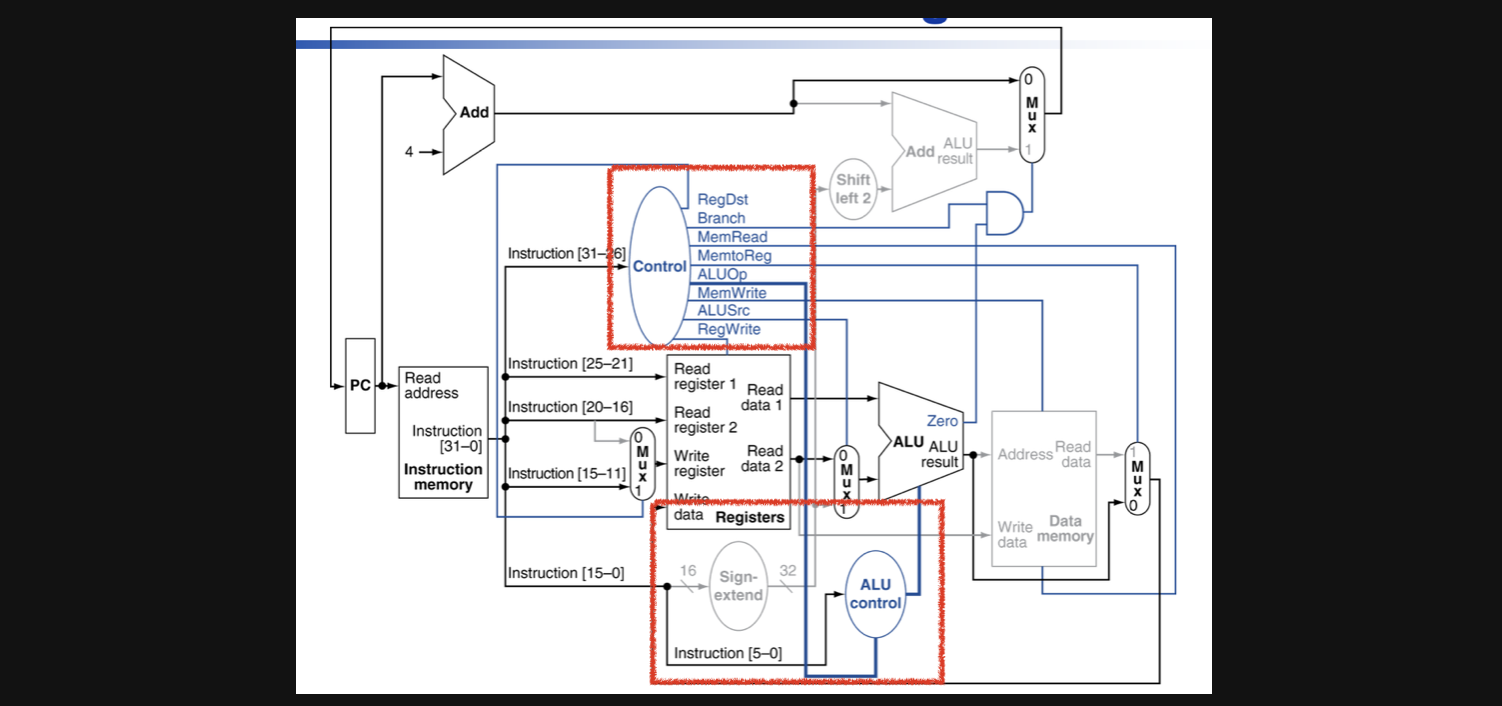
위의 그림이 전체적인 datapath에서 controll을 추가한 그림인데요 instruction에서 op인 31-26의 bit를 input으로 받아서 여러가지 경우의 control input을 output해주는 모습입니다
그중에서도 ALU의 연산을 어떻게 결정하는지를 보겠습니다
우선 우리가 ALU의 연산을 결정하는 방법에는 크게 두가지가 있었습니다
R-format의 경우엔 op field와 function field 두가지가 필요했고 나머지 format에서는 op field만 있으면 연산이 결정되었습니다
그래서 맨 위의 control을 보면 우선 op field의 값을 가지고 output을 해주고 그 값과 instruction[5-0]인 function field의 값을 input으로 받아서(총 input이 두개) 하나의 output이 ALU control으로 나가서 ALU의 operator가 결정됩니다
전체적인 흐름을 하나의 instruction을 기준으로 따라가봅시다
add $2, $8,$9 000000 01000 01001 00010 00000 100000
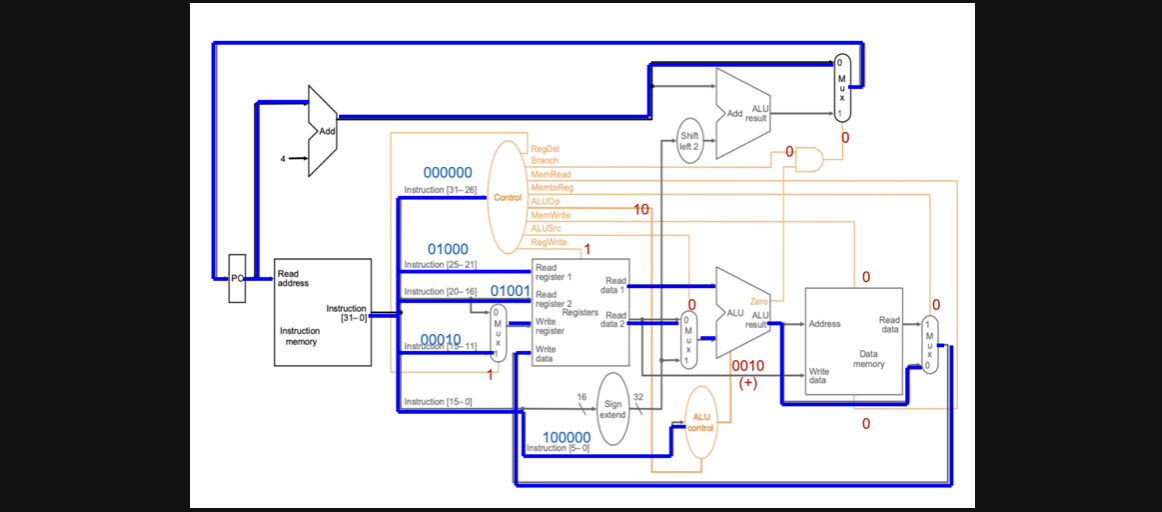
가장먼저 op field가 000000이기때문에 연산을 위해 필요한 control input이 결정됩니다(빨간글씨로 적혀있는 부분이 op field로 인해 결정된 control input입니다) 그리고 add연산의 경우엔 function field가 존재하기때문에 function field의 bit도 input으로 들어가서 0010이라는 control input이 ALU에 들어가서 add연산을 수행하게 됩니다
이 경우엔 당연히 branch instruction이 아니기때문에 pc주소는 단순히 4를 더한 다음 pc주소가 pc의 input이 됩니다 맨위의 mux(multiplex)가 0이기때문에 branch된 pc가 아니라 다음 pc주소가 다음 pc주소가 됩니다
ALU operation을 위한 진리표는 아래와 같습니다
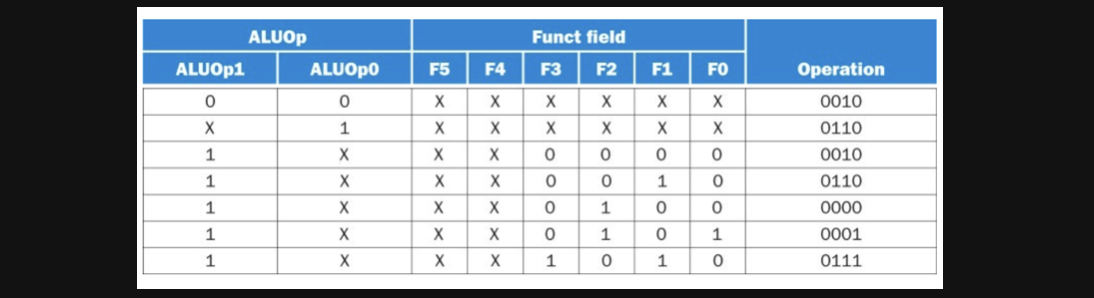
여기보이는 X는 don't care인데 0이어도 되고 1이어도 된다는 뜻입니다
이게 어떤 의미인지는 조금이따가 설명드리겠습니다
사실상 0과 1중 어떤값이 들어와도 큰 상관은 없다고 합니다
Execution of lw Instructions
그렇다면 lw instruction의 전체적인 flow는 어떻게 될지 따라가보겠습니다
lw $2, 4($8) 100011 01000 00010 0000 0000 0000 0100
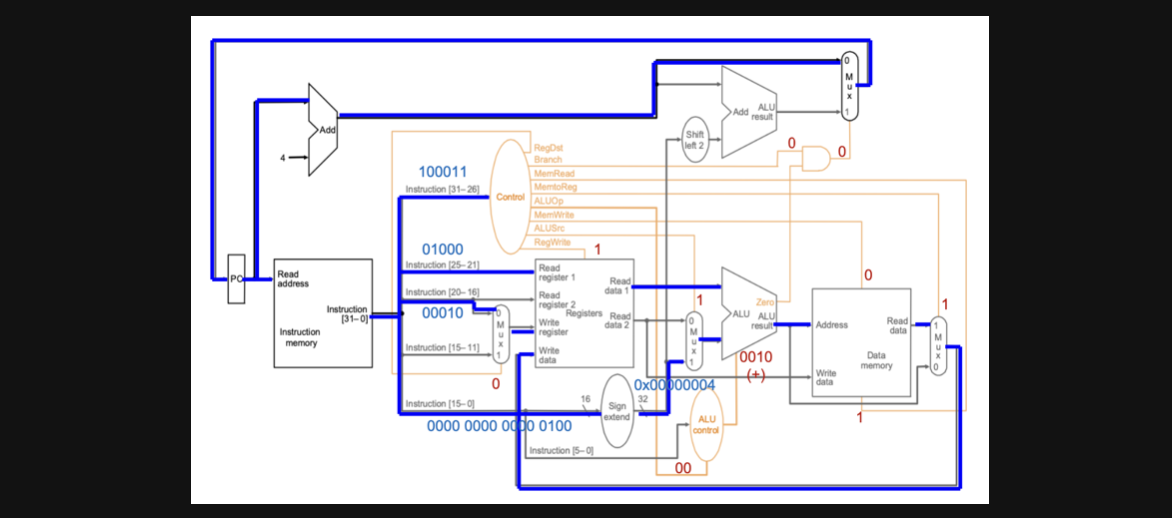
우선 lw의 op의 값에 따라서 control input이 결정되고 연산에 따른 data path가 결정됩니다. 그리고 이 경우엔 lw라 function field가 없어서 op만으로도 ALU의 operator가 결정되겠네요
그렇다면 ALU를 통해 load할 데이터의 주소가 결정되고 offset을 add연산하고 그 결과를 data memory read해서 register의 write data로 넣어주면 다음 clock에 데이터가 rd에 저장되게 됩니다
Execution of branch Instructions
마지막으로 branch instruction의 전체적인 flow와 진리표에서의 x의 의미를설명드리겠습니다
beq $3, $4, L 000100 00011 00100 0000 0000 0000 0010
위의 코드가 있다고 가정하고 전체적인 flow를 보기전에 beq를 연산하는 부분만 집중적으로 보겠습니다
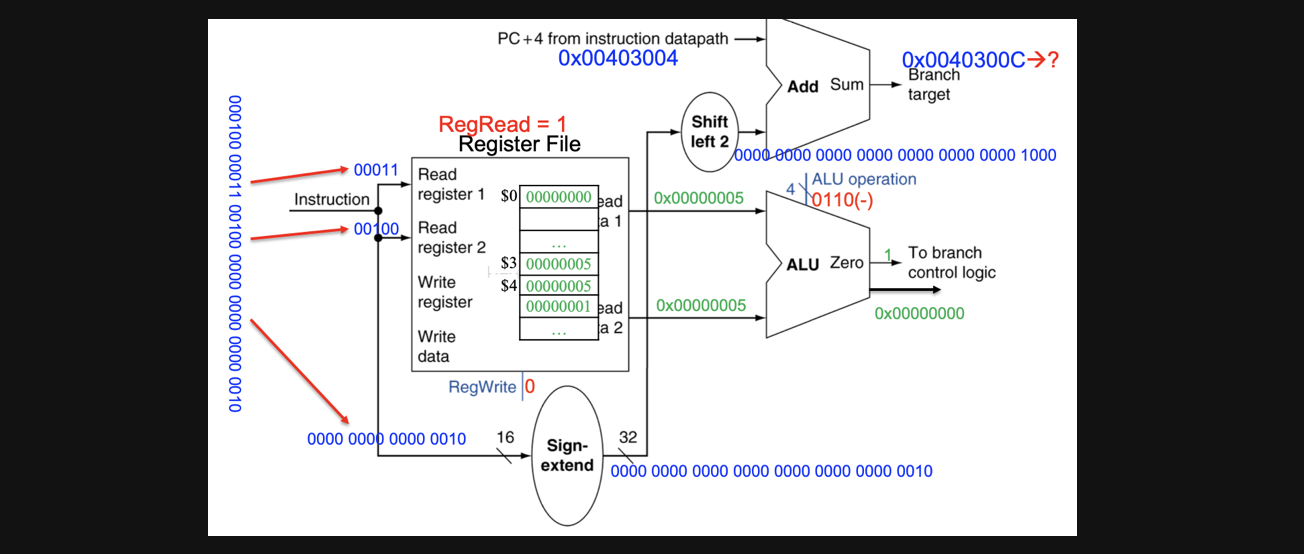
우선 두개의 register값을 비교해서 0인지 1인지를 ALU의 output으로 던져주고 현재 pc주소와 연산해서(sign extension + shift left 2) ALU의 output이 1이면 branch할 BTA를 계산해줍니다
이 흐름이 beq의 연산자체의 flow였습니다
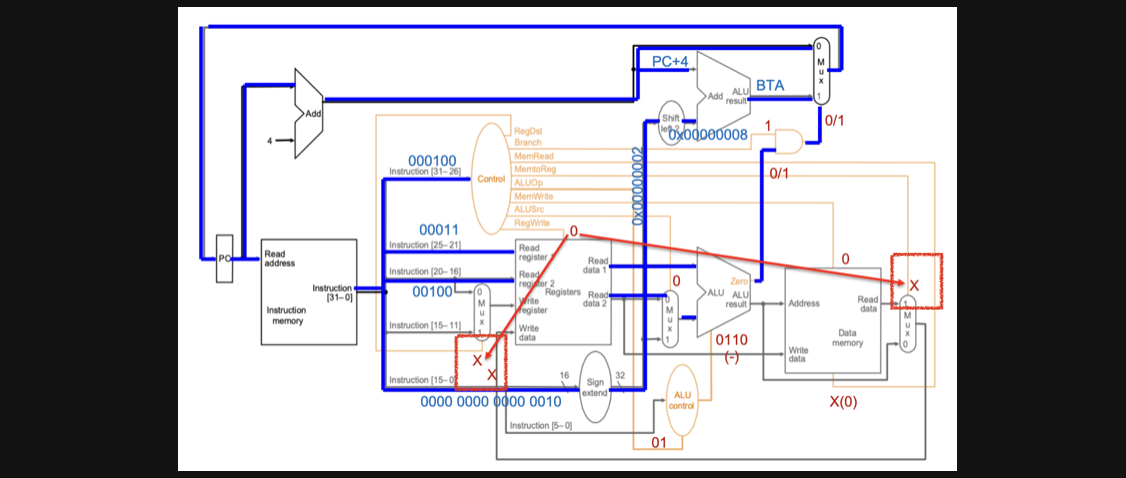
전체적인 flow를 보겠습니다 드디어 x에 대한 내용이 나오는데요
x는 0이나 1이나 아무상관이없다라는 뜻이기도 합니다 왜일지를 생각해보겠습니다
가장 왼쪽네모에 있는 x는 왜 아무값이어도 상관이 없을까요???
맨 왼쪽 네모에있는 control input은 어떤 역할을 하는지를 보면 우선 destination register를 rd로 할지 rs로 할지 결정하는 multiplex의 control input이고 그 안에있는 두번째 x는 저장될 data입니다
그런데 beq에서 destination register가 필요한가요? 저장할데이터가 필요한가요?라고 물어보면 여러분들은 이제
아니요!
라고 답하실겁니다
즉, flow상 해당 flow를 거칠일이 없기때문에 그 flow에 있는 control input은 x로 표현해도 아무런 상관이 없는겁니다
그리고 나서 전체적인 flow를 다시보겠습니다 결국 두 register의 값을 비교해서 sub연산을 통해 나온결과가 0이라면 zero를 통해 1이라는 값이 output되게 되고 그것이 control의 branch와 AND연산을 하게됩니다
이때 beq라면 branch input control이 무조건 1로 고정인데 이는 AND연산에서 ALU연산의 결과 = branch할지말지 이기때문에 1로 고정되는거라고 이해하시면 될거같습니다
그래서 ALU연산의 결과에 따라서 BTA로 갈지 다음 pc주소로 갈지가 결정됩니다
당연히 오른쪽 네모의 x또한 data memory의 flow를 거칠일이없기때문에 x로 표시가 가능합니다
✅ 9월 3일 update!
jump instruction
지난 포스팅에서 누락된 부분이 있어서 추가로 업데이트합니다
우리가 지금까지 기본적인 연산(add,sub,multiply,divide)이나 beq혹은 lw, swr같은 연산을 수행할 수 있는 single cycle의 논리회로를 구성해봤는데요
한가지 더 추가해야할 경우가 있습니다
우리가 배웠던 jump instruction이 필요합니다
그래서 jump를 할지말지 또한 결국은 control이 정해줘야하기때문에 control의 output으로 jump를 추가해주고 jump의 BTA를 결정할수있는 연산을 수행할수있도록 논리회로를추가해주겠습니다
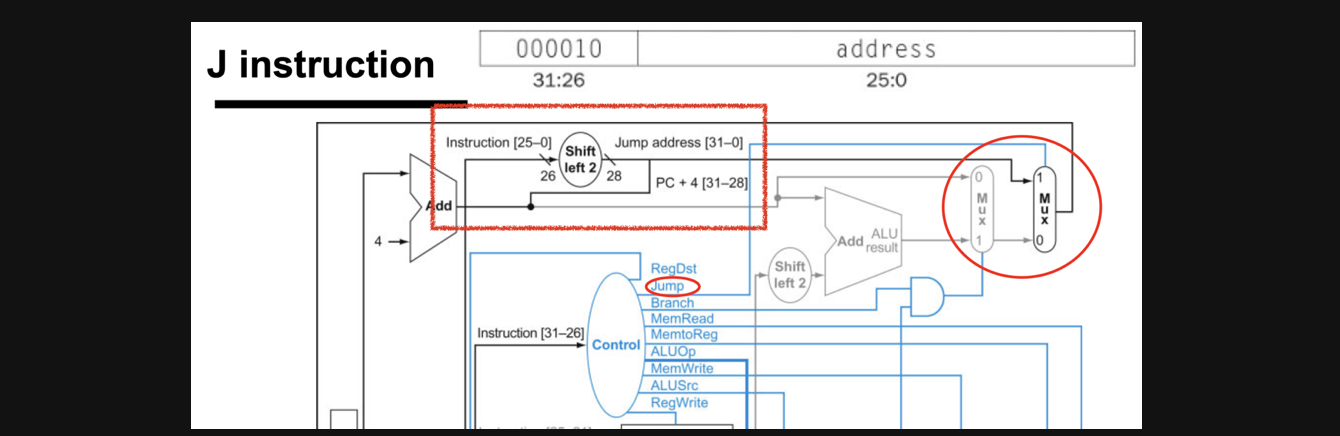
그림을 보고 차근차근 따라가 보죠
우선 control의 output에 jump관련한 bit가 추가되었습니다
쭉 따라가보면 새로운 mux의 output을 결정해주는 control input으로 들어가네요
여기서는 바로 왼쪽에 있는 mux에서 다음 pc로 갈지 beq의 branch로 갈지를 결정한 결과와 mux의 output과 함께 input으로 같이 들어가게됩니다
그래서 jump control input이 1이라면 jump BTA로 가게되고 0이라면 이전 mux의 결과로 pc주소가 결정되게 됩니다
이번에는 빨간색 네모를 보시면 jump instruction의 BTA가 어떻게 결정되는지를 보여주는데요
우선 jump instruction의 뒤의 25비트를 shift left 2연산을 해주고 기존pc주소의 앞에 4bit를 단순이 앞에 붙여준 결과가 mux의 input으로 들어가게 됩니다
이렇게 jump관련한 control을 넣어주면 이제야 비로소 우리가 배웠던 모든 연산이 가능한 논리회로 구성이 완료됩니다
Our Simple Control Structure
Control을 마무리하는 section입니다
지금까지 배웠던 개념들을 총 정리해보고 다음 주제로 넘어가기전까지의 스토리라인(밑밥이기도하죠)을 말씀드리겠습니다
우선 첫번째는 모든 control logic은 combinational하다는점입니다
이게 무슨뜻이냐면 우리가 control은 진리표를 통해서 알수가 있었죠
즉 input에 의해서 output이 겨정되는 combinational 회로라는점입니다
두번째는 register와 memory는 한 cycle이 끝날때 써진다는 점입니다
한 cycle이 끝난다는건 rising edge라는 말과 일맥상통하기때문에 결국 한번의 연산이 한 cycle안에 끝나야한다라는 규칙또한 도출해낼 수 있습니다
Performance of Single Cycle Machines
만약에 instrution fetch를하는데 걸리는 시간과 register를 read하는데 걸리는 시간같은 연산을 하는데 걸리는 시간이 동일하다고 가정해보겠습니다
그렇다면 아래와같은 표를 통해서 총걸리는시간(total time)을 계산할수있게됩니다
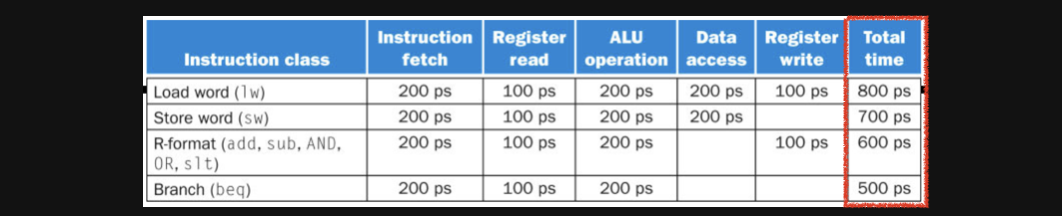
결국 하나의 instruction을 수행하기위해서는 정해진 수행시간이 필요하게되고 연산의 갯수가 많아지면 total time들이 더해져서 전체적인 시간이 결정되게됩니다
사실 이렇게 연산이 4~5개정도있는 경우엔 눈깜짝할사이에 연산이 끝나겠지만
프로젝트 파일이 몇백개가 넘고 코드가 몇만줄이 넘어간다고 생각하면 이렇게 직렬식으로 하나의 instruction이 끝나야 비로소 두번째 instruction이 시작되는 single cycle방식은 당연히 수행속도 측면에서 단점이 생길수 밖에 없습니다
그렇기때문에 pipeline기법이 등장하게 되고 이를 통해 processor의 instruction 수행속도를 향상시킬수있게됩니다
다음 포스팅 부터는 pipline에 대한 내용으로 찾아뵙겠습니다!
Control을 정리하면서 느낀거지만 우리가 지금까지 어떤 연산이 논리회로상에서 어떤 flow로 결과가 도출되는지를 공부하면서 필요한 결정들을 해주는 역할을 한다는 느낌이 들더라고요
그래서 실제 컴퓨터 그림에서 사람이 datapath를 보면서 돋보기를 들고있는 모습으로 표현을 하지 않았나라는 생각이 들었습니다
4주차 내용도 이렇게 마무리가 되네요!
전공책을 기반으로 정리하는 글이기때문에 나름대로 최대한 이유가있는 설명을 한다고는하지만 분명히 틀리거나 추가로 들어가야할 내용이 있을수있기때문에 언제든지 댓글로 알려주세요!
그럼 20000!!!!
