본 시리즈은 비전공자가 공부한 computer science, 그중에서도 컴퓨터구조를 정리한 글입니다. 틀린내용이 있다면 댓글로 알려주시면 정말정말 감사하겠습니다. 참고한 책은 Computer Organization and Design MIPS Edition입니다
안녕하세요! Virtual Memory라는 주제로 돌아온 킴스캐슬입니다
이제 이 포스팅을 끝내면 단 하나의 포스팅을 남겨놓고있네요(감회가 새롭...)
오늘은 주저리주저리하기보다는 빠르게 시작해보겠습니다
Virtual Memory
virtual memory라는 말을 해석해보면 가상메모리라고 해석할 수 있습니다
말그대로 실제로 존재하는 메모리가 아니라 가상으로 존재하는 메모리입니다
우선 전체적인 그림을 한번 볼까요
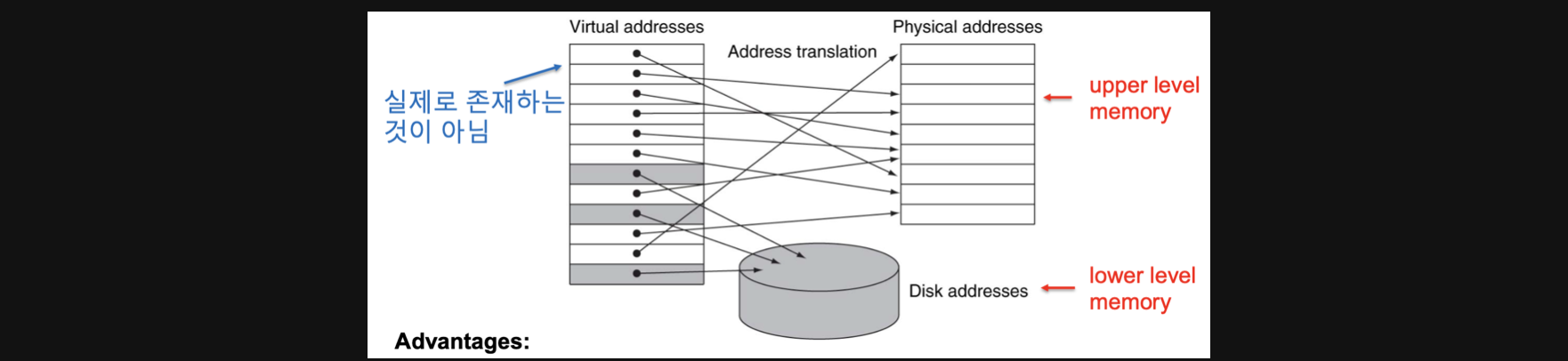
뭔가 화살표도 그렇고 원기둥도 보이고 복잡복잡하죠?
모두다 설명드릴거기때문에 우선 저런게 있나보다 정도로 하고 넘어가시면됩니다
virtual addresses라는 표가 보이는데 가상주소?를 담는 표인거같네요 그리고 이게 우리가 배우는 virtual memory인거같습니다 그리고 화실표를 보니까 virtual addressess표에서 disk addressess와 physical addressess라는 곳으로 데이터를 access하는 흐름인데 중간에 또 address translation이라는것도 보이네요...
참 어렵지만 하나하나 알아봅시다
우리가 cache를 배울때 upper는 cache고 lower가 main memory였죠?
Virtual Memeory에서는 upper가 main memory고 lower가 second storage인 모습입니다
second storage는 SSD나 하드디스크를 의미합니다
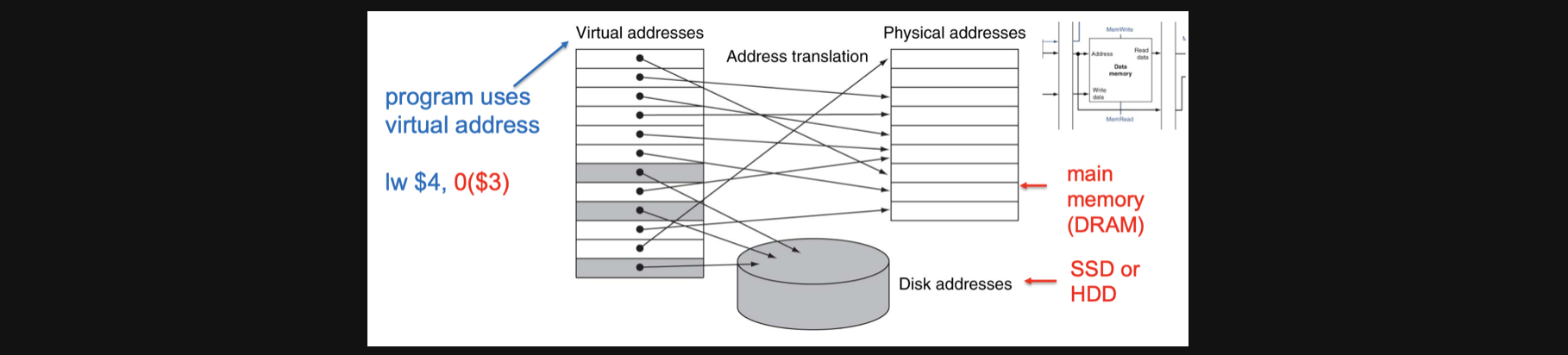
예를 들어서 우리가
lw $4, 0($3)
이라는 instruction이 있을때
3번 register에다 0이라는 offset을 ALU add연산을해서 메모리의 주소를 구했던거 기억하시나요?
하지만 이렇게 구한 메모리 주소는 실제, 물리적인 메모리의주소(physical address)가 아니라 가상의 메모리주소였습니다
그렇기 때문에 이렇게 구한 가상메모리주소를 실제 메모리주소로 바꾸기 위한 방식이 필요한거고 그 방법이 아직은 뭔지 모르겠지만 address translation이라는 친구입니다
이렇게 하면 실제 물리적 메모리공간보다 더 큰 size의 메모리를 가진것처럼 동작할 수 있습니다
Pages: virtual memory blocks
그전에 우리 Virtual memory에서의 용어정리를 잠깐 하고 넘어가겠습니다
우리가 lower에서 upper로 데이터를 copy할때 cache에서의 단위를 block이라고 했었죠
virtual memory에서는 page라고 부릅니다
그리고 upper에 index의 valid가 0인경우를 우리가 miss라고 했는데
virtual memory에서는 page fault라고 합니다
page fault의 경우 miss일경우 panalty가 매우 큽니다
왜냐면 secondary storage에서의 copy는 매우 느리기때문입니다
그렇기때문에 page자체가 매우 큰용량을 가지고 있습니다(4~16KB)그래야 spatial locality를 이용해서 miss ratio를 줄일 수 있기때문이죠
그렇다면 page에서 아주 큰 데이터를 들고있기때문에 page내에서 단위데이터를 구분할수있는 offset이있어야합니다 그리고 이 offset의 bit수를 알면 page의 크기를 역추적할 수 있겠죠
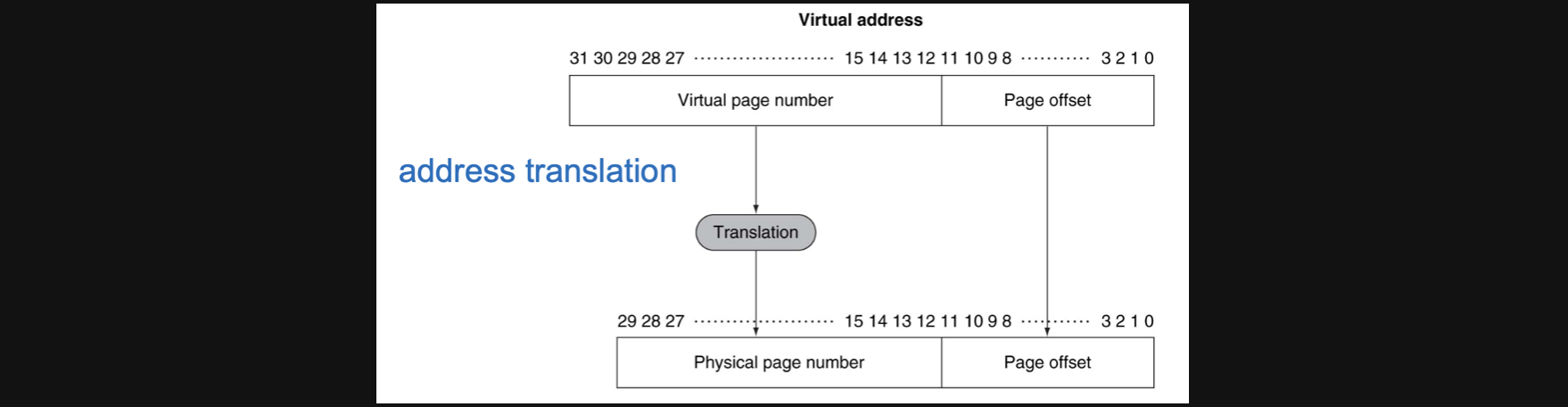
예를들어서 virtual address에서 page offset이 12bit라는건 2의 12제곱 byte크기의 page를 가지고있다고 계산할 수 있습니다(4KB겠네요)
Analogy between cache and VM
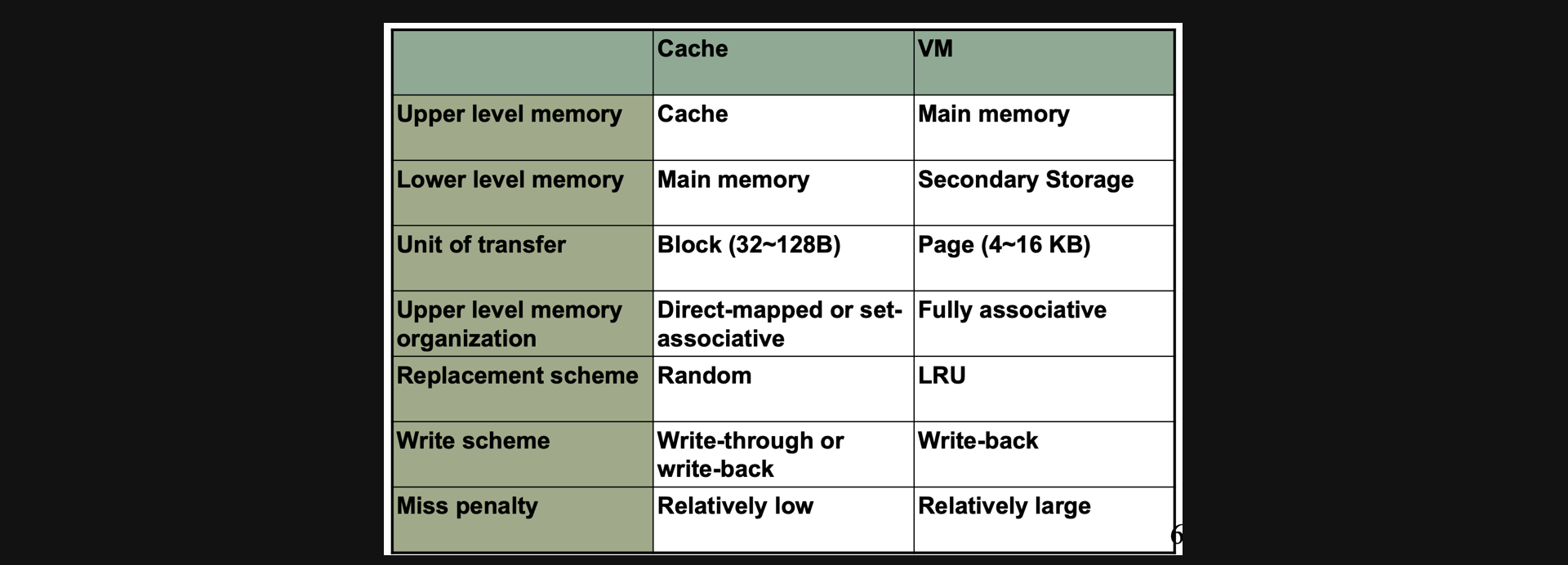
cache와 VM을 비교해보면
우선 upper level과 lower level의 메모리가 다릅니다 그리고 우리는 copy되는 단위를 cache에서는 block, VM에서는 page라고 부릅니다
또 우리가 upper level memory를 구성하는 방식이 cache에서는 direct mapped나 set associative방식 두개였는데 VM에서는 miss ratio를 최대한 줄여야하기때문에 fully associative방식을 사용합니다
그리고 확률적으로 조금이라도 miss ratio를 줄일수있는 LRU방식으로 데이터를 replace합니다
Page Table
VM이 없다고 가정하면 어떤 방식으로 address translation이 일어날까요?
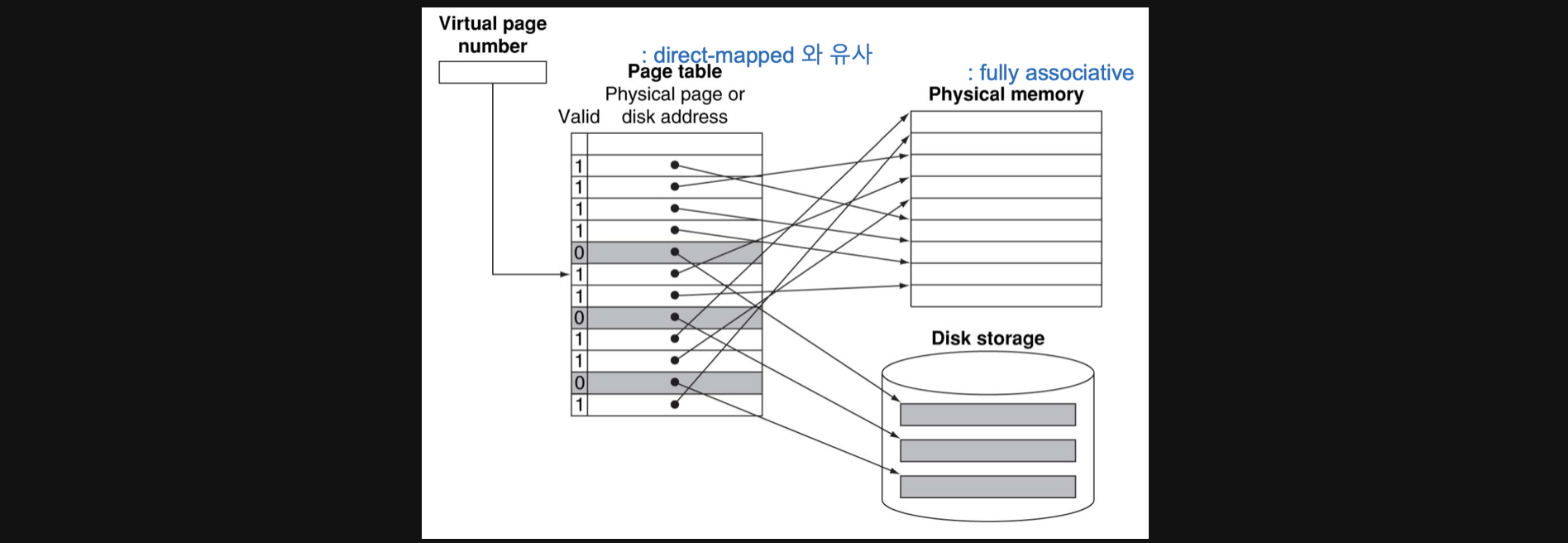
우리가 register번호에 offset을 alu add연산을 통해서 얻은 virtual address는 단순히 page table이라는 표의 index에 불과합니다
page table의 index에 valid가 1이면 실제 physical address를 얻을 수 있습니다 이런방식이 VM없는 address translation입니다
물론 이때 valid가 0이면 upper에 data가 없다는거니까 lower인 secondary storage에서 데이터를 copy해와야하고 이를 page fault라고 합니다
page table은 direct mapped 와 유사하게 동작하고 physical memory는 fully associative하게 동작합니다
실제 예시를 한번 보겠습니다
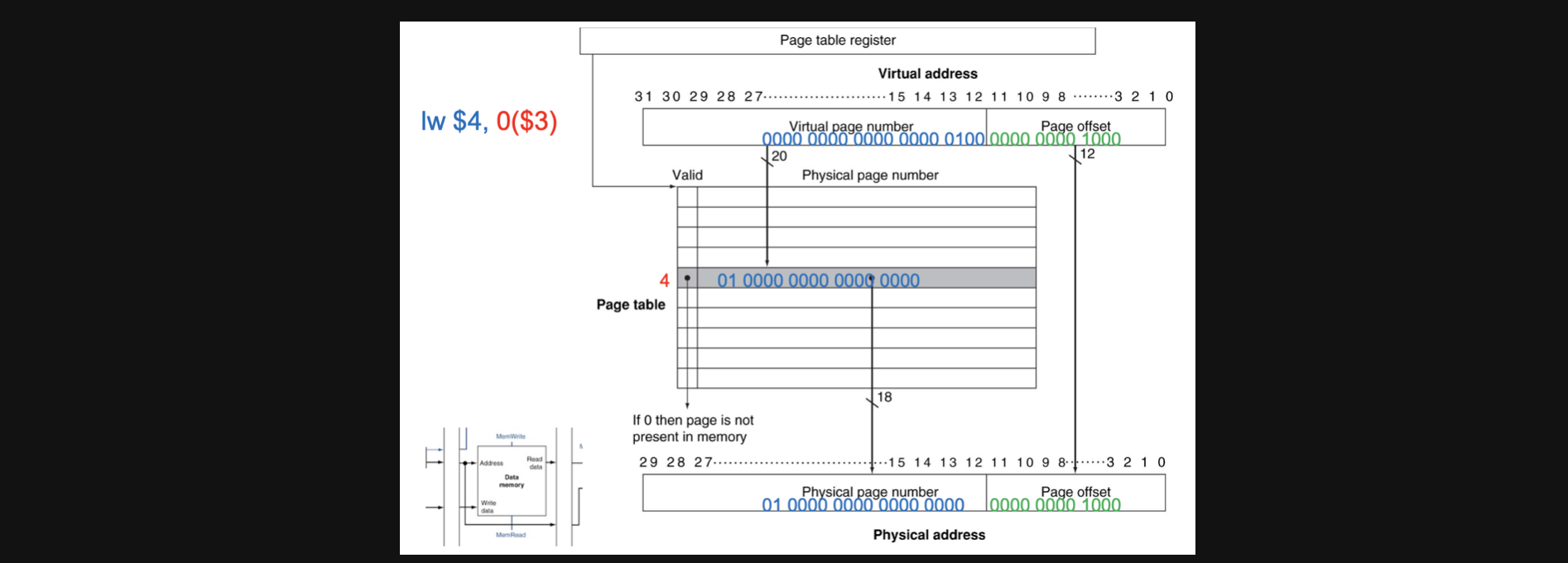
$3에 0을 더한 virtual address가 0100이었다고 가정해보겠습니다 page offset은 12bit라고 하겠습니다
그러면 page table에서 4번째 index에 가서 valid를 확인하니 1이어서 이를통해 가져온 값에 page offset을 붙여서 실제 메모리의 주소를 얻을 수 있습니다
여기서 한가지 알고 넘어가야할 부분은 page table은 Main Memory에 저장이 되어있다는 점입니다
그렇다는말은 page table에 접근하기위해서 main memory에 access해야하고 그렇게 해서 얻은 주소인 physical memory address에 접근하기 위해서는 다시 main memory에접근해야합니다
하나의 data에 access하기위해 maim memory에 두번 access해야하는 비효율을 방지하기 위해 나온방식이 VM을 활용한 Translation Lookaside Butter 죽여서 TLB방식입니다
Translation Lookaside Buffer(TLB)
이름이 좀 친해지기 어려운 친구같지만 쉽게말해서 page table의 cache메모리를 VM으로 추가한 방식입니다
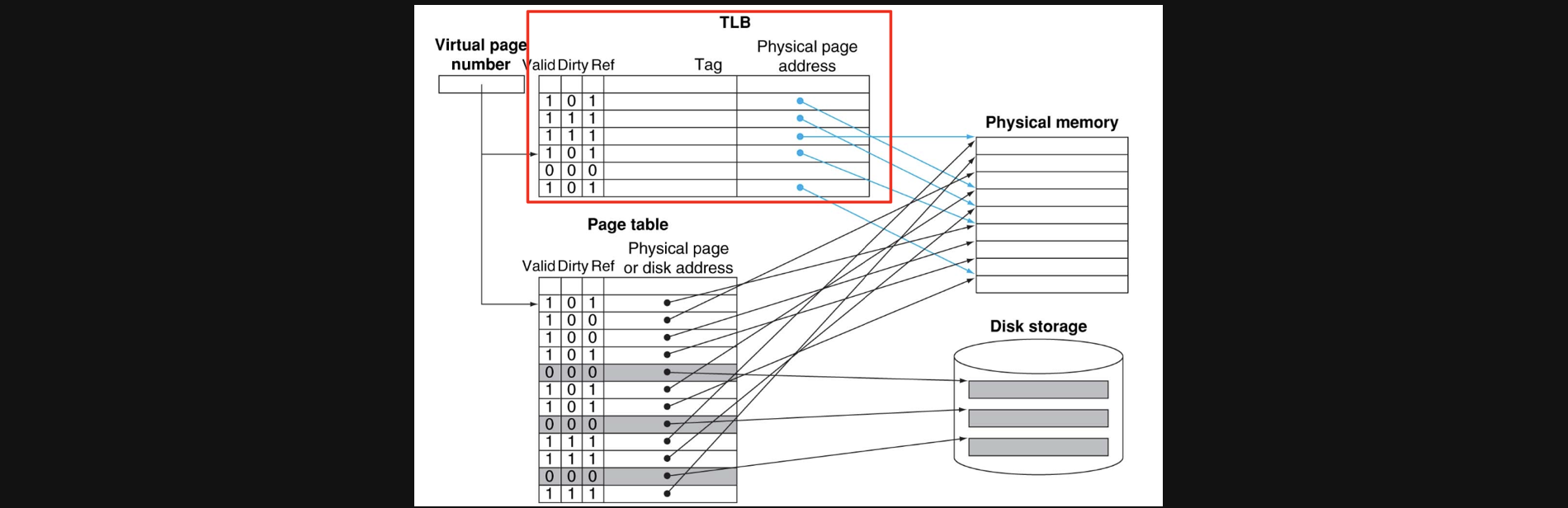
virtual page number를 ALU의 add연산을통해 알게되면 이 결과를 tag를가지고 TLB에, index를 가지고 Page Table에 동시에 access하게됩니다
만약에 TLB에서 tag가 동일하고 valid가 1이라면 바로 physical page address를 얻을 수 있습니다
만약에 valid가 0이라면 page table에 access하고 해당 index의 valid가 1이라면 TLB에 copy하고 physical page address를 얻을 수 있습니다 만약에 page table에서도 valid가 0이라면 page fault이기때문에 secondary storage에서 page table로 page table에서 TLB로 데이터를 copy해야겠죠
이런방식을 채택하면 physical memory가 매우 크기때문에 spatial locality에 의해서 miss ratio가 매우작고 cache를 이용한 방식이기에 miss panalty가 작습니다
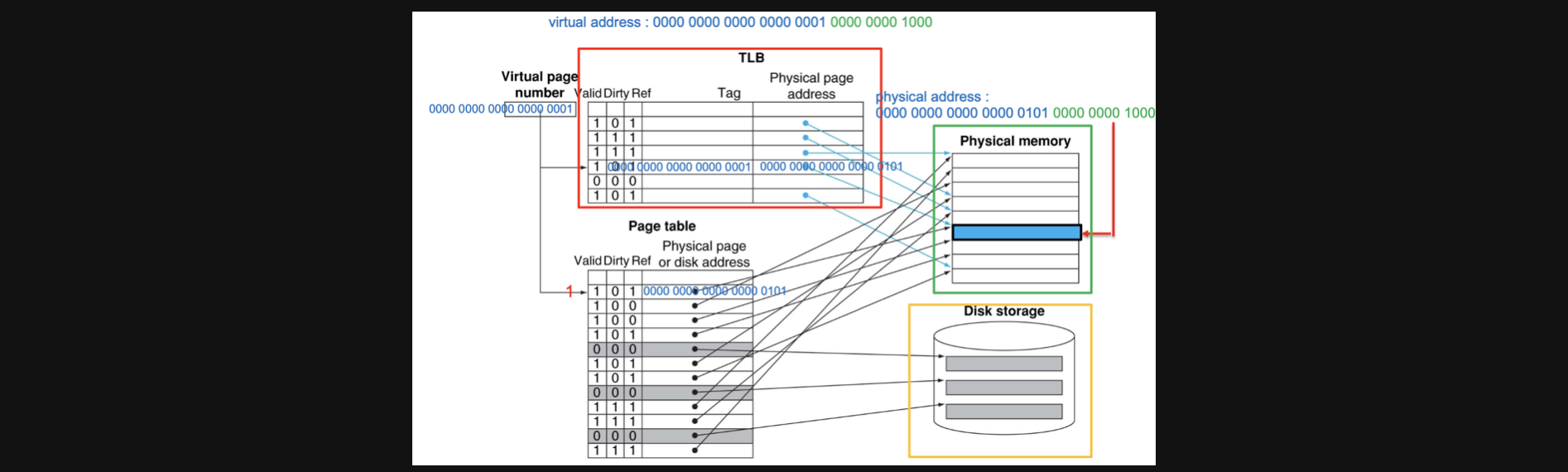
이대로 끝내면 조금 헷갈리실수도있을거같아서 실제 예시를 가져와봤습니다
virtual address가 맨위의 bit이고 거기서 page offset을 제외한 bit가 0000 0000 0000 0000 0001이라고 할때 TLB는 fully associate 이기때문에 이 bit전체가 tag가 되고(index는 전부 동일하니까) page table에 access할때는 이게 index가 됩니다(page table에는 tag가 없음)
그러면 TLB에서 해당tag에 valid가 1이니까 hit이어서 바로 physical address를 얻을 수 있습니다
만약에 TLB에서 valid가 0이라면 page table의 1번 index로 가서 valid를 확인합니다. 1이니까 적혀있는 데이터에다가 page offset을 붙여서 실제 메모리주소에 access할수있게됩니다
Virtual Memory + Cache
lw $4, 0($3)
이라는 instruction이 있을때 VM과 Cache를 이용하면 어떤 과정을 통해 data에 access할수있을지를 보겠습니다
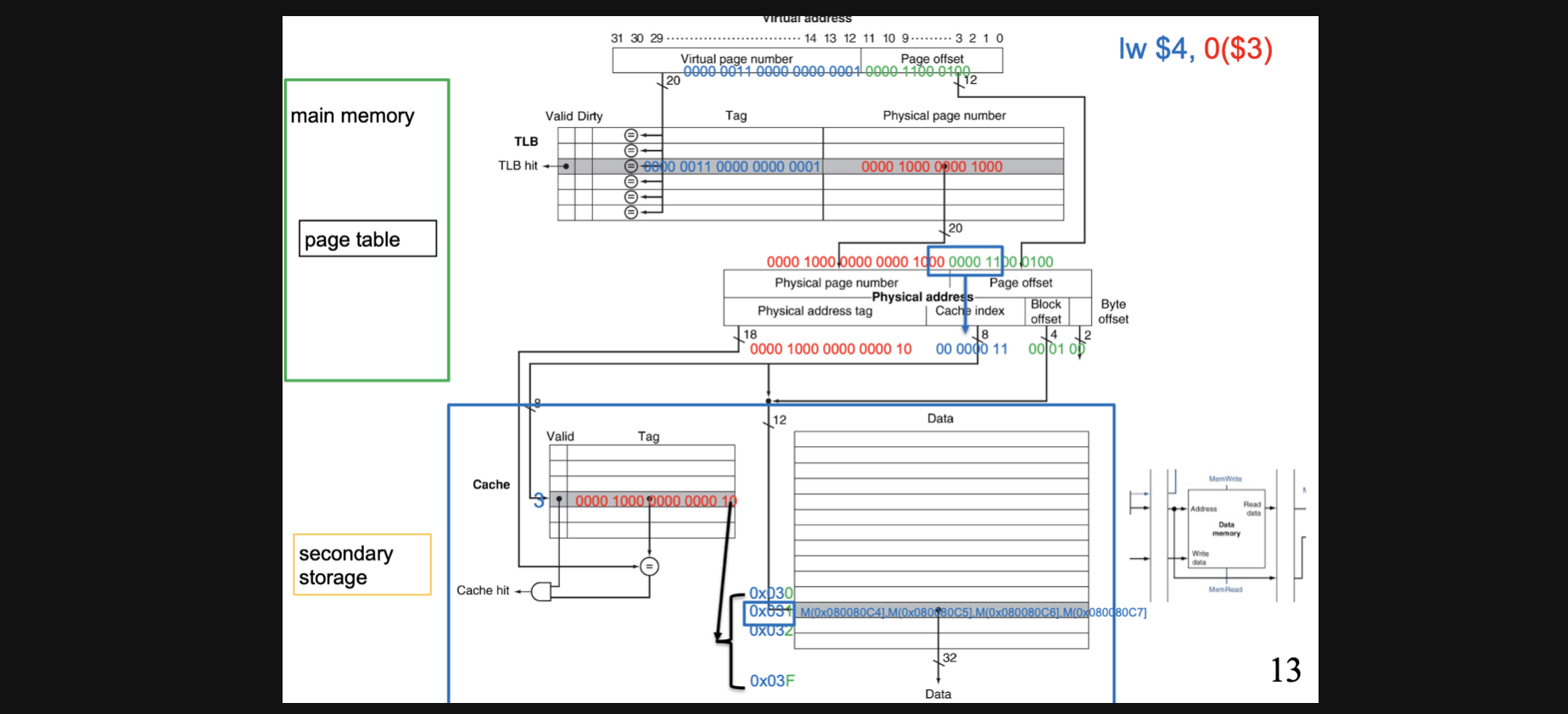
우선 0($3)이라는 연산을 통해 0000 0011 0000 0000 0001 000 1100 0100이라는 값을 얻었고 여기서 page offset이 12bit니까 TLB와 Page Table로는 12bit를 제외한 20bit만 들어가게됩니다
0000 0011 0000 0000 0001이 input으로 들어가겠네요
여기 그림에서 TLB에서는 전체 bit가 tag로 들어가는걸보면 fully associate방식이라는걸 알 수 있습니다
해당 tag에 valid가 1이므로 page table에는 access하지 않아도 됩니다 그렇게 얻게된 data에 page offset을 붙여서 실제 메모리 주소를 얻었고 이 메모리주소에서 데이터를 얻기 위해서 다시 cache를 위한 bit끼리 나눕니다
block offset이 4bit고 byte offset이 2bit인걸로봐서는 16words/block이겠네요
cache의 갯수가 256이라고 가정하면 index를 위한 bit는 2의8제곱 = 256이니까 0000 0011이고 3번 index로 접근하면됩니다 그리고 tag를 나머지 bit와 비교해서 같으면 16words data중에서 block offset이 1이니까 두번째 data에 access하면됩니다
이 방식은 사실 page faults나 miss가 일어나지 않은 이상적인 과정이긴 하지만 lw $4, 0($3)이 실제로 어떻게 일어나는지를 보여주는 좋은 예제라고 생각합니다
메모리에 관한 이야기를 마무리했습니다
사실 제가 공부하려했던 이론적인 진도는 여기서 마무리되겠네요
마지막으로 남은건 instruction 여러개가 연속적으로 수행될때의 TLB와 cache의 동작이 관한 내용입니다
왔다갔다 눈알이빠질거같은 예제지만 이렇게 한번 자세하게 짚고가야 나중에 공부를할때 수월하게 이해할수있기때문에 마지막 정리를 위한 포스팅을 적으러 가보겠습니다
전공책을 기반으로 정리하는 글이기때문에 나름대로 최대한 이유가있는 설명을 한다고는하지만 분명히 틀리거나 추가로 들어가야할 내용이 있을수있기때문에 언제든지 댓글로 알려주세요!
그럼 20000!!!!
