본 시리즈은 비전공자가 공부한 computer science, 그중에서도 컴퓨터구조를 정리한 글입니다. 틀린내용이 있다면 댓글로 알려주시면 정말정말 감사하겠습니다. 참고한 책은 Computer Organization and Design MIPS Edition입니다
6주차 컴구내용을 마무리하는 포스팅으로 찾아왔습니다!
이번주 마지막 주제는 ILP입니다 instruction level parallelism인데 명령어수준 병렬성이라고 직역할수있겠네요
ILP(instruction level parallelism)
peak CPI of single-issue pipeline processor
single-issue pipeline processor에서 CPI는 어떻게 구할수있는지 알아보겠습니다
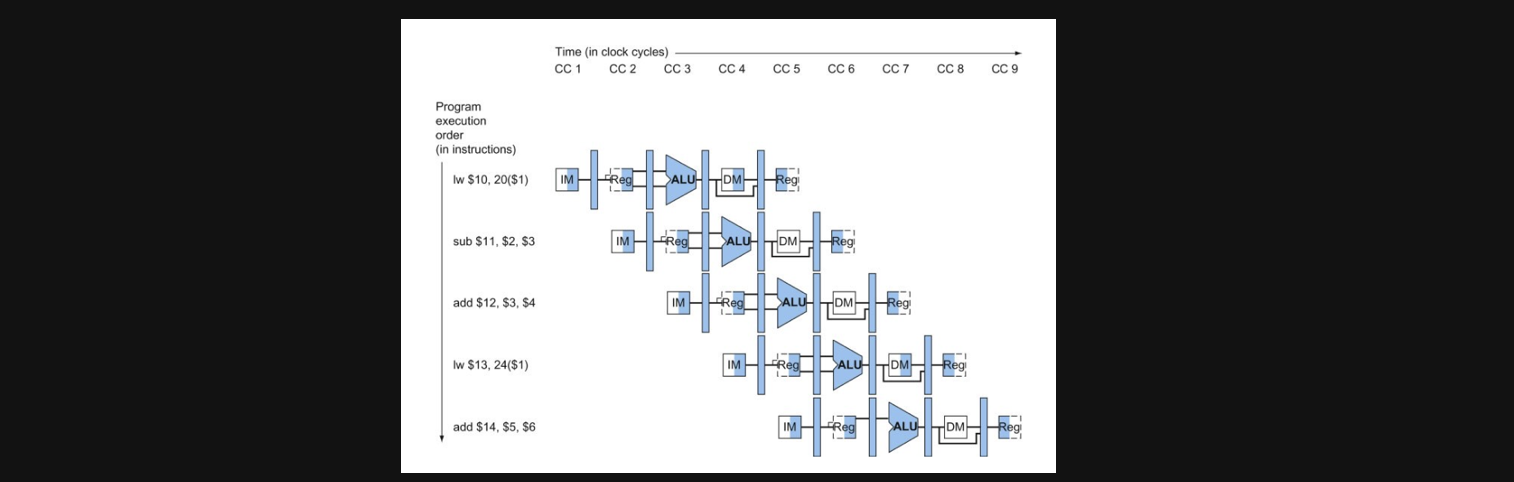
우리가 늘 보던 single issue pipeline processor입니다
예를들어서 n개의 명령어가 있고 p개의 pipeline stage가 있다고 가정해보겠습니다
이상적인 경우를 살펴봐야하기때문에 명령어가 무한대가 있어야한다고 가정하겠습니다
CPI는 하나의 instruction이 끝나기위해서 몇번의 cycle이 필요한지를 나타내는 용어입니다
그림을 보면 5개의 stage + (5개의 instruction - 1) = 9cycle
이라는 결론을 얻을 수 있게되는데요 이를 그대로 식으로 바꿔보면
n : instruction의 갯수
p : pipeline의 stage
식 : lim((p+(n-1))/n)
여기서 n이 무한대로 발산한다고 하면 1이라는 결과를 얻을 수 있습니다
즉, single issue의 pipeline processor에서는 CPI가 1이됩니다
반대로 IPC, 즉 cycle당 몇번의 instruction을 수행하는지는 CPI의 역수가 되어 이때도 1이 나오게됩니다
하지만 이는 이상적으로 hazard도 없고 stall이 없기때문에 CPI와 ICP가 1이 되지만 실제로는 hazard와 stall때문에 1이하의 값이 나오게 됩니다
ILP란?
ILP는 말 그대로 명령어 수준에서 프로그램에 기록된 순서대로 순차적으로 처리하는게 아니라, 명령어간의 상관관계를 잘 따져서 병렬처리가 가능하도록 하는 기술입니다
즉 여러개의 instruction을 동시에 병렬적으로 수행하게됩니다
ILP를 수행하는 방법에는 대표적으로 두가지 방법이 있습니다
1.Deeper pipeline
이 방식은 pipeline을 더 잘게 나눠서 stage를 늘리는 방식입니다 이렇게 되면 stage가 해야할 일이 줄어들고 결과적으로 clock cycle이 줄어들게 됩니다
2.Multiple issue
이 방식은 실제로 instruction 여러개를 한번에 fetch하는 방식입니다. Deeper pipeline처럼 pipeline stage를 더 잘게 나누는 방식이 아니라 기존에 pipeline stage를 복사해서 사용합니다
multiple issue의 방식은 dual의 경우엔 IPC는 2가되고(이상적인 경우엔) CPI는 1/2가 됩니다
하지만 dependency가 발생하고 이 때문에 hazard가 발생하고 stall이 발생해 실제로는 이상적인 IPC와 CPI를 얻을 수 없게됩니다
Multiple Issue
저희는 이중에서도 Multiple Issue방식을 위주로 배워보겠습니다
Multiple Issue에도 두가지방식이 존재합니다

종류가 정말 끊임업이 많네요...
1.Static multiple issue
이 방식은 컴파일러가 주체가 되는 방식입니다
컴파일러가 컴파일시점에 같이 수행될 issue를 묶어서 패키지를 만들어줍니다 issue를 묶어서 패키지를 만들때 최대한 hazard를 피할 수 있게 묶어서 최대한 stall없이 명령을 수행할 수 있게 해줍니다
컴파일러가 instruction을 하나의 group으로 묶기때문에 실제로 instruction의 길이가 기존보다는 길어집니다 그래서 VLIW라고 부르기도 합니다
Very Long Instruction Word(베리롱~~)
컴파일러가 hazard를 없애는 방식에는 instruction을 recorder하는데 명령어들의 순서를 바꿔서 hazard를 방지하는 방식이 있습니다 하지만 어쩔수없이 stall이 생기는 경우에는 nop으로 채워서 해결해줍니다
2.Dynamic multiple issue
static방식이 컴파일러가 주체가 되는 방식이었다면 dynamic방식은 CPU라는 하드웨어가 주체가 되어서 동적으로 어떤 명령어를 실행할 cycle를 결정합니다. CPU가 runtime hazard를 감지하고 해결하고 필요할시에는 컴파일러가 도움을 주기도 합니다
MIPS with Static Dual Issue
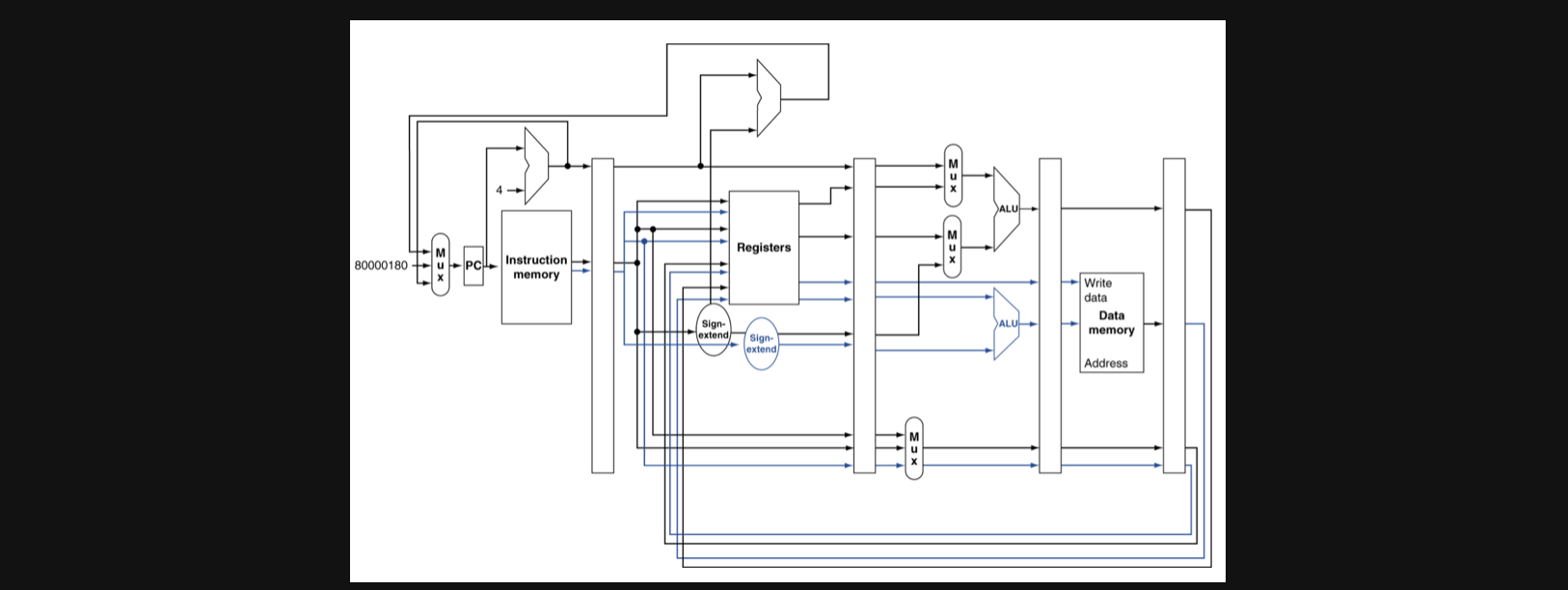
실제 MIPS에서 static dual issue의 회로를 보면 한번에 두개의 instruction을 수행할 수있는 모양을 가지고 있습니다
register의 경우에도 기존처럼 input이 3개가 아니라 두개의 instruction을 커버할수있는 register을 가지고 있고 EX stage에서 ALU도 두개가 존재합니다
하지만 ALU 두개의 모양이 조금 다른걸 눈치채셨나요?

파란색선과 검은색선이 EX stage에서 수행하는 연산이 조금 다른데요 파란색선에 있는 ALU의 두번째 operand는 register로부터 오지 않습니다
그러면 두 연산이 하는 역할이 다르다는 이야기 인데 검은색 ALU와 파란색 ALU는 각각 어떤 instruction을 수행할 수 있을까요?
검은색 : add, sub, and, or, slt, beq
파란색 : lw, sw
회로를 보면 dual issue의 경우 두개의 instruction이 한번에 실행되는데 각각의 연산이 수행할 수있는 연산이 나눠져 있습니다
즉 ALU연산이나 branch연산 하나 그리고 lw, sw연산 하나씩 한쌍으로만 dual issue가 가능하게됩니다
그래서 static multiple issue의 경우엔 compiler가 instruction을 두개를 한쌍으로만들때 위와같은 규칙을 지켜서 만들게 됩니다

n번 address와 n+4번 address가 함께 실해되는데 n번 주소의 instruction은 ALU/branch이고 n+4번 주소의 instruction은 Load/Store인것을 알 수 있습니다
만약에 한번에 두타입을 수행할 수없는경우엔 비어있는 곳을 nop으로 채워줍니다

만약 이러한 연산을 수행해야할때 이두개를 하나의 set으로 묶어서 동시에 수행하게되면 hazard가 발생하기 때문에 컴파일러는 이러한 경우엔 hazard가 발생하지 않게 scheduling해줘야합니다
Scheduling Example

이러한 연산이 있다고 가정해봅시다 각각의 색깔들로 칠해진 register는 순서대로 실행하게 되면 hazard가 발생할 친구들입니다
이런 순서 그대로 각각 set끼리 병렬로 instruction을 수행시키면 hazard가 정말 많이 발생하겠지만 static multiple issue의 컴파일러가 새로 스케줄을 해줍니다

같이 실행할 수 있는 instruction의 경우 nop으로 채워서 수행해줍니다
총 4번의 cycle을 통해서 이 명령들을 수행시킬 수있고 총 instruction의 갯수는 5개이므로
Insturction Per Cycle은 5/4해서 1.25가 됩니다 dual issue의 경우엔 이상적인 경우 IPC가 2인데 이런 hazard가 발생할수있는 경우엔 이상적으로 동작할 수 없어 효율이 떨어지게됩니다
Loop Unrolling Example
이런 코드가 있다고 가정해보겠습니다 100번의 loop를 돌겁니다
for (i=0;i<n;i++) {
a[i] += k;
}같은 결과를 얻는 코드지만 아래와 같은 코드가 더 효율적으로 동작합니다
for (i=0;i<n;i+=2){
a[i] += k;
a[i+1] += k;
}한번의 loop에서 두번의 동작을 수행할수있기때문에 loop연산을 50번만 하면되니까 효율적입니다
이러한 방식을 loop unrolling이라고 합니다
loop unrolling을 하면 컴파일러단에서 어떻게 효율적으로 동작할수있게 되는지를 보겠습니다

기존의 1씩증가시켜서 100번 loop를 도는 코드입니다 이전에 봤던 예제처럼 hazard가 발생할 가능성있는 곳이 많아서 scheduling이 필요하고 컴파일러가 스케줄링을 했을때의 결과가 IPC 1.25라고 확인했었습니다
loop unrolling했을때의 instruction코드입니다

맨 왼쪽에 있는 명령어들이 loop unrolling했을 시점의 모습이고 compiler는 이 명령어들을 보고 우선 register를 renaming이라는 방식으로 최적화를 해줍니다
맨 왼쪽에 박스를 보면 t0값을 s1에 넣어주는 작업이기때문에 작업이 끝나면 t0에 어떤 값이 있는지는 상관이 없고 아래 명령어를 보면 s1에서 offset4에 있는 값을 t0에 넣어주는데 사실 굳이 t0라는 같은 regiser에서 연산을 수행할 필요가 없습니다 같은 regiser를 공유하면 hazard가 발생할수도있으니까요
그래서 각 연산의 결과를 따로 저장할수있도록 register번호를 바꿔줍니다(메모리 공간의 효율성을떨어질 수있어도 효율적으로 instruction 수행이 가능합니다) 그리고 파란 네모처럼 instruction의 위치르 바꿔줘서 컴파일러가 instruction의 수행이 효율적으로 동작할 수 있게 해줍니다

이렇게 scheduling이 끝나고 2개씩 병렬적으로 instruction을 수행하면 14개의 instruction이 8cycle만에 끝나게 됩니다
IPC를 구해보면 14/8 즉, 1.75라는 값이 나오고 2에 가까울수록 이상적으로 동작(= hazard가 최대한 없이 동작)한것이기 때문에 loop unrolling하지 않은 결과보다 효율적으로 동작했다는걸 알 수 있습니다
Dynamic pipeline Scheduling
dynamic Multiple Issue의 경우엔 CPU가 instruction을 code semantic해준다고 배웠습니다
이와 같은 instruction을 수행할때 static의 경우엔 instruction의 수행 순서를 아얘 바꿔버렸지만
CPU가 하는 Dynamic pipeline Scheduling는 out of order방식(?)응 사용합니다
예시에서처럼 t0의 결과가 필요한데 수행시점에서 t0의 결과가 없다면 기다렸다가 받아서 사용합니다 물론 기다리는 동안엔 다른 instruction을 수행합니다
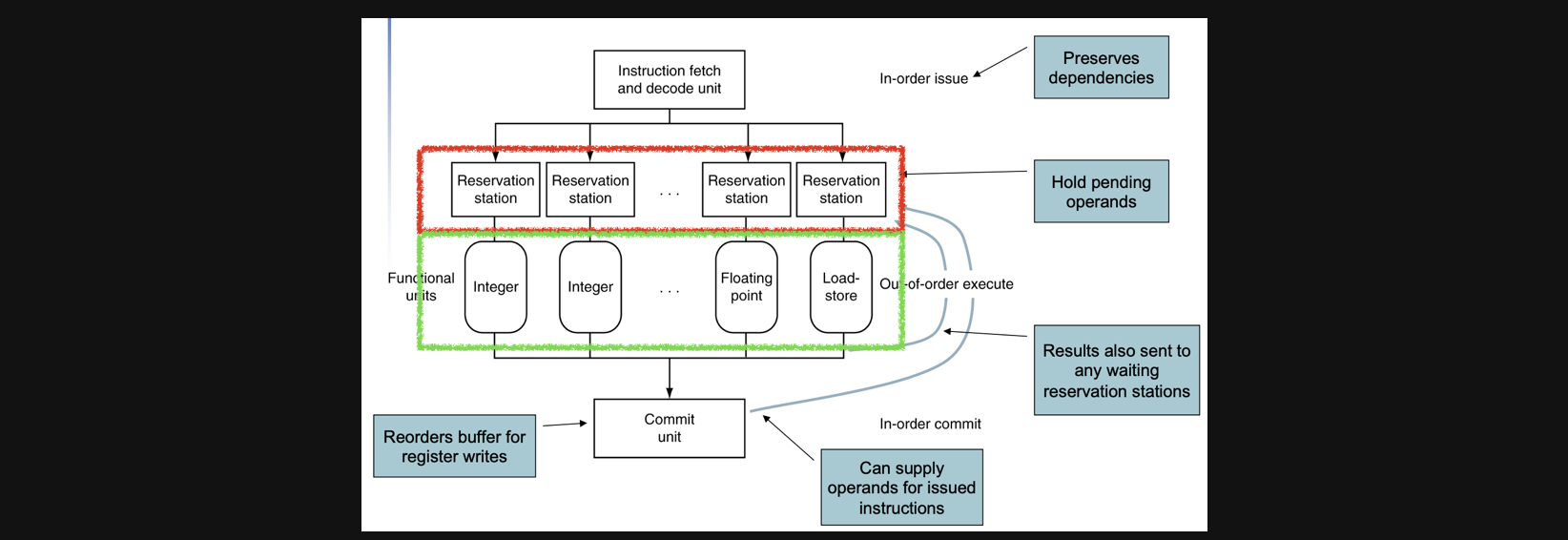
예를들어서 t0의 결과가 필요한 instruction을 수행하면 빨간 네모의 reservation station으로 들어갑니다 그런데 t0의 결과가 아직 안나왔다면 결과가 나올때 까지 기다립니다 다른 명령어는 다른 reservation station로 들어가 실행되고 실행결과가 commit unit에 들어갑니다
그런데 t0의 결과를 만들어내는 어떤 연산이 commit unit에 t0의 결과를 보내주면 기존 flow에서 out of order한 방식으로 t0연산결과를 기다리는 reservation station로 들어가서 멈춰있던 연산을 수행하게됩니다
그 외에도 instruction이 무슨 일을 할지 예측해서 수행하는 Guess방식도 있고 이를 Speculation이라고 합니다
이번 포스팅도 이전포스팅과 마찬가지로 이런 이런 개념이있다~ 정도로 알고 넘어가시면 좋을거같은 내용들이었습니다. 키워드 위주로 알고넘어가면 좋을거같습니다
내용이 많이 어렵지는 않지만 새로알게된 개념들이 여러개 나온거같아서 이전 강의들에비해서는 조금 쉬어가는 주차가 아니었나 싶네요
전공책을 기반으로 정리하는 글이기때문에 나름대로 최대한 이유가있는 설명을 한다고는하지만 분명히 틀리거나 추가로 들어가야할 내용이 있을수있기때문에 언제든지 댓글로 알려주세요!
그럼 20000!!!!
