개요
IT-Hermes 프로젝트를 진행하는 과정에서, JPA의 영속성 컨텍스트 덕분에 코드를 변경하는 과정에서 유용하게 사용했습니다.
하지만 JPA, 정확히 말하면 영속성 컨텍스트에 무조건 의존하는게 맞는가? 라고 생각해보면 그거에 대해선 아니라고 말하고 싶습니다.
그렇게 생각하게 된 이유는 아래의 이슈를 통해 알게 되었습니다.
현재상황
저는 유저의 전체정보(구독정보 포함)를 가져오는 API를 만들고 구현하는 개발을 하고 있었습니다.
여기서 회원과 구독정보를 가져오는 API가 필요했습니다.
Postman에서 본 데이터는 아무 이상이 없었습니다. 하지만, 문제상황은 다른 곳에 있었습니다. 바로 JPA였습니다.

문제상황
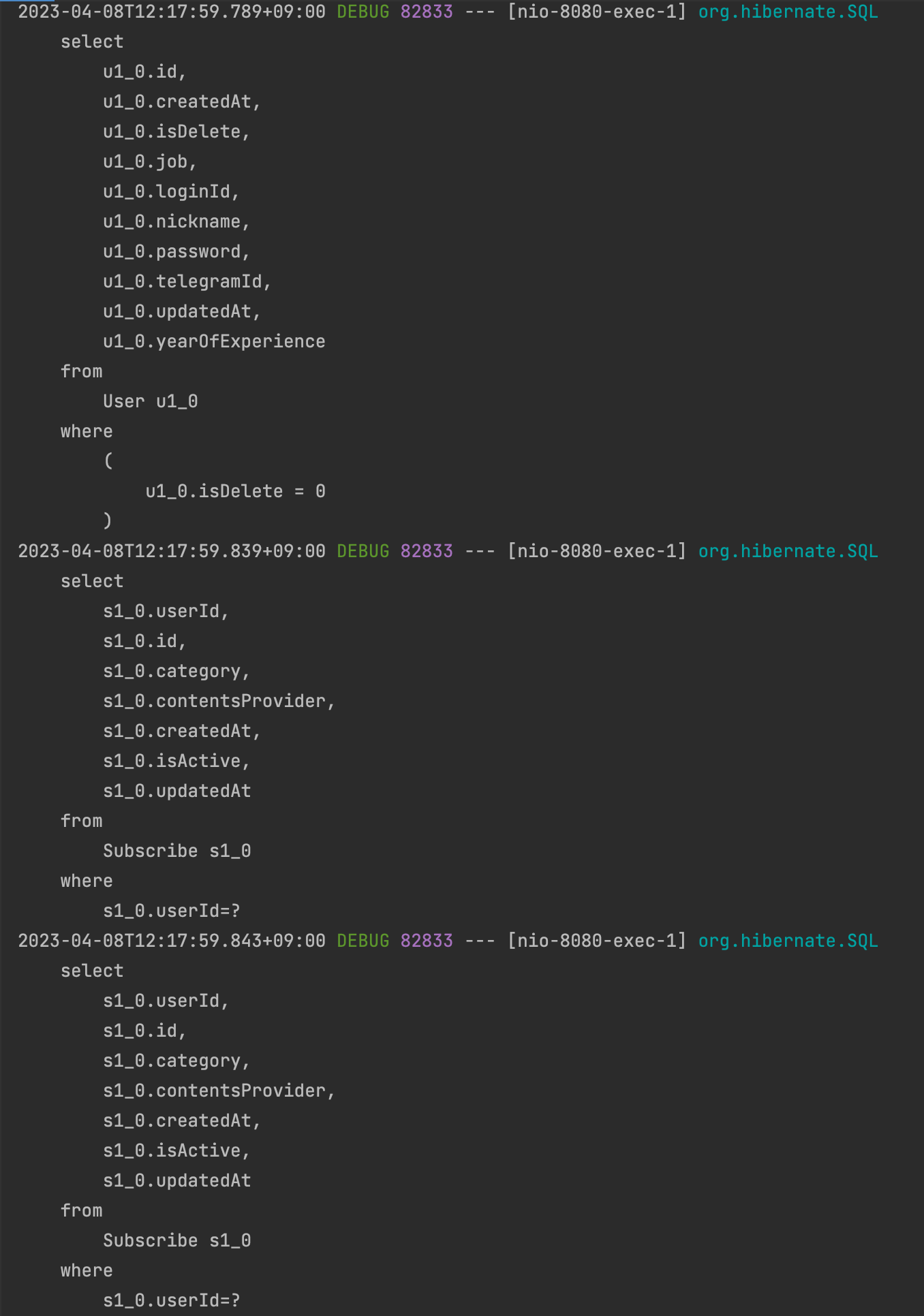
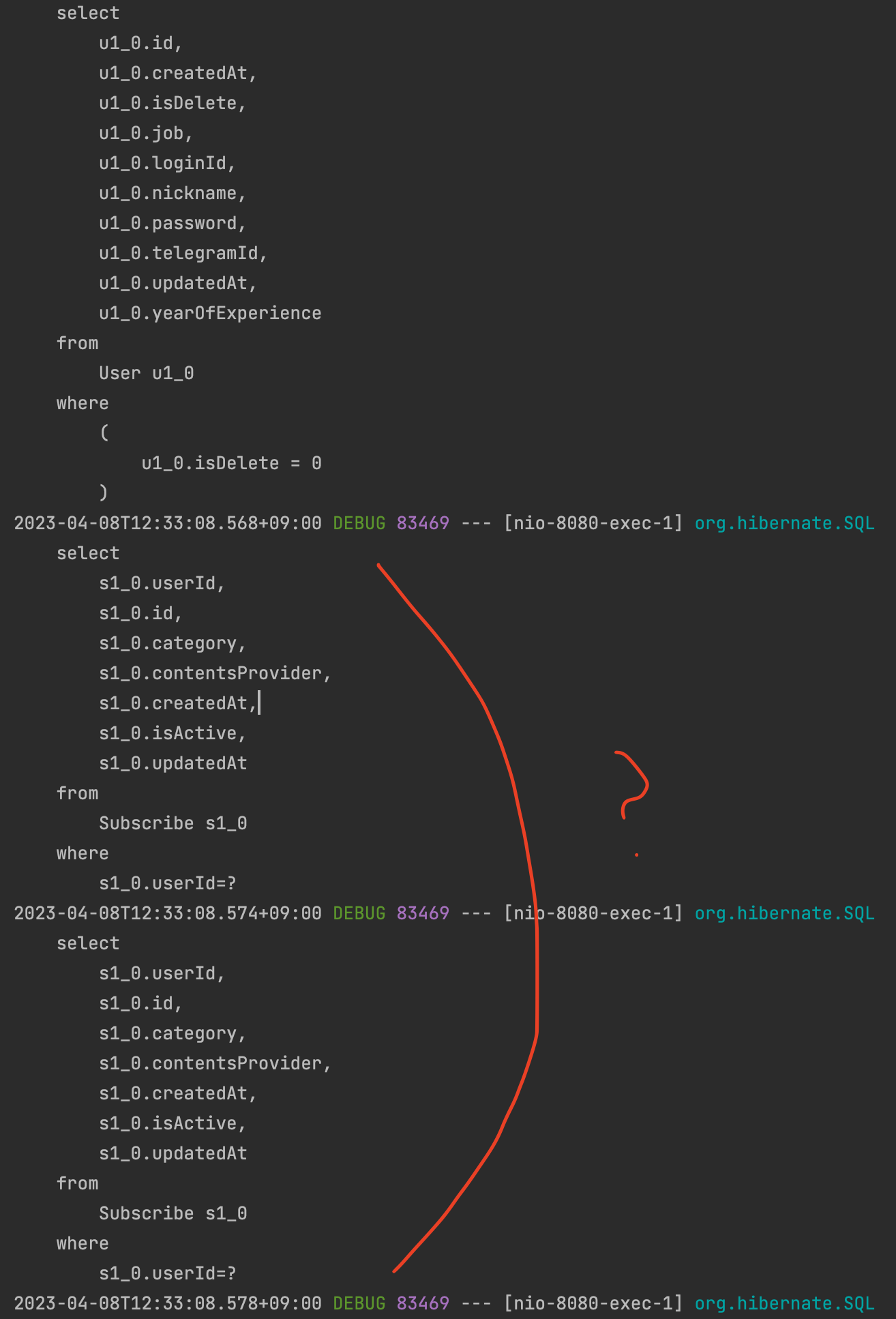
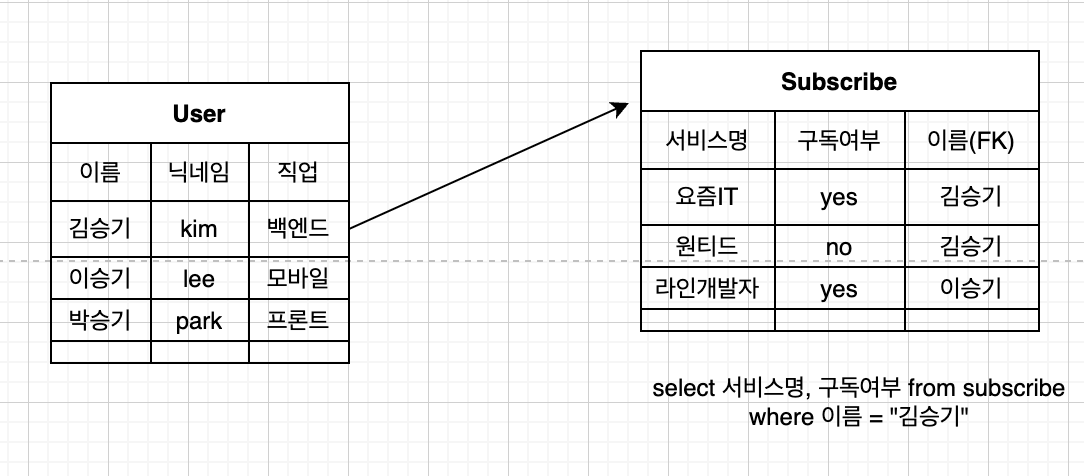
유저 테이블에서 데이터를 가져오는 것 까지는 좋았습니다. 근데, 이상하게 구독정보를 가져오는 쿼리는 1번이 아닌 20번이상 호출이 되었습니다.
발생원인?
이유는 User 테이블과 Subscribe 테이블에 정보를 가져오는 상황에서 JPA의 영속컨텍스트에 의존한 것이 해당 이슈가 발생한 이유입니다.
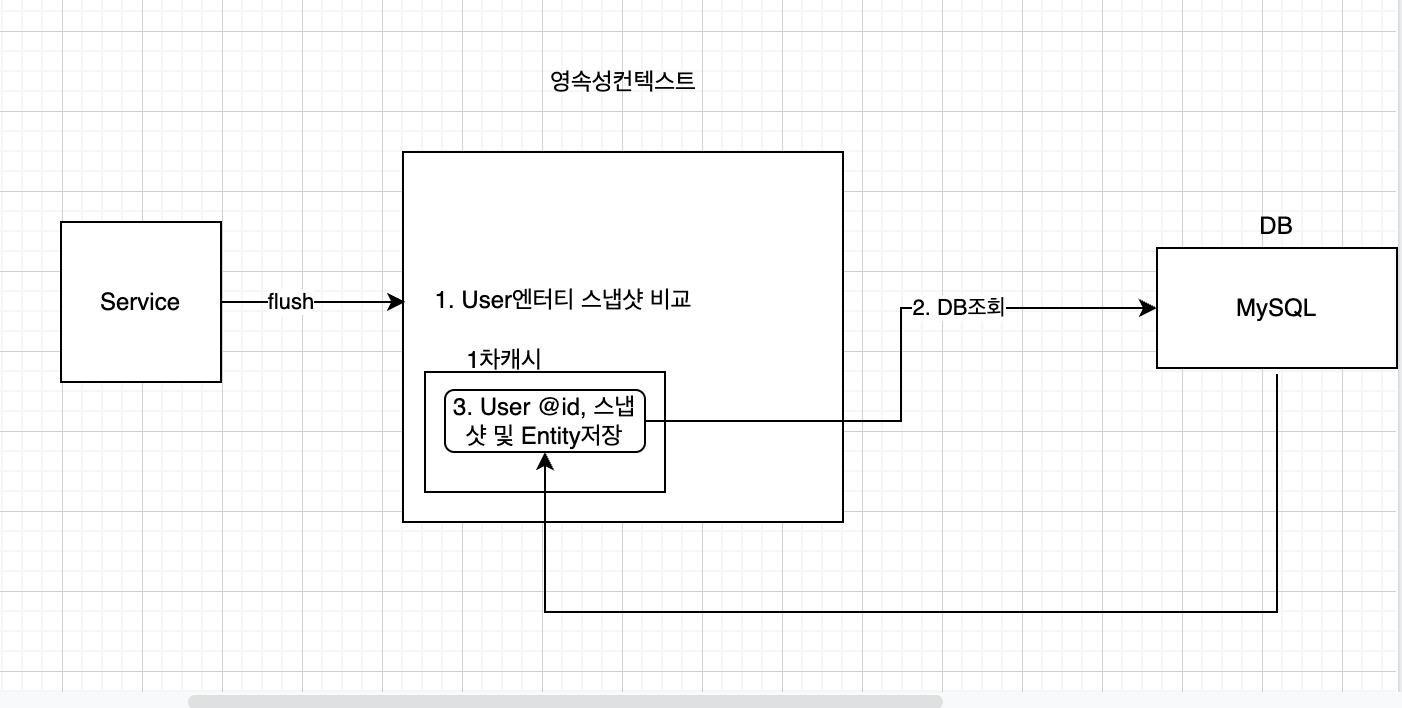
영속컨텍스트의 처리과정을 보면 다음과 같습니다.
이 부분까지는 원하는 상황이 맞았습니다. 영속성컨텍스트에 User에 대한 스냅샷이 없을 경우(한번도 조회를 안했다고 가정했을 때) DB를 통해 가져오거나 혹은 2차캐시(여기에 안쓰긴 했지만)를 통해 가져오기 때문입니다. 하지만...
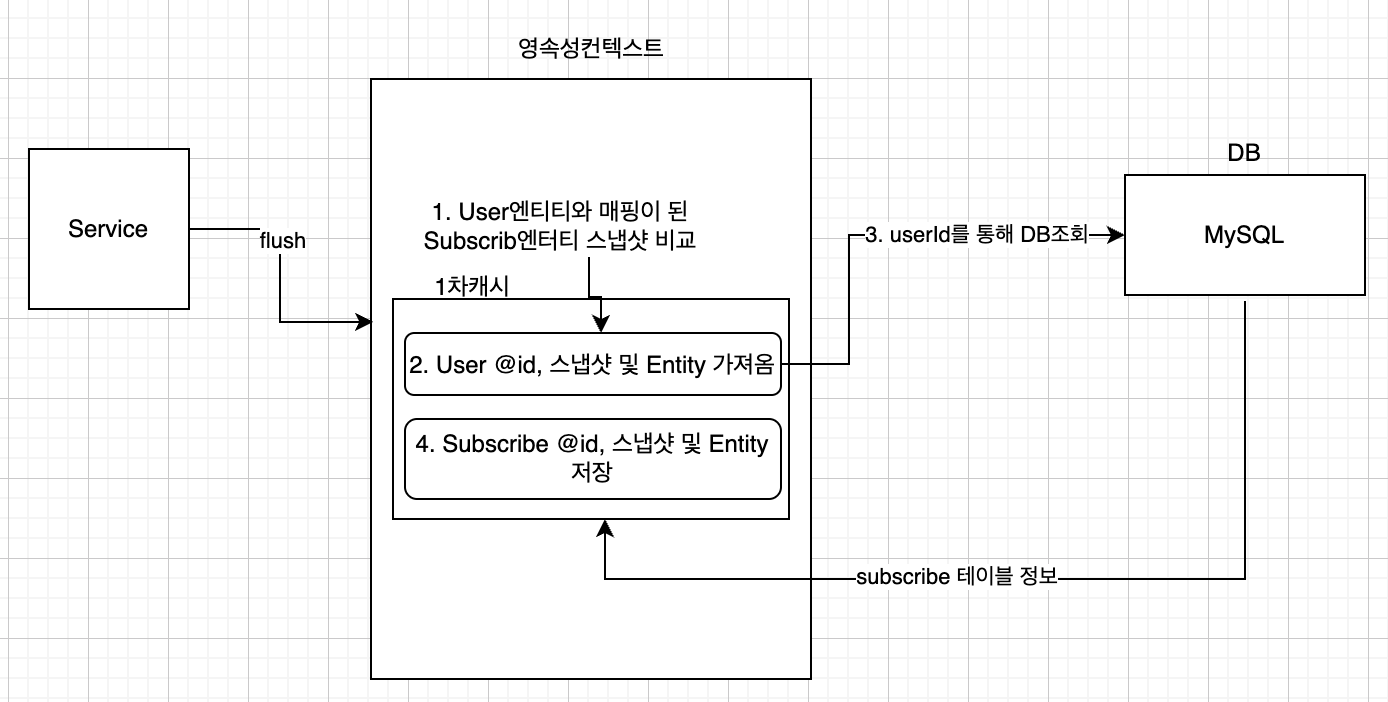
이 상황 역시 언뜻 보면 괜찮아 보지지만, 문제는 3번과 4번입니다.
이유는 아래의 그림와 같습니다.
아래의 정보는 2번을 통해 가져온 User 엔터티입니다. 이후 문제상황은
여기서 끝이 아니라
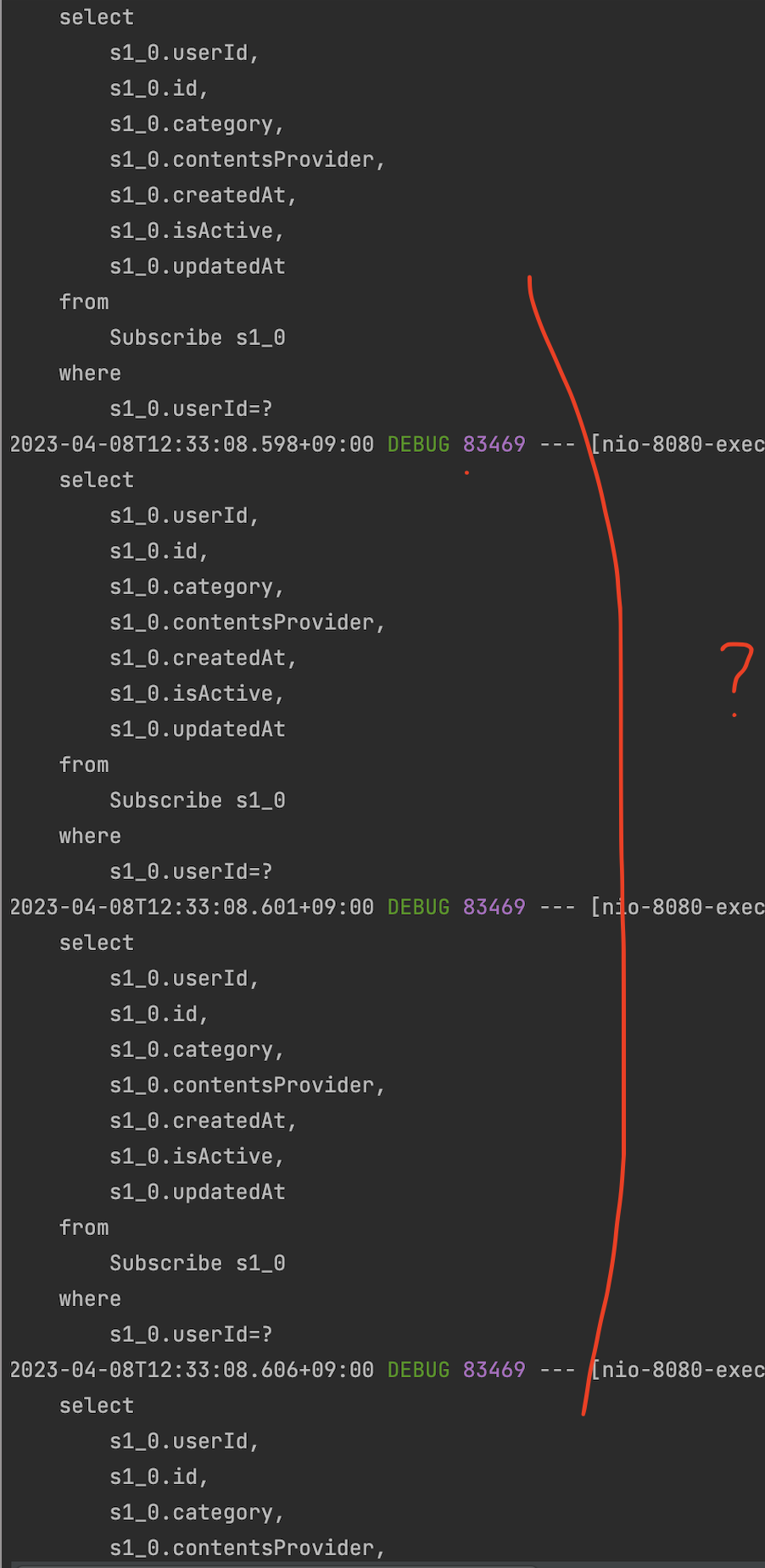
이렇게 계속 진행이 되는 점이 문제입니다. 결국 3,4번이 N번 만큼 호출이 되는거라고 할 수 있죠
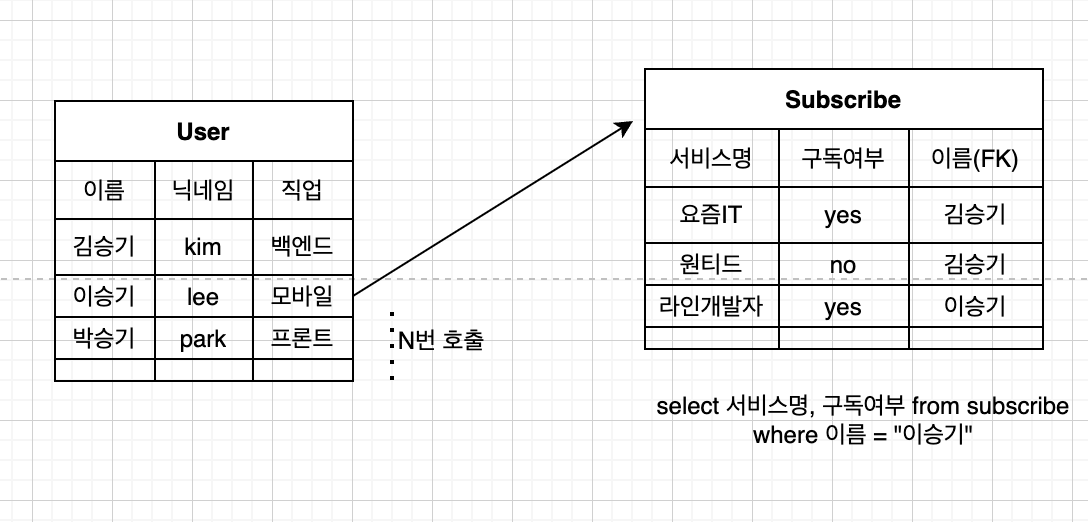
그래서 N+1이 뭔데?
위의 그림을 보면 N번 호출이라는 것은 쉽게 이해를 할 수 있습니다.
+1은 어디서 나온건가? 싶을 수 있지만, 바로 User엔터티를 처음 조회할 때를 말합니다.
결국 N+1로 처리가 된다면, 물론 당장 구현은 할 수 있지만, 네트워크 비용이 개발자가 기대한 것에 비해 훨씬 더 많은 N번이 더 호출이 되서 처리속도에 이슈가 있다는 점이 큰 원인입니다.
지연로딩으로 어떻게 할 수 없을까?
지금 같은 경우 FetchType를 Eager로 처리했기 때문에
발생하였던 점이 원인이지만, 그럼 단순히 생각해보면 영속성컨텍스트의 장점인FetchType를 Lazy로 해서 지연로딩을 하면 되잖아? 라는 생각을 할 수도 있습니다. 물론 User 엔터티의 정보만 가져올 경우, 해당 방법은 효과가 있습니다.
하지만, User가 아닌 Subscribe 데이터를 가져오게 될 경우라면 이야기가 다릅니다.List<Subscribe> subscribeList = userList.stream.map(user-> user.setSubscribe(subscribeReporitory.findByUserId(유저명)).toList();으로 가져올 확률이 높습니다. 결국 이렇게 가져오게 된다면, N+1은 애플리캐이션 상에서 발생하는 것과 다를게 없는 것을 알 수 있습니다.
그리고 불필요한 코드가 많아지기 때문에, 추후 리펙토링을 하는데 어려움이 있을 가능성이 존재합니다.

해결방법은?
영속성컨텍스트의 힘을 빌리지않고, Join을 직접 하는 것이 필요합니다. 결국 해당 이슈는 영속성 컨텍스트의 단점을 개선하는 것이기 때문에 영속성 컨텍스트가 아닌 직접 Join을 사용하여 처리하는 것이 영속성 컨텍스트의 장점을 포기하더라도 더 나은 방안이라 판단했습니다.
의문점
그냥 Join을 해도 될 것 같은데, 왜 Fetch Join을 하는지에 대해 의문점이 생길 수도 있다고 생각합니다. 하지만, fetch join없이 join을 할 경우 join 대상인 엔터티의 경우 영속성 컨텍스트에 저장이 되지 않는 이슈가 있습니다. 따라서 join 대상을 만약 엔터티를 통해 조회할 경우 LazyInitializationException 예외가 발생되게 됩니다.
물론 조인은 하지만, 영속성컨텍스트에 저장을 원하지 않을 경우에는, join을 쓰는 것이 메모리 사용량 측면에서 훨씬 좋기 때문에, 필요한 상황에 쓰는 것이 좋습니다.
코드에 적용
기존 Repository에 Fetch조인 쿼리를 추가하고 해당 메소드를 호출하도록 처리했습니다.
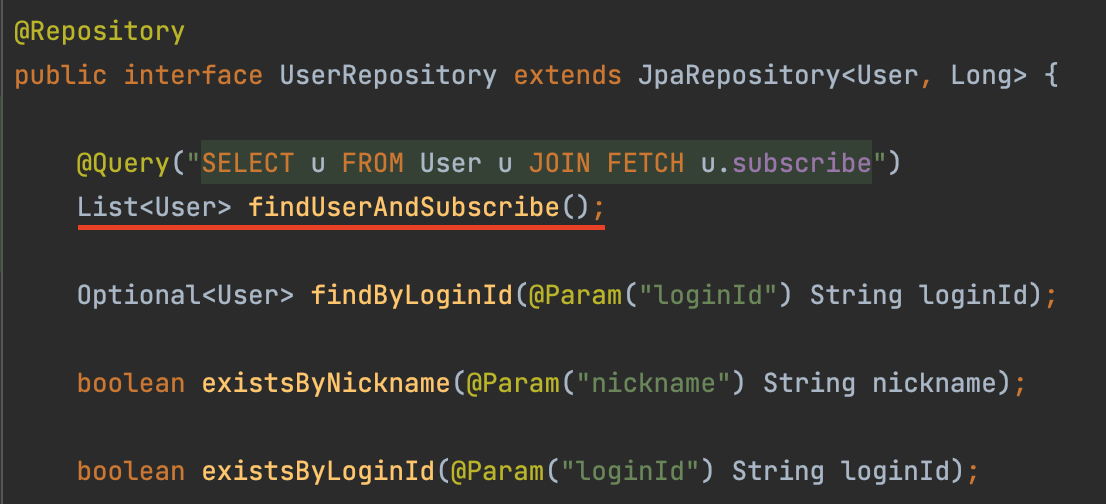

결과
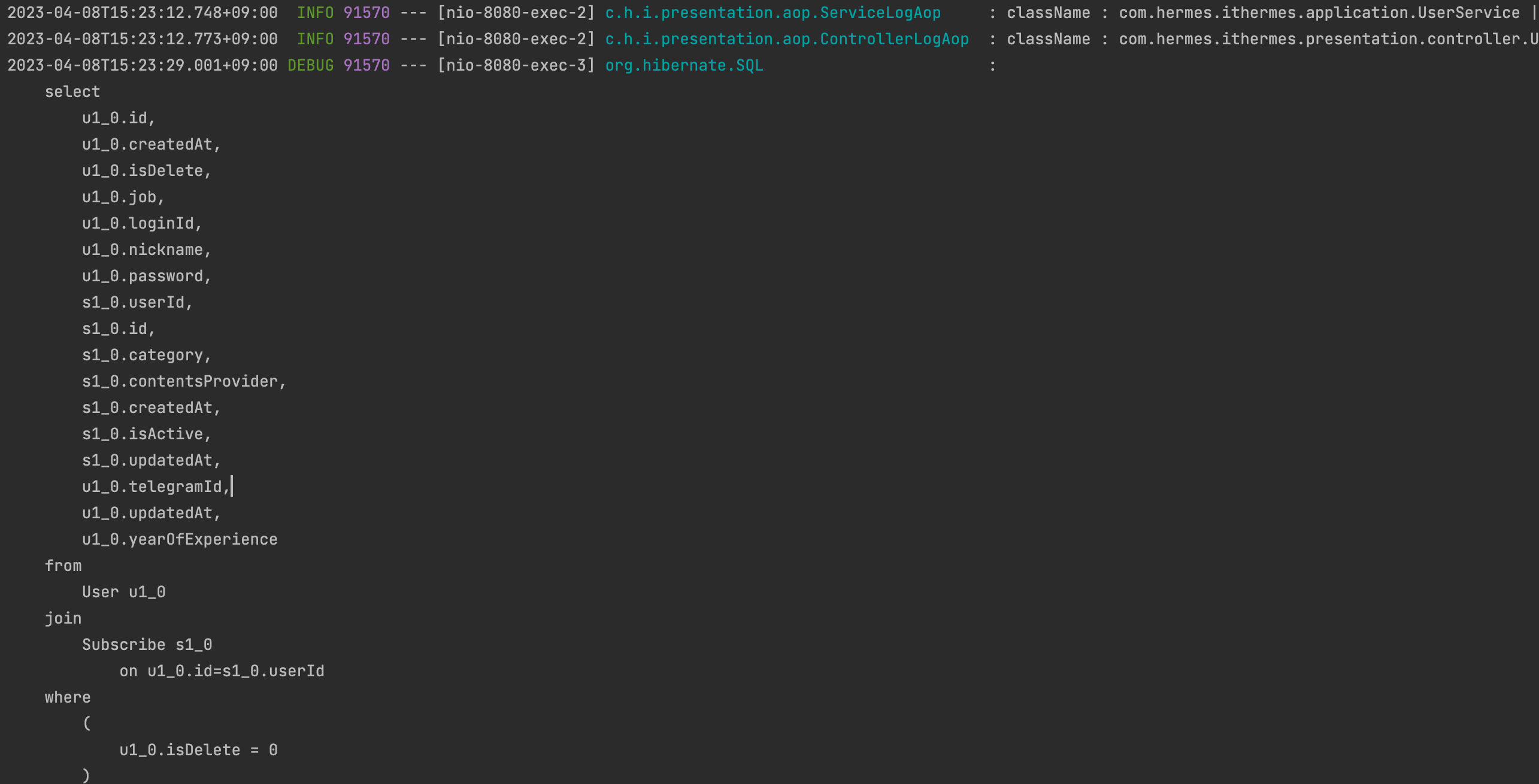
기존에 User를 조회하고 Subscribe를 user의 레코드만큼(N번) 조회가 되었는데, 1번으로 나오게끔 처리가 잘 된 것을 확인할 수 있습니다.
주의할 점
fetch join의 경우 N+1 이슈를 해결하는데는 적합할수 있습니다. 하지만..
하위테이블을 조회하지 않고 싶은 경우도 분명 존재할 것이고, 하위테이블이 손자.. 증손자..까지 있을수도 있습니다. 이러한 경우에는 영속성컨텍스트에 의존하는 코드를 사용하거나, JPA 그래프를 통해(테이블이 복잡할 경우 유용합니다) 처리하는 것도 좋은 방안이라고 생각합니다.
