개요
IT-Hermes 프로젝트의 구현을 마친 후, 처리속도를 개선할 수 부분이 있는지 찾는 과정에서,
한 가지 이상한 상황을 발견했습니다.
어떤 이슈?
nGrinder를 통해 평균 TPS를 확인은 했지만, 그 이상을 확인을 하지 않았지만, 자세히 보니까 TPS 그래프가 이상했습니다. 확인한 결과는 다음과 같습니다.
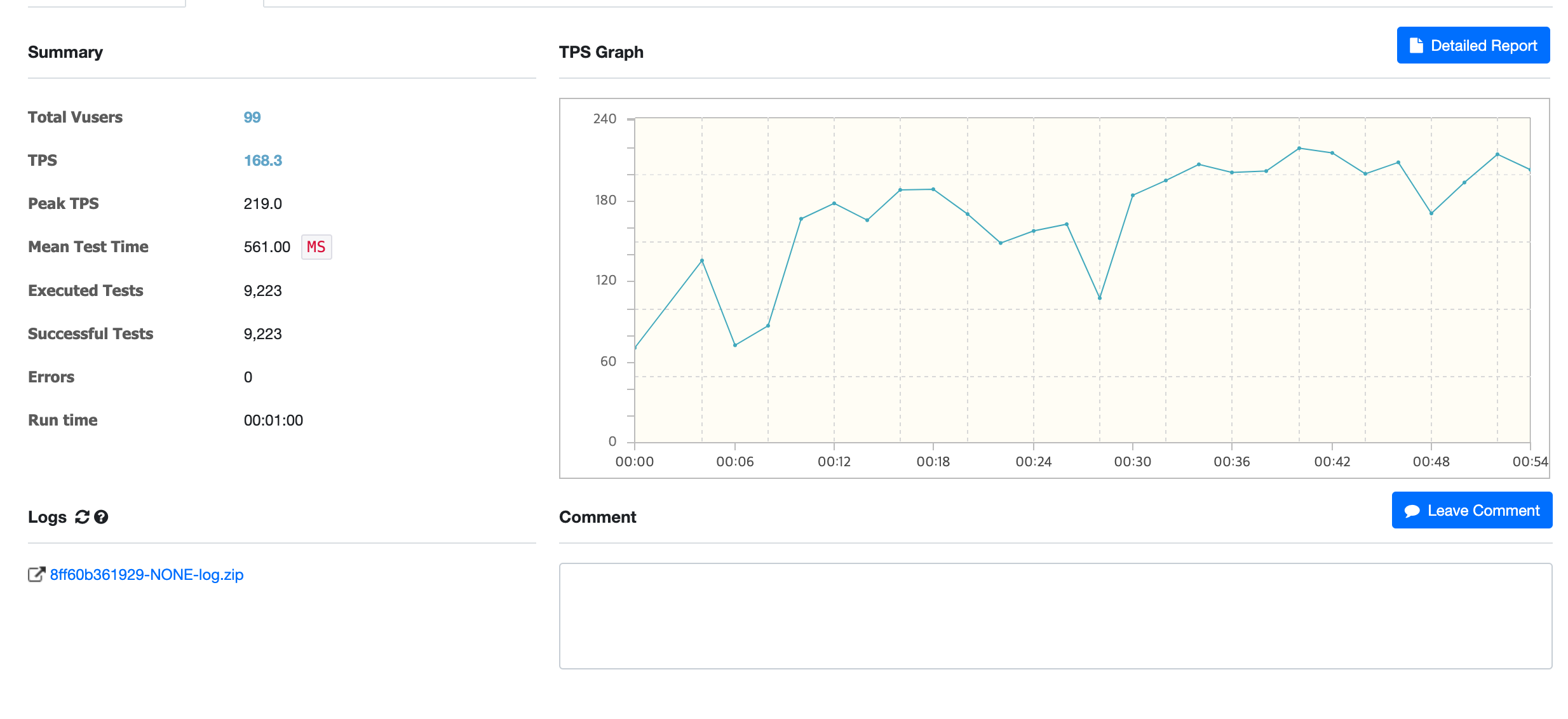
100명을 설정하고, 부하테스트를 진행하였는데, 그래프의 변동성이 너무 큰 이슈가 있었습니다.
고민한 과정
먼저 그래프의 이슈의 경우 트래픽이 갑작스럽게 많이 나오게 되어 발생한 점이 큰 원인이고, 트랜잭션 처리를 위한 CPU 점유율과 메모리 사용량 역시 높은 점이 원인이라 판단했습니다. 이 과정에서, 발생하는 요소를 개선하기 위해선, 결국 트래픽을 분산하여 이슈를 해결하는 것이 좋을거라 판단했습니다.
해결방법
트래픽 분산을 할 수 있는 방법은 애플리캐이션 서버를 Nginx에서 클러스터링하여 애플리캐이션 서버를 로드밸런싱을 하는 방향으로 생각을 했습니다.
물론 여러 방법들 중, Scale-Up을 하는 것이 좋은 방안이긴 하지만, 장비의 성능을 높이는 것은 현실적으로 한계가 있는 방안이라 생각을 했습니다. 그래서 기존의 서버에 로드밸런싱을 설정하여 트래픽을 분산하는 방법이 좋은 방안이라 판단했습니다.
실제 코드에 적용
로드밸런싱을 설정하는 것은 크게 어렵지 않았던 것 같습니다. 다행히 프로젝트의 경우 Docker-Hub를 통해 관리하고, 최대한 Docker 환경에 애플리캐이션 서버가 의존하도록 해서인지, 새로 생성한 NCP 인스턴스의 생성과 Docker 설치 후, 기존 Jenkins에 넣은 파이프라인 코드를 로드밸런싱을 목적으로 설정한 서버에도 구동할 수 있도록 적용했습니다.
또한 Nginx는 기존에 포워드프록시를 통해 애플리캐이션 서버로 보내게끔 설정이 되어있었는데, 해당 부분에 새로만든 서버 IP를 추가한 뒤, 라운드로빈을 통해 작동하게끔 설정했습니다.
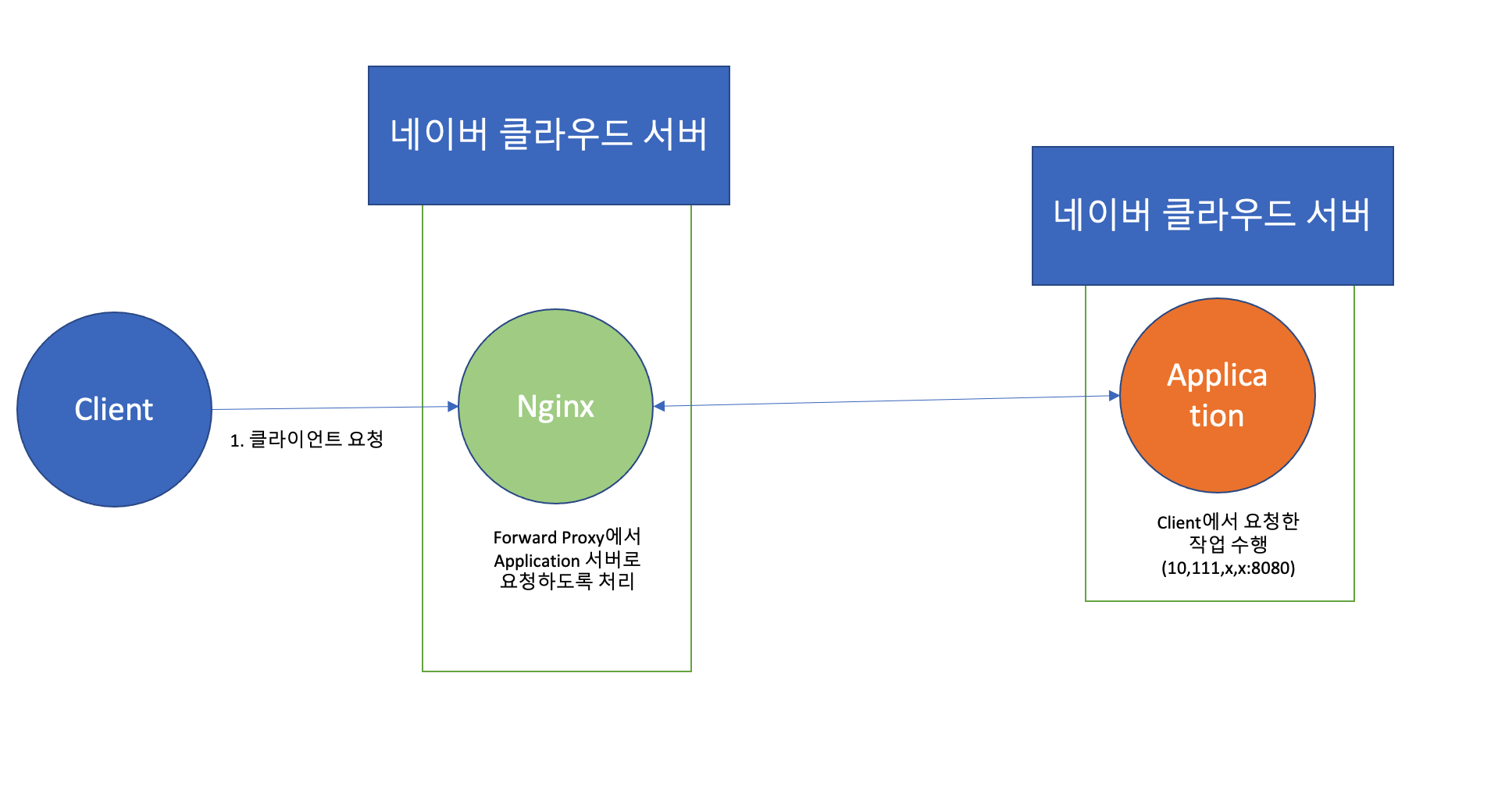
프로세스 구성
기존의 프로세스는 이렇게 구성이 되어있는데
이번 프로세스는 이렇게 되도록 구성하여, 트래픽 분산을 기대했습니다.
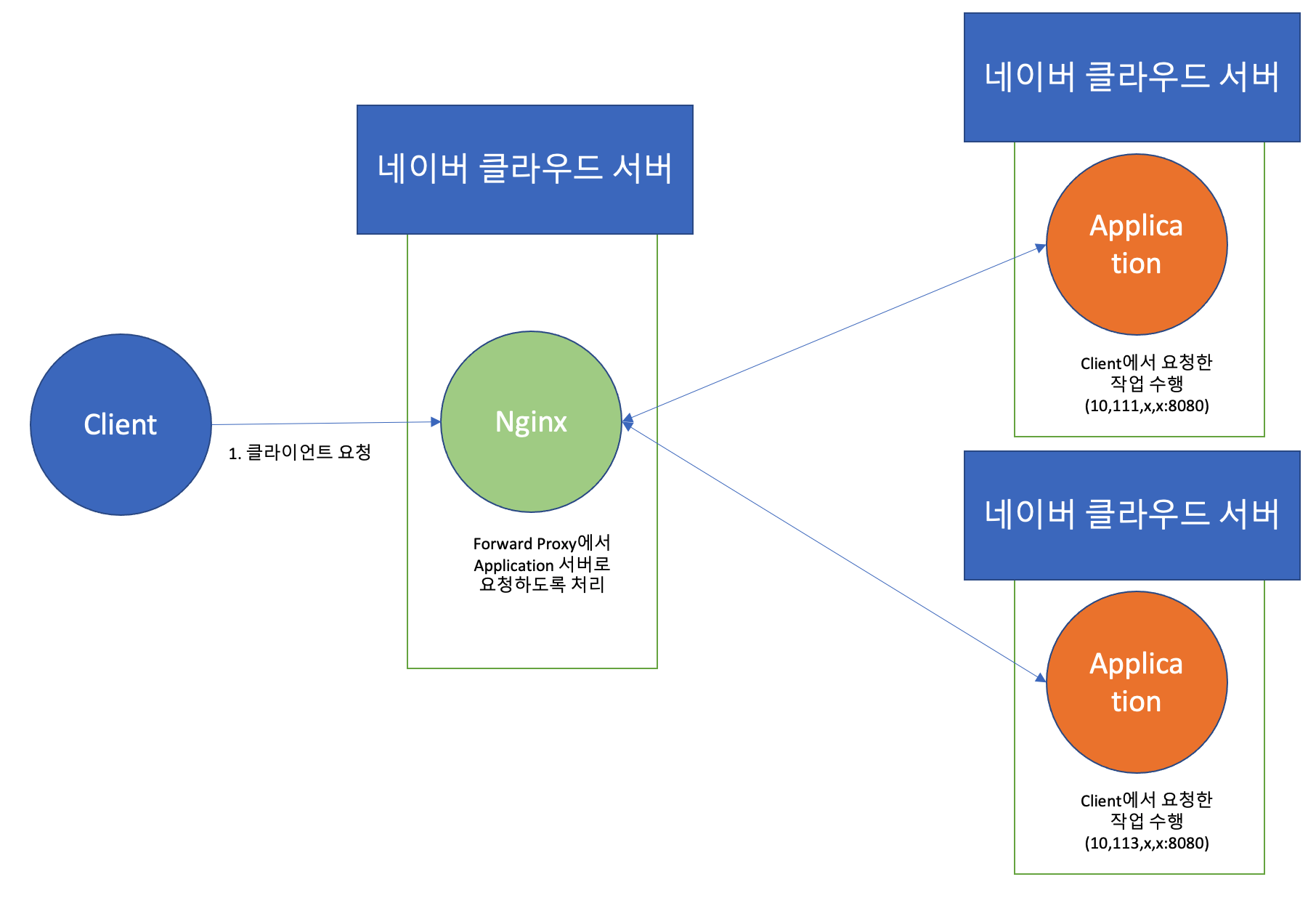
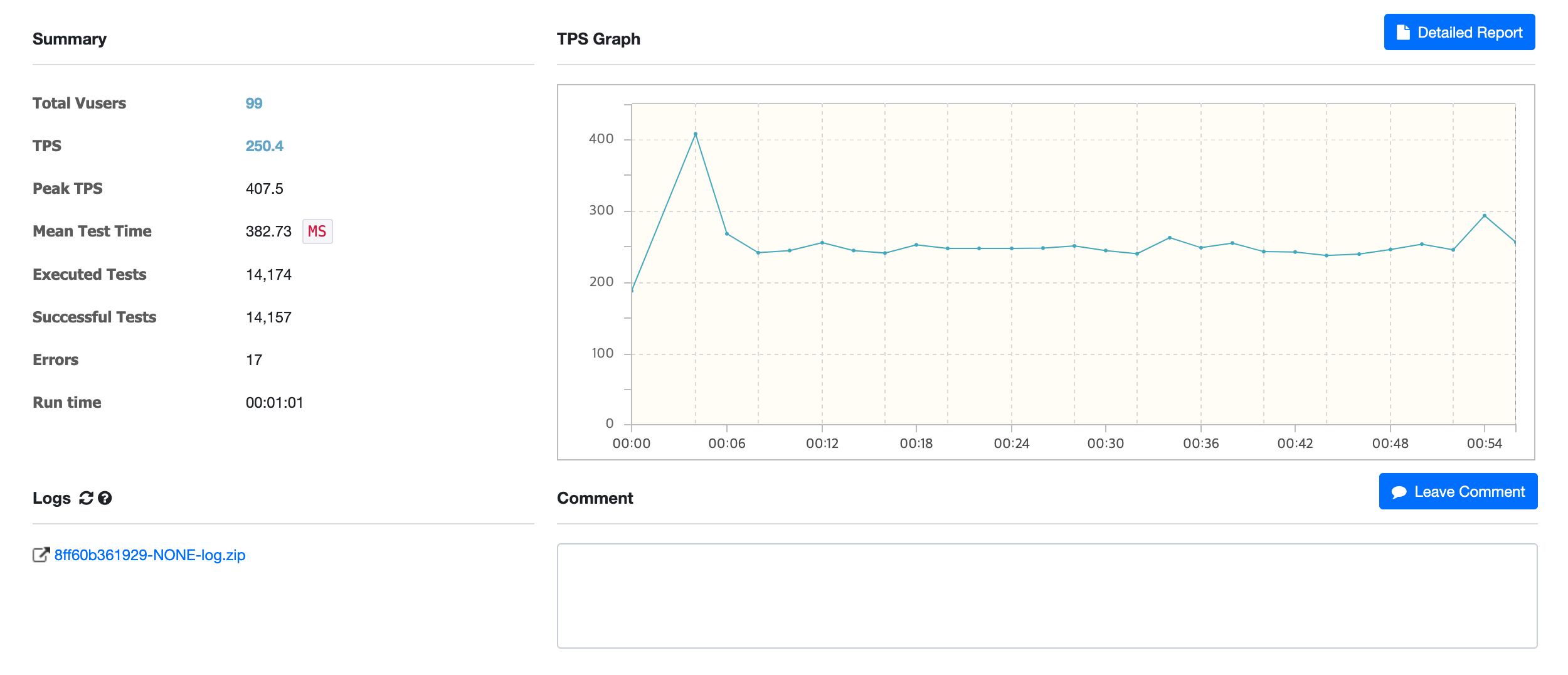
결과
이전에 비해 TPS 처리속도가 훨씬 높아진 것을 확인할 수 있습니다.
또한 기존에 발생한 이슈인 그래프의 변동폭 역시 이전에 비해 줄어든 것을 알 수 있습니다.
고려 할 점
로드밸런싱을 하게 될 경우, 결국 데이터의 동기화 작업을 해야되는 경우가 발생을 하게 됩니다. 결국 클라이언트는 포워드 프록시를 적용한 이상, 서버가 로드밸런싱이 된 상황을 전혀 모르기 때문이고, 서버와 서버 역시 서로 독립된 영역에 있기 때문입니다. 따라서 데이터 동기화를 위한 목적으로 별도의 Redis 혹은 Nginx에 캐시를 설정하여 동기화에 발생하는 이슈를 해결하는 것을 고려해볼 수 있을거 같습니다.
