
개요
자바에서 병렬화가 어떻게 작동하는지에 대한 작동원리 및 병렬 데이터를 처리할 때 성능처리는 어떻게 하는지 등 해당 내용을 설명하는 챕터이다.
기존 자바에서 병렬화
자바7이전에는 데이터 걸렉션을 병렬로 처리하기 어려웠다. 직접 서브파트로 분할하고 각각의 분할 된 서브파트를 각각의 스레드에 직접 할당해야 된다. 또한 이 과정에서 레이스컨디션이 발생하지않도록(운영체제 시간에선 이를 해결하기 위해 임계영역 및 락을 설정해서 스레드가 2개이상 못 들어가게 막아야한다고 알고있다.) 해야되는 점은 개발자들의 몫이였다. 자바 7에서는 이러한 병렬화의 에러문제를 최소화하기 위해 포크/조인 프레임워크를 제공한다.
병렬스트림
아래는 총합을 구하는 예시코드이다.
public long sequentialSum(long n) { return Stream.iterate(1L, i -> i +1) .limit(n) .reduce(0L, Long::sum); }대부분 이렇게 설정해서 총합을 구할 것이다. 하지만 이를 병렬로 처리하려면 어떻게 해야될까?
public long parallelSum(long n) { return Stream.iterate(1L, i -> i +1) .limit(n) .parallel() // 병렬 스트림으로 전환 .reduce(0L, Long::sum); }해당 코드와 같이 parallel을 추가하면 순차 스트림이 병렬 스트림으로 전환된다.
다음 코드는 병렬 -> 순차전환, 순차 -> 병렬 전환을 한 예시코드이다.
이렇게 작성하면 전체 파이프라인은 어떤 순차일까? 병렬 스트림일까?stream.parallel() //병렬스트림 .filter() .sequential() // 병렬->순차스트림 전환 .map() .parallel() // 순차->병렬스트림 전환 .reduce();답은 병렬이다. 이유는 최종적으로 호출 된 메소드가 전체파이프라인에 영향을 미치기 때문이다. 즉 parallel이 최종적으로 호출이 되었기 때문에 병렬이다.
스트림 성능 측정
- 병렬화를 이용하면 순차나 반복에 비해 성능이 좋아질거라 생각하지만 꼭 그렇지는 않다.
- 성능최적화를 할 때는 가장 중요한건 단 하나다. 답은 측정이다.
- 측정을 위해선, JMH라는 라이브러리를 활용해 측정해볼 수 있다.
(여담이지만 난 gradle로 했다.)
결과는 놀라웠다.
우리가 흔히 알고있는 for문이 타 문장에비해 월등히 빨랐다. 그러면 저번 블로그에 말했던 것처럼 언박싱이슈를 해결한 병렬처리 및 순차처리를 넣으면 어떻게 될까?
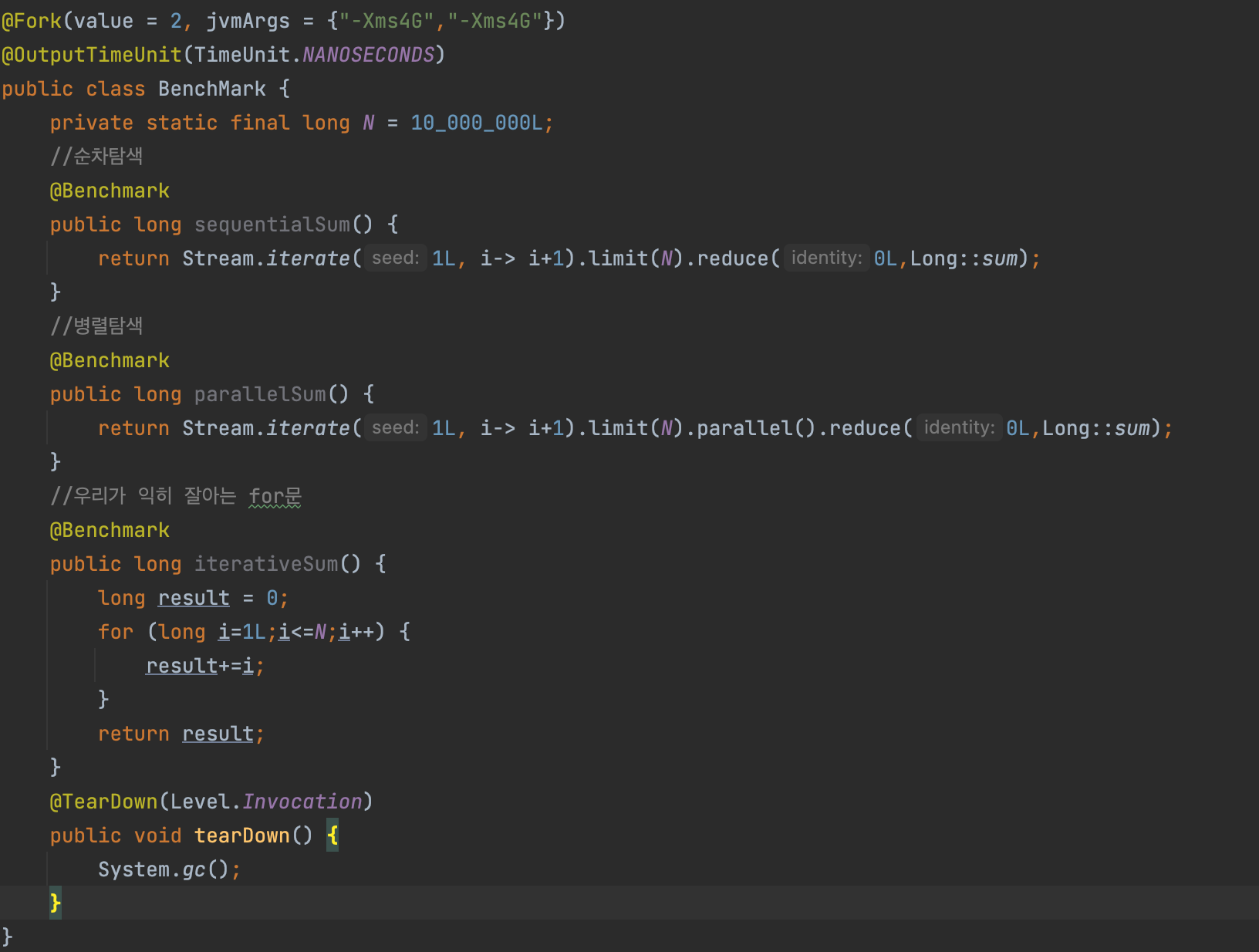

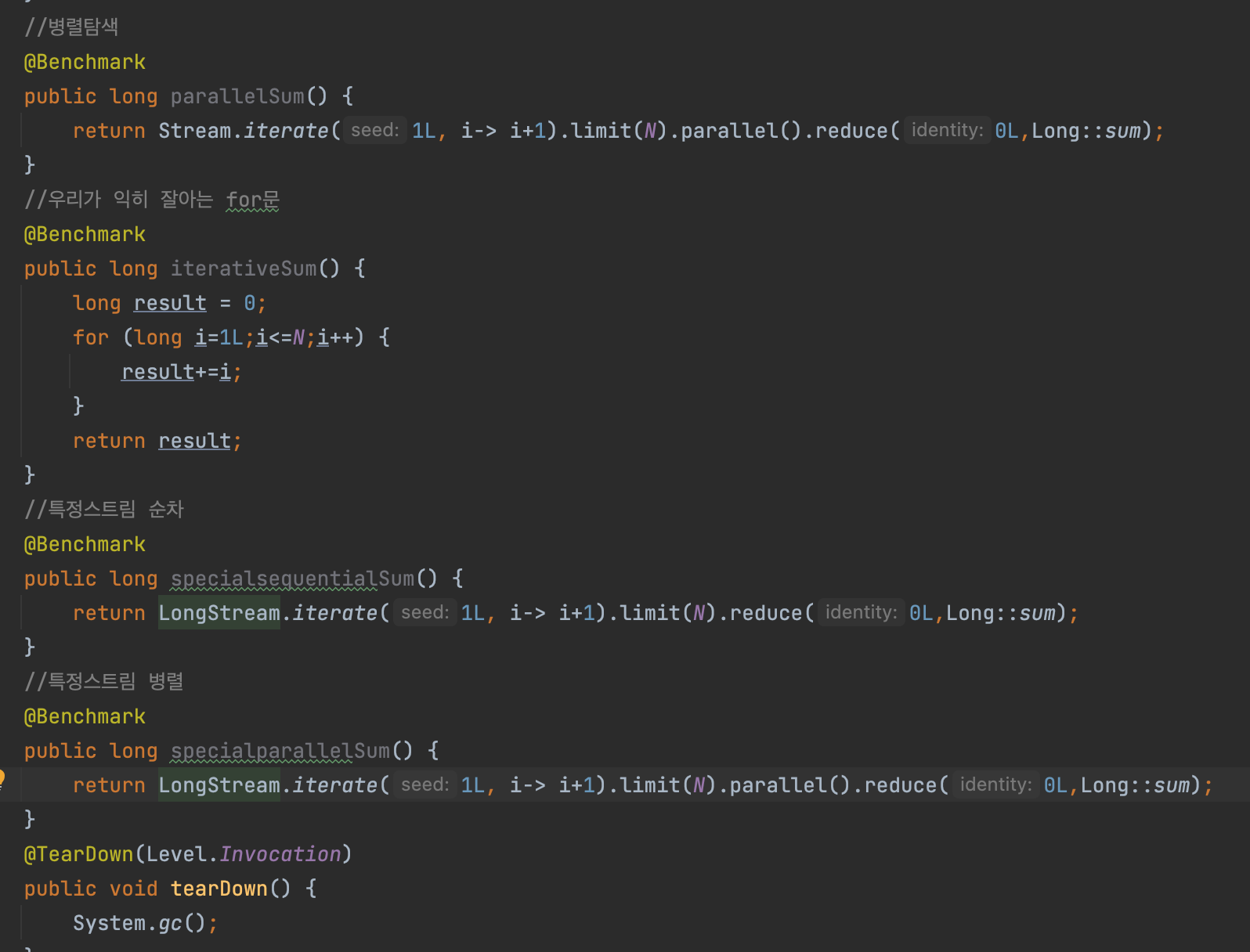
아래와 같이 특정스트림 순차 및 병렬일때 천만건 총합이 얼마나 걸리는지 확인해보겠다.
결과는 다음과 같다.
빠른순으로
for문 < 특화스트림(순차) < 특화스트림(병렬) < 일반스트림(순차) < 일반스트림(병렬) 순이었다.
따라서 우리가 생각하는 언박싱의 영향이 생각보다 크고 순차적인건 태스크를 나누는것과 병햡하는데 드는 오버헤드 역시 이 상황을 만들어낸 요인이라고 생각한다.

병렬 스트림 효과적으로 이용하는법
- 직접측정해라
- 박싱을 주의해라
- 순차 스트림보단 병렬스트림에 성능이 떨어지는 연산이 있다. limit와 findFirst의 경우 요소의 순서에 의존하기 때문에 병렬로 할 경우 더 오래걸릴 수 있다.
- 스트림 수행시 전체파이프라인 연산비용을 고려해라 요소수가 N이고 N하나하나를 실행할 때 Q가 걸린다고 할 때, Q가 길수록 병렬로 처리하는 것이 유리하다.
- 소량의 데이터는 병렬 스트림이 도움이 안된다. 오버헤드와 같은 부가비용이 더 많이 발생하기 때문이다.
- 스트림 시 자료구조가 적절한지 확인해야한다. ArrayList의 경우 인덱스로 쉽게 찾을 수 있지만 LinkedList의 경우 리스트를 계속 순회하면서 찾으면서 분할을 해야되지만 List는 인덱스를 통해 나누면 되기 때문이다.
- 스트림의 특성 및 파이프라인 중간연산에 따라 성능이 다를 수 있다. 필터연산의 경우 분할을 할 때 정확히 반으로 분할 되는 것이 아니기 때문에 나누기가 어렵다.
포크/조인 프레임워크
쉽게 말하면 태스크를 분할을 한 뒤 합치는 과정을 말한다. 분할을 할 때는 compute메소드를 통해 분할 한다. 이는 분할정복알고리즘(병합정렬)과 비슷한 느낌인거 같다.
compute 코드는 다음과같다.if (태스크가 충분히 작거나 더 이상 분할할 수 없으면) { 순차적으로 태스크 계산 } else { 태스크를 두 서브 태스크로 분할 태스크가 다시 서브태스크로 분할되도록 이 메서드를 재귀적으로 호출함 모든 서브태스크의 연산이 완료될 때까지 기다림 각 서브태스크의 결과를 합침 }해당과정에 태스크가 너무 많이 분할되지는 않도록 주의해야한다.
(여담) 학교의 운영체제? 시스템프로그래밍 시간에 fork()를 c언어를 활용해 스레딩 구현코드를 작성했던 아련한 기억이 생각났다.
포크조인 프레임워크 역시 최적의 성능을 만드려면 여러 독립적인 서브테스크로 분할하고, 서브테스크 실행시간이 새로운 테스크를 포킹하는데 드는 시간보다 길어야한다.
작업훔치기
각각의 스레드는 자신에게 할당된 테스크를 포함한 이중 연결리스트를 참조해, 작업이 끝날 때 다른 스레드의 큐의 꼬리에 있는 정보를 가져온다. 아무래도 Queue가 fifo니까.. 계속 앞의 작업을 처리하면 다른 스레드의 꼬리의 작업정보를 가져올 수 있지않을까? 라고 추측한다.
Spliterator 인터페이스
스트림을 자동으로 분할해주는 인터페이스이다.
public interface Spliterator<T> { //해당 데이터에서 탐색할 요소가 더 있다면 true 아니면 false를 처리 // 전체글자가 있고, 탐색한 수가 전체글자 길이보다 크면 false처리 boolean tryAdvance(Consumer<? super T> action); // Spliterator의 일부 요소를 분할해서 2번째 Spliteratory을 만드는 메소드 Spliterator<T> trySplit(); // 탐색해야될 요소 수의 정보를 제공 // 너무많은 테스크를 만들지 않도록 한계점을 높게할 필요가 있음 long estimateSize(); // Spliterator 자체 특성 집합을 포함한 int 반환 //ex) return ORDERD+DISTINCT..; int characteristics(); }
후기
스래드 처리를 스트림을 통해 알게 될 줄은 몰랐다. 스레드 처리 역시 결국 내부반복을 스트림에서 처리하고 병렬처리역시 마찬가지이기 때문에 개발자가 이것에 대한 정확한 이해를 한 뒤에(생각없이 병렬처리를 때려박는 등) 스트림을 사용하는 것이 맞다고 생각이 들었다. 운영체제와 자바를 같이 공부하는 좋은 챕터였던 것 같다.
