
※ Notification
본 포스팅은 작성자가 이해한 내용을 바탕으로 작성된 글이기 때문에 틀린 부분이 있을 수 있습니다.
잘못된 부분이 있다면 댓글로 알려주시면 수정하도록 하겠습니다 :)
Intro
서울ICT이노베이션스퀘어에서 진행하는 인공지능 고급 과정(시각지능) 교육을 신청하여 수강을 하게 되었다.
수업 내용 정리를 위해 블로그를 개설했고, 매일 매일 배운 내용을 블로그 글로 정리하고자 한다.
오늘은 인공지능과 머신러닝, 딥러닝의 개요와 간단한 리뷰를 진행했다.
수업에 앞서 간단한 이야기와 수업 과정을 소개해주셨다.
Data
먼저 AI 국가전략 주요 성과 및 향후 계획 이미지를 보여주시면서 주요 성과가 모두 데이터에 관련돼있다는 이야기를 하셨다.
 데이터를 어떻게 모을 것이며, 그 데이터를 어떻게 Refinement, Cleansing 할 것인지 생각해봐야 하며, Data를 Gathering(모으고), Refinement(정제하고), train으로 변환하는 과정이 "BM(Business Model)"이 된다고 하셨다.
데이터를 어떻게 모을 것이며, 그 데이터를 어떻게 Refinement, Cleansing 할 것인지 생각해봐야 하며, Data를 Gathering(모으고), Refinement(정제하고), train으로 변환하는 과정이 "BM(Business Model)"이 된다고 하셨다.
수업을 들을 때는 Refinement와 Cleansing이 똑같은 것이라고 생각했는데 의문점이 생겨 찾아보니 Refining의 안에 Cleansing이 있는 것이었다.
Refining data consists of cleansing and shaping it.
https://www.ibm.com/docs/en/iis/11.7?topic=projects-refining-data
머신러닝/딥러닝은 앞으로 어떻게 될지 알 수 없지만, 데이터 관련 산업은 앞으로 중요해지지 않을 수가 없을 것 같다.
Computer vision
컴퓨터 비전이란 쉽게 말해서 인간의 시각 지능을 컴퓨터로 구현하는 것이다.
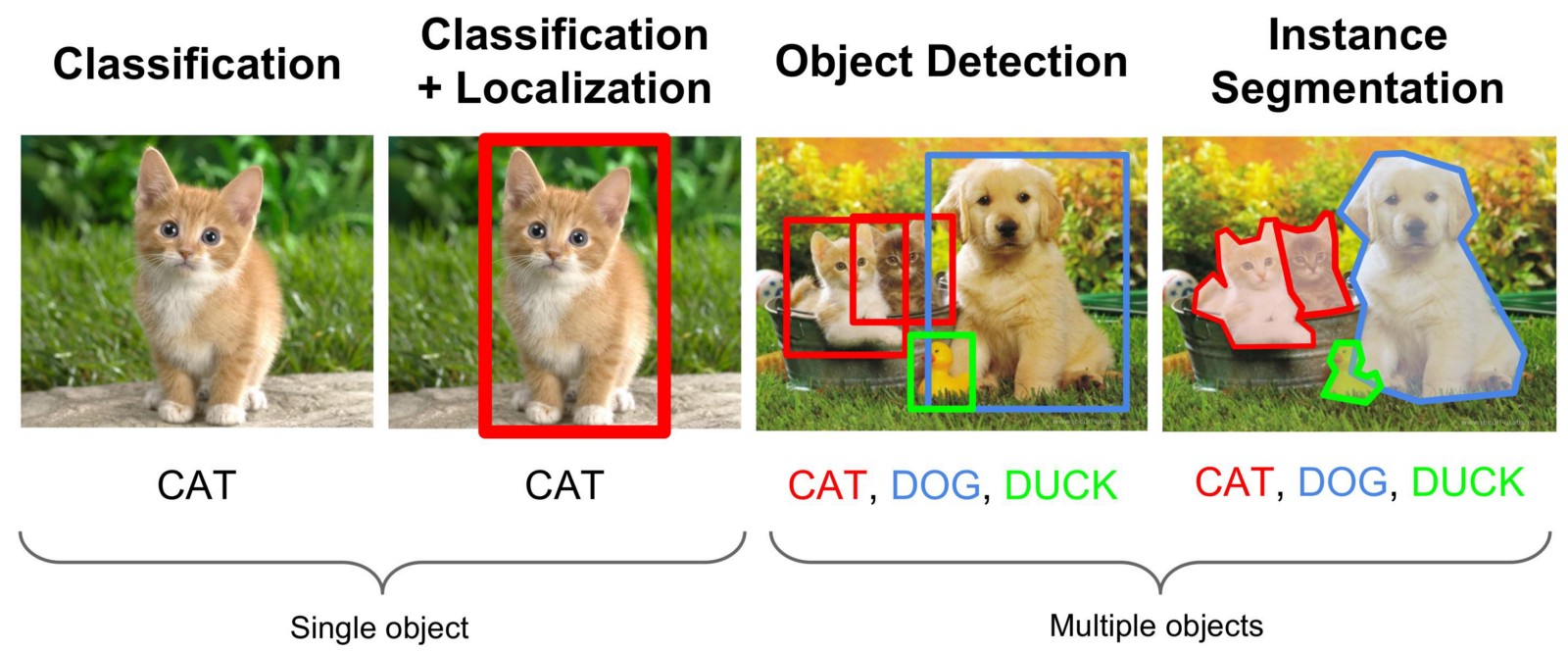 다음 그림에서 볼 수 있듯이 Computer vision에는 여러가지 분야가 있다.
다음 그림에서 볼 수 있듯이 Computer vision에는 여러가지 분야가 있다.
Cloud
클라우드에 대한 이야기도 잠깐 하셨다.
- 네트워크 사용
- 인스톨 필요 없음, 계정이 필요
- Lease 형태로 사용한 만큼 과금
클라우드의 중요 요소 3가지
- Virtualization(가상화) : 물리적인 것을 논리적으로 만드는 과정
ex) 12GB RAM을 1기가씩 12개로 나누는 것 - Provision(공급)
- Deployment(배포) -> Tenant(세입자)
![]()
Docker
도커 로고를 보면서 도커에 대해서 설명해주셨는데, Google Colab을 사용해서 수업을 진행하기 때문에 이야기 하신 것 같다.
고래 위에 얹어진 박스들을 컨테이너라고 하셨다.
우리가 아는 그 컨테이너가 맞다.
Virtual individual environment.
박스 하나 하나가 하나의 PC라고 생각하면 편하다.
이 얘기를 해주시면서 재미난 이야기를 해주셨는데 20세기 최고의 발명품이 컨테이너였다고 한다.
한번도 생각해본적 없었는데, 잠깐 생각해보니 컨테이너가 없었을 때는 배로 짐을 옮길 때 비효율적이었을 것 같았다.
인공지능·머신러닝·딥러닝
인공지능
인간의 지능을 컴퓨터에 인공적으로 만든 지능
머신러닝
데이터를 이용하여 데이터의 특성과 패턴을 학습, 그 결과를 바탕으로 미지의 데이터에 대한 미래 결과(값, 분포)를 예측하는 것
핵심 Keyword : 데이터 / 학습 / 예측
예측없이 데이터를 분석/학습 하는 것은 데이터 마이닝
딥러닝
머신러닝의 한 분야로서 신경망(Neural network)를 통해 학습하는 알고리즘의 집합
머신러닝에 신경망을 추가한 것!
핵심 Keyword : 데이터 / 학습 / 예측 / 신경망
범위
인공지능과 머신러닝, 딥러닝의 범위를 살펴보면 다음과 같다.
인공지능의 subset으로 ML이 있고, ML의 subset으로 DL이 있는 것이다.
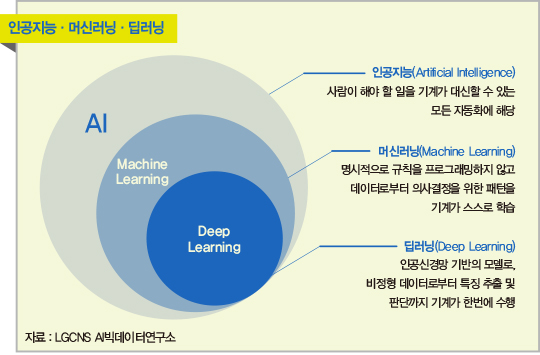 인공지능(AI)하면 ML/DL만 생각하기 쉬운데 인공지능의 다른 subset으로 어떤 것들이 있는지 설명해주셨다. 언급해주신 몇 가지만 적어보았다.
인공지능(AI)하면 ML/DL만 생각하기 쉬운데 인공지능의 다른 subset으로 어떤 것들이 있는지 설명해주셨다. 언급해주신 몇 가지만 적어보았다.
fuzzy theory(퍼지 이론)
사실 퍼지이론은 들어만 보고 뭔지 자세히 몰라서 대충만 찾아봤다.
퍼지 이론은 모호하다는 뜻으로 비가 '온다/안온다'가 아닌 '조금 온다'와 같은 '조금'이라는 단어가 갖는 모호함을 컴퓨터에 표현하고자 나온 이론인 것 같다.
가전제품에 사용되었다고 한다.
Robotics
로봇 공학 역시 인공지능인데 로봇이 인간의 일을 대신하기 때문이다.
머신러닝
머신러닝에는 지도학습, 비지도학습, 강화학습이 있다.
지도학습
지도학습은 - 회귀(Regression), 분류(Classification)로 나누어지며 입력(Input)으로 (X+T) 쌍을 준다.
여기서 X는 데이터, T는 정답(Target)
정답 값에 따라 Regression과 Classification을 나눈다.
- 회귀(Regression)는 continuous value를 정답으로 가지는 학습 데이터를 이용, 연속적인 (숫자) 값을 예측
- 분류(Classification)는 discrete value를 정답으로 가지는 학습 데이터를 이용, 주어진 입력값이 어떤 종류의 값인지 구별
주의할 점은 분류의 경우 uncontinuous가 아니라 discrete이라는 점이다.
그렇다면 실생활에는 회귀와 분류 중에서 어떤 것이 더 많이 사용될까?
다음 두 문장에서 사람들은 어떤 것을 더 많이 선호할까?
- "암일 확률이 66%이다."
- "암이다 or 암이 아니다."
대체로 사람들은 후자를 더 선호한다.
어차피 퍼센트로 결과가 나와도 의사한테 수술이 필요한지 물어볼 것이기 때문이다.
인간은 본질적으로 확률 값보다 정답을 알고 싶어한다.
이처럼 실생활에는 분류가 더 많이 사용되며, 인공지능은 인간의 지능을 대신하는 것이므로 인간의 특성을 반영한다.
비지도 학습
지도학습과 비지도 학습 중에서 어떤 것이 더 많이 사용될까?
결론부터 이야기하면 지도학습이 훨씬 더 많이 사용된다.
비지도 학습으로 분류가 된 결과는 어쨌든 사람이 한번더 확인하는 과정을 거쳐야 한다.
이러한 이유 때문에 지도학습이 훨씬 더 많이 사용된다.
실제로 이전에 학습 로그데이터를 이용해 비지도 학습을 진행한 적이 있었는데 군집의 결과를 분석함에 있어서 매우 어려움을 겪었던 기억이 아직도 생생하다.
군집마다의 특성은 있지만 엄청 명확하게 나뉘지도 않으며, 그 군집의 결과를 해석하는게 여간 쉬운일이 아니기 때문이다.
강화 학습
데이터도 없고 정답도 없음, 데이터와 정답 데이터를 만들어서 그것을 통해 지도학습
핵심 Keyword : Agent / Enviroment / Action / Reward
강화학습이란 Agent가 Action을 수행했을 때 그 Enviroment의 Reward가 최대로 되게 하는 것.
벨만 방정식, DQN에 대해서 이야기 해주셨다.
행렬(Matrix)
데이터 분야에서 Python이 사용되는 이유?
데이터 분야에서 Python을 사용한다는 것은 대부분의 사람들은 동의할 것이다. 그렇다면 왜 하필 Python일까?
- Python에는 Numpy가 있다.
Numpy는 벡터 및 행렬(Matrix) 연산에 있어서 매우 편리한 기능들을 제공한다. - 세상의 거의 모든 데이터는 Image data로 표현할 수 있다.
- Image data는 Matrix로 변환이 가능하다.
이러한 때문에 데이터 분야에서 Python을 많이 사용하는 것이며 Numpy를 이용해 Matrix를 다룬다.
ML/DL
system이란 무엇일까?
System이란 우리가 원하는 출력을 만들기 위해 입력을 어떻게 처리할지 정의하는 것이다.
- Input -> [Processing] -> Output
ML/DL도 마찬가지이다.
- (X, T) -> X·w+b => Y, T(예측값)
X는 입력, T는 정답
Y-T(예측값)를 비교 => loss 손실(오차)
이렇듯 loss가 최소로 되도록 미분하는 것이 머신러닝의 처음이자 마지막
머신러닝의 궁극적인 목적은 손실이 최소화되는 w, b를 구하는 것!
데이터 관점에서 곱하기/더하기/행렬곱
데이터 관점에서의 곱셈
- 3 × 1 = 3
- 3 × 0 = 0
- 3 × 2 = 6
3을 입력 데이터, 3, 0, 6을 출력 데이터라고 생각한다면, 데이터 관점에서 본 곱셈은 입력 데이터에 대해 출력 데이터를 변화하기 위한 연산이다.
따라서 3이라는 값을 3, 0, 6으로 변경하기 위해 '× 1'을 하거나 '× 0'을 하거나 '× 2'를 하는 것이다.
데이터 관점에서 더하기
위 식을 보면 단순히 쉬운 덧셈이라고 생각할 수도 있을 것이다.
하지만 이를 다음과 같은식으로 변경할 수 있다.
이렇게 식을 변경하게되면 평균에 의한 곱셈으로 계산할 수도 있다.
잘 이해가 가진 않았지만 대충 어떤 느낌인지는 알 것 같다.
사실 이 부분을 정확히 못 들어서 정리를 못하겠다.
데이터 관점에서 행렬곱
이렇듯 데이터 관점에서 행렬곱은 더하기와 곱하기의 결합이다.
내적 이런거 다 필요없다고 하셨다.
Review
-
인공지능/머신러닝/딥러닝의 차이점
인공지능 : 사람의 지능을 흉내내어 만들어낸 것
머신러닝 : 데이터를 이용하여 데이터를 특성과 패턴을 학습해, 그 결과를 바탕으로 미지의 데이터에 대한 미래 결과(값, 분포)를 예측
딥러닝 : 머신러닝의 한 분야로서 신경망을 통하여 학습하는 알고리즘의 집합 -
지도/비지도/강화학습 차이점
지도학습 : 데이터, 정답 세트를 이용해 정답을 예측/분류
비지도학습 : 정답이 없고 입력 데이터만 있음
강화학습 : 데이터, 정답 없음, 데이터와 정답을 만들어서 지도학습 -
행렬이 왜 필요한지?
거의 모든 정보는 행렬로 변환 가능. 행렬을 이용해 Data 분석 가능 -
머신러닝의 궁극적인 목적은?
손실(loss)가 최소화되는 w, b를 구하는 것 -
더하기와 곱하기의 의미
곱하기는 입력값을 출력값으로 변환하기 위한 연산
더하기는 평균을 출력값으로 변환하기 위한 곱하기 연산
Outro
첫 수업이다보니 시스템에 적응하는 시간이 필요했다.
나름 정리한다고 메모장에 옮겨써놨는데도 블로그에 정리하려니 어지간히 시간을 많이 잡아먹는게 아니다.
내용을 좀 더 간략하게 할 필요가 있고, 좀 더 보기 좋게 쓰고 싶은데 블로그를 한번도 안해본 입장에서 너무 어렵게 느껴진다.
좀 더 익숙해질 필요가 있을 것 같다.
