
※ Notification
본 포스팅은 작성자가 이해한 내용을 바탕으로 작성된 글이기 때문에 틀린 부분이 있을 수 있습니다.
잘못된 부분이 있다면 댓글로 알려주시면 수정하도록 하겠습니다 :)
Intro
4일 차에 이어서 5일 차 포스팅을 이어가겠다.
Optimizer
Optimization은 loss를 최소화하는 weight와 bias를 찾는 것이며, Optimization의 알고리즘을 Optimizer라고 한다.
learning rate에 따라서 발산하기도 하며, Optimizer 별로 차이가 있다. 때문에 데이터에 따라서 어떤 Optimizer를 적용하냐도 중요한 요소일 것이다.
주로 이미지 분석에서는 Adam을 사용하며, 그 외에는 SGD를 사용하는게 더 좋다고 하셨다.
평소에도 Adam과 SGD에 대해서 궁금했었어서 좀 더 검색해 본 결과 잘모르면 Adam을 써라 라는 의견이 많이 보였다.
일반적으로 Adam이 더 잘 작동할지는 몰라도, 나는 데이터마다 상황마다 다르다고 생각한다. 한가지 예로 프로젝트에서 Adam으로 loss가 잘 줄어들지 않던 경우가 있었는데 SGD로 바꾸고 나서 훨씬 좋은 효과를 보여줬다. 때문에 무작정 Adam으로 하기보다는 Optimizer의 특성을 이해하고, 데이터와 모델의 특성들을 잘 조합해야 좋은 모델 완성되는 것 같다.
Dropout
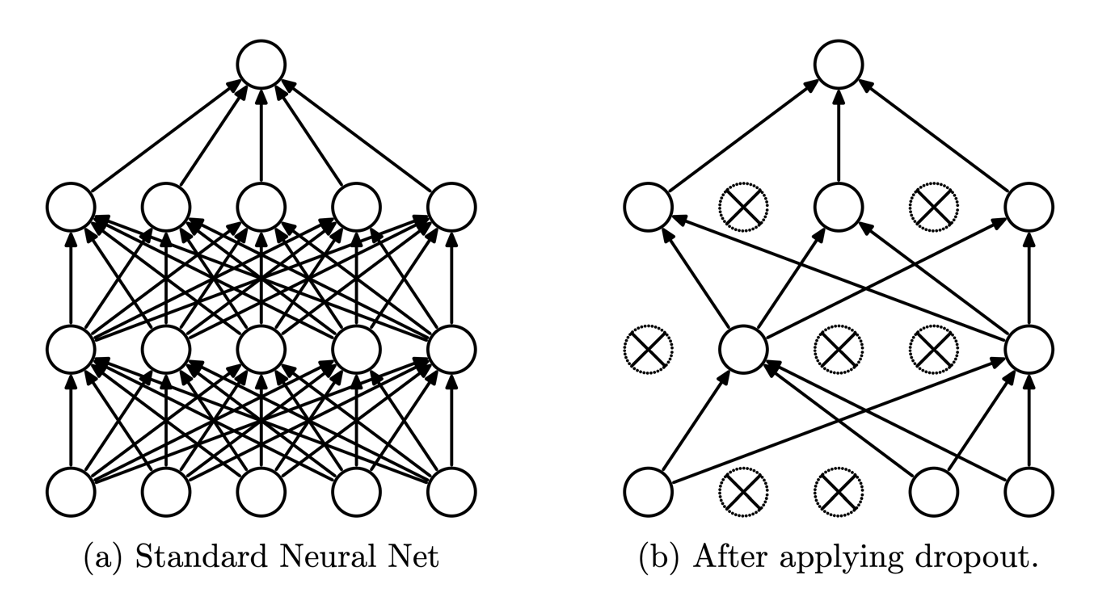
Overfit을 방지하기 위해 임의의 노드를 일정 확률로 drop하여 학습이 진행되지 않게 하는 것이다. 쉽게 설명하자면 노드와 노드 사이의 연결을 끊어 해당 노드를 동작하지 않게 하는 것! 일반적이라면 Dense와 Dense 사이에 들어간다.
여담으로 Dropout을 적용하면 안되는 층을 이야기하면서 입력층의 Dropout에 대한 이야기를 하셨는데, 어차피 입력층에 못쓸거면 아예 문법적으로 막으면 되지 않냐? 라는 질문을 받으셨다고 한다. 이에 대해 언어라는 건 문법적으로 제한을 두면 안된다고 하셨다. 차후에 Dropout의 기능이 개선되거나 진화하면 입력층 뒤에도 Dropout을 적용할 수 있을지 누가 알 수 있을까?
언어에 제한성에 대해서 예를 들어주셨는데, 과거에 한글의 'ㅋ'만 사용하는 글자가 없었다고 해서 'ㅋ'만 쓰지 못하게 문법적으로 제한했다고 한다면 현재의 'ㅋㅋㅋㅋ'라든지 그런 문법은 없었을 것이다.
이처럼 언어라는 것은 언제 어떻게 사용될지, 변형될지 모르는 것이기 때문에 제한을 두면 안된다고 하셨다.
Callback
Callback 함수는 알람시계를 떠올리면 된다.
시간을 설정하고 저장하면, 그 시간에 알람이 울린다.
즉, 어떤 특정한 상황이 발생했을 때 그 상황을 내가 알고싶어서, 특정한 상황을 저장하고 특정 상황이 오면 알림을 받을 수 있게 하는 매커니즘이 바로 Callback인 것이다.
우리 주위에서도 Callback을 흔히 찾아볼 수 있는데, 전화나 문자를 수신하면 진동이 울리는 것도, 애플리케이션에서 어떤 상황이 발생했을 때 알람이 울리는 것도 전부 Callback이라고 하셨다.
만약 Callback이 없다면? 우리는 Polling 방식처럼 전화가 오는지 안오는지 수시로 핸드폰을 확인해야될 것이다.
Checkpoint
Checkpoint는 현재 상황을 저장하고 백업하기 위해 사용한다.
Earlystopping
loss(혹은 다른 조건)가 더이상 감소하지 않을 때 모델 fit 시간을 줄이기 위해 사용한다. Overfit을 방지할 수 있다고 알고 있다.
ReduceLROnPlateau
lr이 너무 클 경우 Global minimum을 지나칠 수도 있으니 lr를 줄여줘서 더 잘 수렴할 수 있도록 해준다.
Hyperparameter
Hyperparameter는 주관적인 영역이기 때문에 회사라면 Hyperparameter에 대한 의사 결정 기준을 가지고 있어야 한다.
키가 크다 라는 기준을 세워놓는다면 누군가에게는 180cm가 큰 기준이 될 수도 있고 누군가에게는 200cm가 큰 기준이 될 수도 있기 때문에 정확한 기준이 필요하다.
Review
- TF에서 Model은 껍데기(틀)을 말한다.
이 껍데기(틀) 안에는 기본적으로 입력, 은닉, 출력 layer가 있다. - 이 layer를 바탕으로 feedforward라는 말이 나왔다.
- 모델을 통해 출력 값 Y가 만들어지면 정답 T와 비교해서 loss를 계산한다.
[MSE, binary_cross_entropy, categorical_crossentropy, sparse_categorical_crossentropy]
MSE - 출력층 Activation - liner
Binary classification - 출력층 Activation - sigmoid / 출력 Node 1개
Categorical classification - 출력층 Activation - softmax / 출력 Node 정답(클래스)의 개수 / One hot encoding 필요
Sparse categorical classification - 출력층 Activation - softmax / 출력 Node 정답(클래스)의 개수
Note
- Overfitting -> 없앨 수는 없지만 Dropout 등을 통해 줄일 수 있음, Rate는 Hyperparameter
- Callback은 학습 중 사용자에게 지정된 이벤트 알림을 보내는 것, ReduceLROnPlateau, Earlystopping, Model checkpoint.
Earlystopping과 Model checkpoint는 주로 같이 쓰이며 Earlystopping이 가장 많이 쓰인다. - train / val / test - random shuffle 할 때는 index를 shuffle해야 한다.
Outro
내용을 블로그에 정리해서 포스팅하는데는 분명히 시간이 걸리지만 글을 작성하면서 그냥 끄덕끄덕하고 넘어갔던 부분을 다시한번 찾아보면서 확실하게 알고 넘어가는 순기능이 있는 것 같다.
비록 밀려서 포스팅을 했긴 했지만 내일은 밀리지 않고 포스팅하려고 노력해야겠다.
