
Intro
본격적으로 이미지 처리 중 하나인 CNN을 학습했다.
이미지 데이터의 개념 및 표현, CNN이 어떻게 이루어지고 동작하는지 등을 학습했다.
Convolution
연속변수와 이산변수의 convolution 식은 다음과 같다.
이산변수의 식을 데이터 관점에서 이해하기 쉽도록 변경해보면 다음과 같다.
에 를 대입해 우리에게 익숙한 형태로 변경해보았다.
입력 데이터 를 변화시키기 위해 를 곱해준다고 해석할 수 있으며,
이전에도 설명했듯이 데이터 관점에서 덧셈 연산은 내부적으로 평균의 의미를 내포하고 있다고 해석할 수 있다.
이를 통해 식을 해석하면, 원본 데이터 또는 입력 데이터에 변화를 주어서 그 변화된 값들의 평균을 구한다는 의미이다.
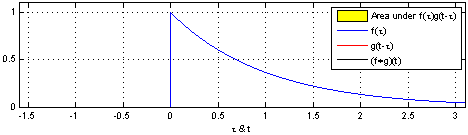 이미지 출처 : https://en.wikipedia.org/wiki/Convolution
이미지 출처 : https://en.wikipedia.org/wiki/Convolution
또한, 는 시간의 흐름을 나타내는 부분인데 위 사진에서 보는 것과 같이 가 시간에 따라 변화하면서 에 다양한 변화를 준다고 해석 할 수 있다.
이를 종합해서 Convoluntion을 해석하면 시간의 흐름에 따라 움직이는 데이터 에 의해서 입력 데이터 가 평균적으로 얼마나 변하는지 나타내는 것이라고 할 수 있다.
CNN
CNN의 구조는 다음과 같다.
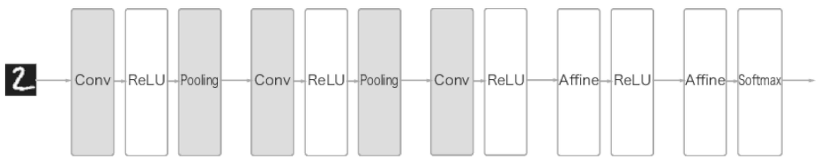 뒤쪽은 무시해도 되고 우선 중요한 부분은 Conv2D - Relu - Pooling 구조라는 것이다.
뒤쪽은 무시해도 되고 우선 중요한 부분은 Conv2D - Relu - Pooling 구조라는 것이다.
이미지가 들어오게 되면 Convolution 연산을 해주고 Relu를 통해 비선형성을 추가해주게 된다. 이러한 과정을 거친 후 Polling을 통해 데이터를 압축한다.
CNN 이미지 데이터 처리에서는 Relu를 가장 많이 사용한다고 하며, 이미지 데이터의 경우 데이터 크기가 상당히 크기 때문에 Pooling을 통해 압축을 진행하며, Max pooling을 가장 많이 사용한다고 한다.
Filter & Feature map
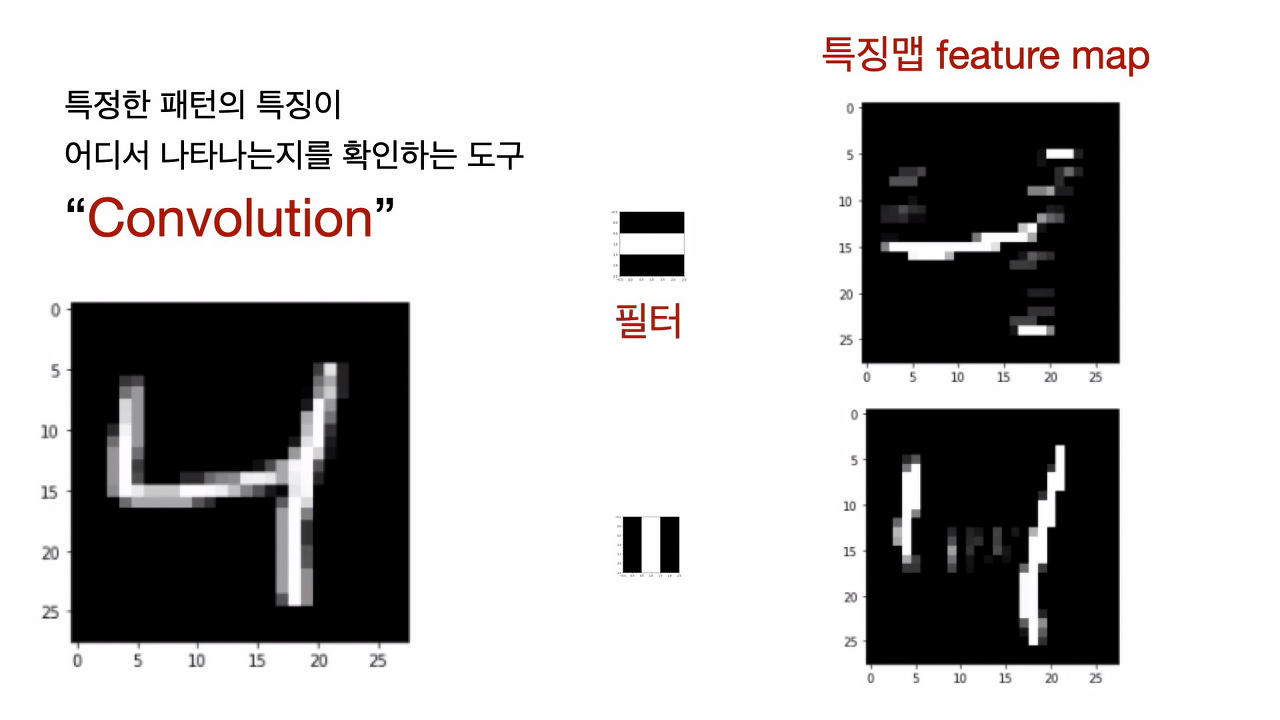
어떤 이미지 데이터가 주어지게 되면 Filter를 통해 Feature map을 추출할 수 있는데, 이를 다르게 말하면 Filter만 있다면 어떤 Feature map이든지 추출할 수 있다는 뜻이 된다. 그렇다면 Filter를 어떻게 알아낼까?
딥러닝이 발전하기 이전에는 Computer Vision에서 영상처리 학자들이 Filter의 조합을 찾아내는 일을 했따고 한다. 때문에 전문적인 영역에서 Filter를 만들었고, 수학적으로 매우 정교하게 Filter를 손수 만들었다고 한다.
지금 생각해보면 아주 노가다가 아닐 수 없다.
하지만 딥러닝이 나오고 나서는 랜덤으로 Filter를 넣고 추출하려는 Feature map을 결과값을 T로 줘서 loss를 계산, Filter를 구하는 방식으로 원하는 필터를 만든다. 때문에 수학적인 노가다 없이도 Filter를 손쉽게 구할 수 있다.
Padding
CNN을 하다보면 Conv2D와 Polling에서 모두 Padding이 있는데 두 Padding은 약간의 차이가 있다.
Conv2D의 Padding의 경우 이미지의 손실을 방지하기 위해 연산 전에 주위로 Padding을 더해주는 것이고, Pooling의 경우 모서리 부분에 일부분의 데이터만 있을 경우 이 데이터를 살리기 위해 Padding을 더해 손실을 줄여주는 것이다.
Image Data
이미지 데이터에 대해서도 길게 설명을 해주셨는데 3차원 텐서면 이미지 데이터인가요?라는 질문에서 시작됐던 것 같다.
흑백 이미지의 경우 (28,28,1)과 같이 표시하며, 컬러 이미지의 경우 (28,28,3)과 같이 표현한다. 하지만 이는 이미지 데이터이기 때문에 3차원 텐서로 표현하는 것이 아니라. 이미지를 표현하기 위해 3차원의 텐서로 표현하는 것이다.
말이 좀 헷갈릴 수 있는데 이미지를 (Width, Height, Channel)로 표현하니까 3차원 텐서인 것이지, 3차원 텐서라서 이미지 데이터인 것이 아니다.
이미지 데이터가 아닌 다른 데이터를 3차원 텐서로 표현하려면 얼마든지 할 수 있다는 이야기이다.
Image data와 Channel의 개념에 대해서도 헷갈리지 말고 잘 알고 넘어가야 한다고 하셨다.
Note
- Conv : 적분
- Relu : 비선형성 추가
- Pooling : 압축
- 컬러 이미지는 RGB 3개의 이미지가 겹쳐서 1개의 컬러 이미지가 된 것
- 필터는 가중치의 집합체
Outro
오늘은 CNN과 이미지 데이터, Filter, Feature map에 대한 이야기로 수업을 가득 채운 것 같다. 기본적으로는 알고 있었지만 자세한 원리를 설명해주시고 이해할 수 있어서 좋았다.
내일은 오늘 배운 것들을 이용해서 코딩을 하는 시간을 가질 것 같다.
