
삽입 정렬
삽입 정렬은 단순 정렬 분류에 속한다. 이해하기 쉬워서 이렇게 불리지만, 더 빠르다고 알려진 정렬 알고리즘보다 비효율적이다.
삽입 정렬을 살펴보자.
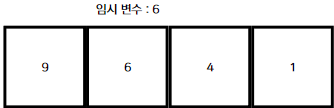
-
첫 번째 정렬에서 임시 변수에 인덱스 1의 값을 저장한다.
-
인덱스 1보다 왼쪽에 있는 값이 임시 변수의 값보다 크다면 그 값을 오른쪽으로 옮긴다.
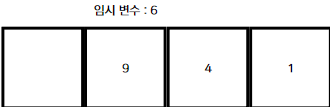
- 임시 변수를 공백에 삽입한다.

- 1부터 3까지 한 번의 정렬이다. 배열의 마지막 인덱스까지 반복한다.
삽입 정렬 구현
다음은 자바로 구현해본 삽입 정렬이다.
// 삽입정렬 메소드
public static int[] insertionSort( int[] array ) {
for( int i = 1; i < array.length; i++) {
// i번째 정렬마다 해당 인덱스 값 저장
int tmpValue = array[i];
// i번째 정렬마다 바로 전 인덱스인 i - 1 저장
int position = i - 1;
// 0 아래로 떨어지기 전까지 반복
while( position >= 0) {
// 비교 대상이 tmpValue보다 크다면 오른쪽으로 이동
if( array[position] > tmpValue ) {
array[ position + 1 ] = array[position];
position -= 1;
}
// tmpValue보다 크지 않다면 비교 끝
else {
break;
}
}
// tmpValue를 올바른 곳에 삽입
array[ position + 1 ] = tmpValue;
}
return array;
}삽입 정렬의 효율성
삽입 정렬은 네 가지 단계로 진행된다. 저장 , 비교 , 이동 , 삽입이다.
하나씩 살펴보자.
비교는 정렬마다 시작하는 인덱스의 왼쪽에 있는 값과 임시 변수 값을 비교할 때마다 일어난다.
만약 최악의 케이스( 역순으로 정렬 )라면 왼쪽의 모든 값이 시작 값보다 클 것이므로 모두 비교해야한다.
원소가 다섯 개라면 1 + 2 + 3 + 4 = 10
원소가 만약 열 개라면 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 = 45가 될 것이다.
원소가 N개라면 1 + 2 + 3 + 4 ... + N-1이다.
5² / 2 = 12.5 이고 10² / 2 = 50이니 이를 N² / 2로 표현할 수 있다.
이제 이동을 살펴보자.
이동은 인덱스를 한 칸 오른쪽으로 옮길 때마다 일어난다.
만약 배열이 최악의 케이스( 역순으로 정렬)라면 비교 할 때 마다 오른쪽으로 이동시켜줘야하니 비교 횟수만큼 이동이 일어난다.
비교와 이동의 횟수를 합쳐보자.
(5² / 2 ) + ( 5² / 2 ) = N²이다.
남은 저장과 삽입을 살펴보자. 저장은 정렬이 반복될 때마다 임시변수에 새로운 값이 저장되는 것을 말한다. 그리고 삽입은 매 정렬마다 한 번씩 일어난다. 정렬은 N - 1번 일어난다. 마지막 인덱스는 실행 과정이 없어도 우리는 정렬되었다는 것을 알기 때문이다.
결국 N - 1 번의 저장과 N - 1 번의 삽입이 일어난다.
저장과 삽입의 횟수를 합치면
(N - 1) + (N - 1) = 2N - 2이다.
비교 , 이동 , 저장 , 삽입의 총합은 N² + 2N - 2가 될 것이다.
빅 오는 다른 차항과 상수를 제거한다. 따라서 삽입 정렬의 최악의 경우의 시간 복잡도는 O(N²)이다.
만약 주어진 배열이 최선의 경우와 가깝다면 삽입 정렬이 좋다. 반대로 최악의 경우와 가깝다면 선택 정렬이 더 빠르다.
