
해시 테이블
해시 테이블(hash table) 자료 구조는 key/value 데이터 쌍을 저장하는 효율적인 자료구조이며, 빠른 검색이라는 장점을 갖고 있다.
선형 검색과 이진 검색에는 배열을 차례대로 살펴봐야한다. 이진 검색의 시간 복잡도는 O(logN)이다. 이 정도만 되어도 매우 효율적인 알고리즘이다.
하지만 해시 테이블을 이용한다면 값 검색에 있어 딱 한 단계만 걸린다. 평균적으로 효율성이 O(1)이다. 어떻게 가능한 것일까?
해싱과 해시 함수
알파벳에 숫자를 부여해보자.
A = 1
B = 2
C = 3
D = 4
E = 5
F = 6
G = 7
H = 8
...
위 규칙에 따르면
CAB는 312
FAB는 612로 변환된다.
문자를 가져와 숫자로 변환하는 이러한 과정을 해싱(hasing)이라 부른다. 또한 ,임의의 크기를 가진 데이터(글자)를 특정 숫자(정수)로 변환하는 데 사용하는 함수를 해시 함수(hash function)이라 부른다.
이 밖에도 해시 함수는 다양하다. 또 다른 간단한 해시 함수에는 각 문자에 해당하는 숫자를 가져와 모든 수를 합쳐 반환한다. 이렇게 하면 BAD라는 단어는 214로 변환된 뒤 각 숫자를 합한 7이 된다.
또, 다른 해시 함수는 모든 수를 곱해서 반환하는 함수가 있을 수 있다.
물론 실제 쓰이는 해시 함수는 위의 예시보다 더 복잡하다.
해시 테이블로 값 검색하기
해시 테이블에서 값을 검색할 때는 키를 사용해 검색한다.
예를 들어보자.
키 "bad"의 값을 찾고싶다고 하자. "bad"의 값을 찾기 위해 간단히 표현해서 컴퓨터는 두 단계를 실행한다.
- 컴퓨터는 찾고있는 키를 해싱한다. BAD = 2 + 1 + 4 = 7 ( 실제 해시 함수는 더 복잡하다 )
- 결과가 7이므로 7번째 공간으로 찾아가서 저장된 값을 반환한다.
키가 값의 위치를 결정한다. 이로 인해 우리는 값을 찾기가 무척 수월해진다. 적절한 공간에 값을 넣기 위해 키를 해싱했던 것처럼 다시 한번 키를 해싱해 이전에 값을 넣었던 곳을 찾을 수 있다.
이제 해시 테이블의 값 검색이 평균적으로 O(1)이 걸리는지 알게됐다.
충돌 해결
해시 테이블은 훌륭한 도구지만 문제도 있다.
키/값 두 개를 저장하려한다.
먼저 키 "ABC"를 해싱한 곳에 값 5를 넣는다. 1 + 2 + 3 = 6이므로 6번째 공간에 "5"를 넣었다.
키 "BCA"를 해싱한 곳에 값 10을 넣는다. 2 + 3 + 1 = 6이다. 6번째 공간에 "10"을 넣으려고 보니 이미 5가 들어있다.
이처럼 이미 채워진 공간에 데이터를 추가하는 것을 충돌(collision)이라 부른다.
충돌을 해결하는 방법 중 하나는 분리 연결법(separate chaining)이다. 충돌이 발생했을 때 공간에 하나의 값을 넣는 대신 배열의 참조를 넣는 방법이다.
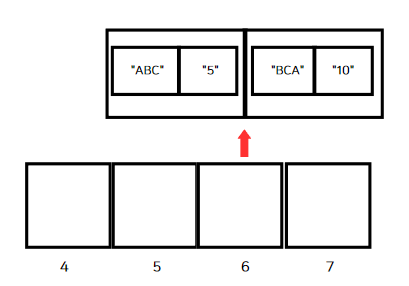
컴퓨터가 확인 하는 공간이 값이 아닌 배열을 참조하고 있다면 배열을 선형 검색해야한다. 그래서 테이블을 충돌이 가능한 적게 일어나게 설정해야한다.
충돌 조정
충돌을 가능한 적게 일어나게 하려면 데이터를 넓게 퍼뜨려야한다. 따라서 좋은 해시 함수란 사용 가능한 모든 셀에 데이터를 분산시키는 함수다.
이론상 충돌을 피하는 최선의 방법은 해시 테이블에 많은 셀을 두는 것인데, 이렇게 하면 메모리 낭비가 생길 수 있다.
그래서 좋은 해시 테이블을 구현하려면 메모리 낭비를 최대한 줄이는 쪽으로 균형을 유지하여 충돌을 피해야 한다.
충돌 조정을 위해 컴퓨터 과학자는 다음과 같은 경험에 기반한 규칙을 세웠다. 해시 테이블에 저장된 데이터가 7개면 셀은 10개여야 한다. 데이터와 셀 간이러한 비율을 부하율(load factor)이라 부른다. ( - 제이 웬 그로우 , 누구나 자료구조와 알고리즘 )
참고 자료📘
누구나 자료구조와 알고리즘

개발자로서 배울 점이 많은 글이었습니다. 감사합니다.