
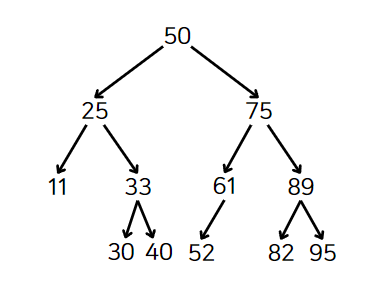
이진 탐색 트리
이진 탐색 트리(binary search tree)는 다음과 같은 규칙이 추가된 트리다.
-
각 노드의 자식은 최대 왼쪽에 하나, 오른쪽에 하나이다.
-
한 노드의 왼쪽 자손은 그 노드보다 작은 값만 포함할 수 있다. 또한 오른쪽 자손은 그 노드보다 큰 값만 포함할 수 있다.
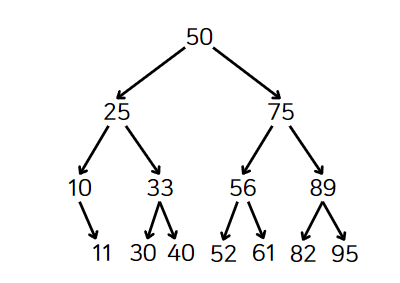
아래 이미지는 숫자 값이 들어있는 이진 탐색 트리이다.
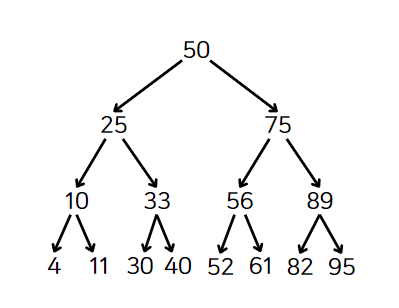
노드마다 노드의 왼쪽 자손에 해당 노드 값보다 작은 값을 갖고 있는 자식 하나, 오른쪽에 큰 값을 갖고 있는 자식 하나가 존재한다. 모든 노드는 같은 규칙을 갖고 있다.
트리 구현
다음은 자바로 구현한 이진 탐색 트리 클래스이다. 이진 탐색 트리의 여러 연산 메소드는 아래로 내려가면서 하나씩 추가해보자.
public class TreeNode {
private int value;
private TreeNode leftChild;
private TreeNode rightChild;
public TreeNode(int val) {
this.value = val;
}
public TreeNode(int val, TreeNode left, TreeNode right) {
this.value = val;
this.leftChild = left;
this.rightChild = right;
}
// getter setter
public int getValue() {
return value;
}
public void setValue(int value) {
this.value = value;
}
public TreeNode getLeftChild() {
return leftChild;
}
public void setLeftChild(TreeNode leftChild) {
this.leftChild = leftChild;
}
public TreeNode getRightChild() {
return rightChild;
}
public void setRightChild(TreeNode rightChild) {
this.rightChild = rightChild;
}
@Override
public String toString() {
return "TreeNode [value=" + value + ", leftChild=" + leftChild + ", rightChild=" + rightChild + "]";
}
}이제 아래와 같이 작은 트리를 만들 수 있다.
TreeNode node1 = new TreeNode(25);
TreeNode node2 = new TreeNode(75);
TreeNode root = new TreeNode( 50, node1, node2 );검색
이진 탐색 트리의 검색 알고리즘은 아래와 같은 단계로 진행된다.
-
노드를 "현재 노드"로 지정한다.
-
현재 노드의 값을 확인한다.
-
찾고 있는 값이면 반환한다.
-
찾고 있는 값이 현재 노드의 값 보다 작으면 왼쪽 하위 트리를 검색한다.
-
찾고 있는 값이 현재 노드보다 크면 오른쪽 하위 트리를 검색한다.
-
찾고 있는 값을 찾았거나 트리의 바닥에 닿을 때까지 위 과정을 반복한다.
위 단계로 검색을 진행해보자. 찾고자 하는 값은 61이다.
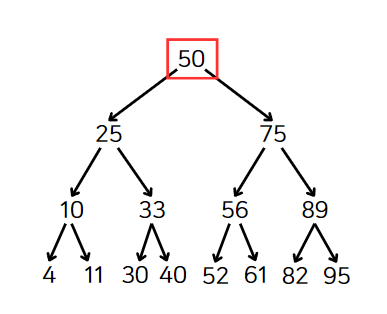
뿌리 노드부터 검색을 시작한다. 찾고 있는 값 61은 50보다 크므로 오른쪽 자식을 검색한다.
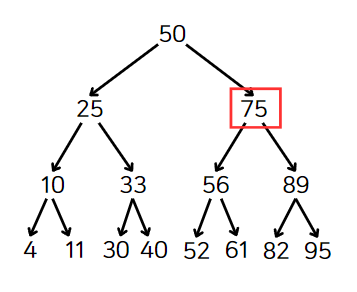
찾고 있는 값 61은 75보다 작다. 왼쪽 자식을 검색한다.
이러한 패턴으로 계속내려간다면, 56을 지나 61에 도달할 것이다. 50 -> 75 -> 56 -> 61 순이다.
이진 탐색 트리 검색의 효율성
원하는 값을 찾는데 4단계가 걸렸다.
이진 탐색 트리에서의 검색은 현재 노드와 주어진 값의 대소관계를 비교하여 단계가 진행될 때마다 왼쪽 혹은 오른쪽 하위 트리를 소거한다.
이는 정렬된 배열에서 중간 인덱스 값과 검색하고자 하는 값을 비교하여 왼쪽 혹은 오른쪽 인덱스를 뒤져보는 것과 같다.
즉, 이진 탐색 트리에서의 검색은 이진 검색과 같은 O(logN)이 걸린다.
이진 탐색 트리 : 검색 코드 구현
다음은 자바로 구현한 이진 탐색 트리 검색 메서드이다. TreeNode 클래스에 추가하였다.
// 이진 탐색 트리 검색 메서드
public TreeNode search( int searchValue, TreeNode node ) {
// 기저 조건: 노드가 없거나
// 찾고 있던 값이면
if( node == null || node.value == searchValue )
return node;
// 찾고 있는 값이 현재 노드보다 작으면
// 왼쪽 자식을 검색한다.
else if( searchValue > node.value )
search( searchValue, node.leftChild );
// 찾고 있는 값이 현재 노드보다 크면
// 오른쪽 자식을 검색한다
else
return search( searchValue, node.rightChild );
return null;
}삽입
정렬된 배열에서의 이진 검색과 이진 탐색 트리의 검색의 효율성은 O(logN)으로 같다.
검색 연산만 봤을 때는 트리가 그렇게 매력있는 자료구조가 아니지만, 나머지 연산에서는 이진 탐색 트리가 훨씬 더 좋다.
위에서 주어진 이진 탐색 트리에 45를 삽입해보자.
45를 삽입하기 위해서는 먼저 45를 붙이기 적절한 노드를 찾는 것이다.
45는 50보다 작으므로 왼쪽 자식으로 내려간다 -> 45는 25보다 크므로 오른쪽 자식으로 내려간다 -> 45는 33보다 크므로 오른쪽 자식으로 내려간다
트리 맨 아래 레벨 노드 중 하나인 40에 도달하였다. 이제 삽입할 준비가 되었다.
45는 40보다 크므로 40 오른쪽 자식 노드로서 45를 삽입한다.
삽입 효율성
삽입은 자식 노드를 계속 검색해가며 삽입하기 적절한 노드를 찾고, 삽입한다. 즉, 삽입은 검색에 걸리는 logN 단계에 삽입 1단계가 걸린다.
빅 오는 상수를 무시하므로 이진 탐색 트리의 삽입의 효율성은 O(logN)이다.
정렬된 배열에서의 삽입은 원소를 삽입하기 위한 공간을 만들기 위해서 원소들을 오른쪽으로 이동시켜야하기 때문에 O(N)이 걸린다.
이진 탐색 트리 : 삽입 코드 구현
다음은 자바로 구현한 이진 탐색 트리 삽입 메서드이다. TreeNode 클래스에 추가하였다.
// 이진 탐색 트리 삽입 메서드
public void insert( int value, TreeNode node ) {
if( value < node.value ) {
// 왼쪽 자식이 없으면 왼쪽 자식으로서 값을 삽입한다.
if( node.leftChild == null )
node.leftChild = new TreeNode(value);
else
insert( value, node.leftChild );
}
else if( value > node.value ) {
if( node.rightChild == null )
node.rightChild = new TreeNode(value);
else
insert( value, node.rightChild );
}
}삽입 시 주의할 점
균형 잡힌 트리를 만드려면 무작위로 정렬된 데이터로 트리를 생성해야한다.
만약 정렬된 데이터를 트리에 삽입하면 불균형이 심하고 덜 효율적일 가능성이 있다.
만약 1, 2, 3, 4, 5 순서로 삽입하면 다음과 같이 불균형한 트리가 생성될 것이다.
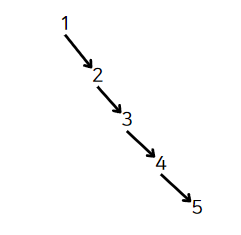
반대로 3, 2, 4, 1, 5 순서로 삽입하면 균형 잡힌 트리가 된다.
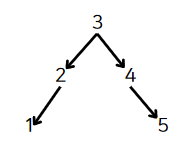
이러한 이유로 정렬된 배열을 이진 탐색 트리로 변환하고 싶다면 먼저 데이터 순서를 무작위로 만드는 것이 좋다.
균형 트리일 때만 검색 성능이 O(logN)이 걸린다는 것을 잊지 말자.
삭제
이진 탐색 트리에서 삭제는 고려해야할 경우의 수가 많다.
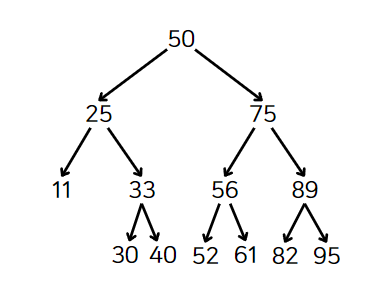
먼저 이진 탐색 트리에서 4를 삭제해보자.
문제 없이 가능할 것이다.
하지만 10을 삭제한다고 생각해보자.
그러면 11에 대한 링크가 끊어진다. 대신 10을 삭제한 자리에 11을 넣으면 문제를 해결할 수 있다.
위의 과정을 정리하면 다음과 같다.
- 삭제할 노드에 자식이 없으면 그냥 삭제한다.
- 삭제할 노드에 자식이 하나면 노드를 삭제하고 삭제된 노드가 있던 위치에 자식을 넣는다.
삭제 연산 시 위의 경우만 고려할 수 있다면 삭제 연산은 그리 까다롭지 않을 것이다.
노드가 자식이 둘일 때
하지만 자식이 둘인 노드를 삭제하는 경우의 수도 있는데, 이 경우가 가장 복잡하다.
56을 삭제해보자. 자식인 52와 61을 어떻게 하면 좋을까? 이 경우에는 새로운 로직을 적용시켜야한다.
- 자식이 둘인 노드를 삭제할 때는 삭제된 노드를 후속자(successor) 노드로 대체한다. 후속자 노드는 삭제된 노드보다 크지만, 큰 숫자 중 가장 작은 값을 갖는 자식 노드다.
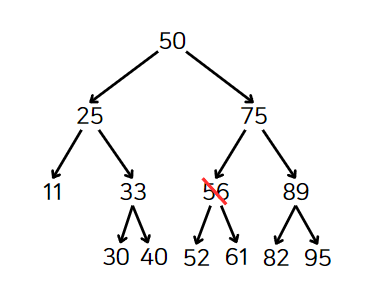
위의 트리에서 56보다 크지만 56보다 큰 값들 중 가장 작은 값은 61이 될 것이다. 즉, 61은 후속자 노드이고 56에 61이 들어가게 된다.
후속자 노드를 찾는 알고리즘은 다음과 같다.
- 삭제된 값의 오른쪽 자식으로 내려가서 그 자식의 왼쪽 자식을 따라 가장 아래 레벨에 있는 자식까지 내려간다. 바닥에 있는 노드가 후속자 노드다.
좀 더 복잡한 예제로 실제 동작을 살펴보자.
뿌리 노드(50)를 삭제해보자.
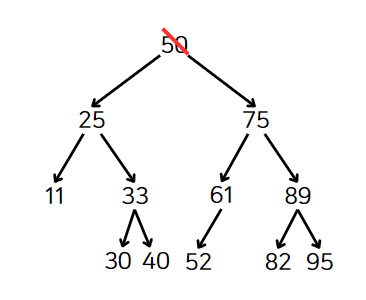
왼쪽, 오른쪽에 모두 자식 노드가 존재한다. 후속자 노드를 찾아야한다.
오른쪽 자식 노드에 먼저 내려간 후, 왼쪽 자식이 없는 노드가 나올 때까지 계속 내려간다.
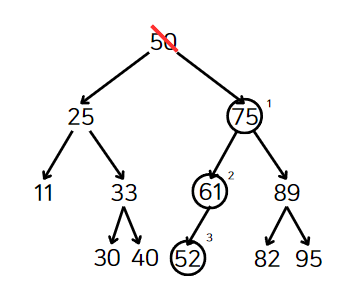
후속자 노드는 52이다. 삭제된 노드(50)에 52를 넣으면 끝이다.
후속자 노드에 오른쪽 자식이 있을 때
여기서 경우의 수가 하나 더 생긴다. 후속자 노드를 찾고 삭제된 노드에 넣는 것까지는 좋다.
하지만 만약, 후속자 노드에 오른쪽 자식이 있다면 이 경우도 생각해줘야한다.
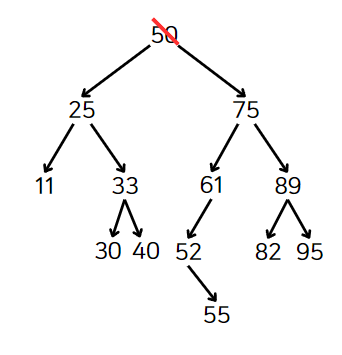
만약 후속자 노드에 오른쪽 자식이 있으면 후속자 노드를 삭제된 노드가 있던 자리에 넣은 후, 후속자 노드의 오른쪽 자식을 후속자 노드의 원래 부모의 왼쪽 자식으로 넣는다.
위의 트리에선 52를 삭제한 노드 위치에 넣고 55를 61의 왼쪽 자식으로 넣는다.
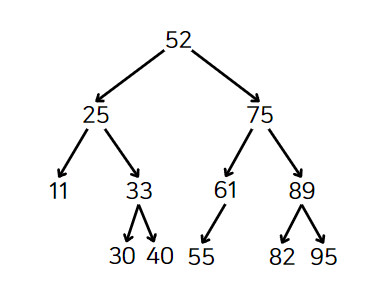
가장 복잡한 삭제 연산이 끝났다.
이진 탐색 트리: 삭제 코드 구현
다음은 자바로 구현한 삭제 메서드이다. TreeNode에 추가했다.
// 이진 탐색 트리 삭제 메서드
public TreeNode delete( int valueToDelete, TreeNode node ) {
// 트리 바닥에 도달해서 부모 노드에 자식이 없으면 기저 조건이다.
if( node == null ) return null;
// 삭제하려는 값이 현재 노드보다 작거나 크면
// 현재 노드의 왼쪽 혹은 오른쪽 하위 트리에 대한 재귀 호출의 반환값을
// 각각 왼쪽 혹은 오른쪽 자식에 할당된다.
else if( valueToDelete < node.value ) {
node.leftChild = delete( valueToDelete, node.leftChild );
// 현재 노드(와 존재한다면 그 하위 트리)를 반환해서
// 현재 노드의 부모의 왼쪽 혹은 오른쪽 자식의 새로운 값으로 쓰이게 한다.
return node;
}
else if( valueToDelete > node.value ) {
node.rightChild = delete( valueToDelete, node.rightChild );
return node;
}
// 현재 노드가 삭제하려는 노드인 경우
else if( valueToDelete == node.value ) {
// 현재 노드에 왼쪽 자식이 없으면
// 오른쪽 자식(과 존재한다면 그 하위 트리)를
// 그 부모의 새 하위 트리로 반환함으로써 현재 노드를 삭제한다.
if( node.leftChild == null )
return node.rightChild;
// (현재 노드에 왼쪽 또는 오른쪽 자식이 없으면
// 이 메서드 코드 첫 줄에 따라 null을 반환하게 된다.
else if(node.rightChild == null)
return node.leftChild;
// 현재 노드에 자식이 둘이면
// 현재 노드의 값을 후속자 노드의 값으로 바꾸는
// (아래) lift 함수를 호출함으로써 현재 노드를 삭제한다.
else {
node.rightChild = lift(node.rightChild, node);
return node;
}
}
return null;
}
// 이진 탐색 트리 삭제 lift 메서드
public TreeNode lift( TreeNode node, TreeNode nodeToDelete ) {
// 이 함수의 현재 노드에 왼쪽 자식이 있으면
// 왼쪽 하위 트리로 게속해서 내려가도록 메서드를 재귀적으로 호출함으로써
// 후속자 노드를 찾는다.
if( node.leftChild != null ) {
node.leftChild = lift( node.leftChild, nodeToDelete );
return node;
}
// 현재 노드에 왼쪽 자식이 없으면
// 이 함수의 현재 노드가 후속자 노드라는 뜻이므로
// 현재 노드의 값을 삭제하려는 노드의 새로운 값으로 할당한다.
else {
nodeToDelete.value = node.value;
// 후속자 노드의 오른쪽 자식이 부모의 왼쪽 자식으로 쓰일 수 있도록 반환해야한다.
return node.rightChild;
}
}삭제의 효율성
정렬된 배열이 O(N)인 것과 대조적으로, 이진 탐색 트리의 삭제 연산은 일반적으로 O(logN)이다.
순회
마지막으로 트리의 전체 노드를 접근하고 출력하는 방법을 알아보자.
자료 구조에서 모든 노드를 방문하는 과정을 자료 구조 순회(traversal)라 부른다.
순회 방법에는 여러 방법이 있지만, 여기서 중위 순회를 사용해보자.
순회는 다음과 같은 단계로 진행된다.
- 왼쪽 자식이 없는 노드에 닿을 때까지 traverse 함수를 재귀적으로 호출한다.
- 노드의 값을 출력한다.
- 노드의 오른쪽 자식에 traverse 함수를 재귀적으로 호출한다. 오른쪽 자식이 없는 노드를 찾을 때까지 함수를 계속 호출한다.
다음은 자바로 구현한 중위 순회이다.
public void traverseAndPrint( TreeNode node ) {
if( node == null) return;
traverseAndPrint(node.leftChild);
System.out.println(node.value);
traverseAndPrint(node.rightChild);
}코드가 간단하니 따로 설명은 적지 않겠다.
정리
이진 탐색 트리는 정렬 순서를 유지하면서 빠른 검색과 삽입, 삭제를 이용할 수 있다.
다만 굉장한 성능을 자랑하는 것과 비례해서.. 이진 탐색 트리를 학습하면서 삭제 연산을 이해하는데 꽤나 많은 시간이 들었다... 다른 연산은 충분히 이해가 되지만, 삭제 연산만큼은 훑고 지나갈 수가 없었다. (ㅠㅠ)
