
이진 힙
이진 힙(binary heap)은 특수한 종류의 이진 트리다.
이진 힙은 정렬된 배열로 큐를 구현하는 우선순위 큐보다 효율적인 자료구조로써 등장하게 되었다.
이진 힙에는 최대 힙(max-heap)과 최소 힙(min-heap) 두 종류가 있다. 종류라고는 하지만 둘 간에는 큰 차이는 없다. 한 번 알아보자.
힙은 다음의 규칙을 따르는 이진 트리다.
-
각 노드의 값은 해당 노드의 모든 자손 노드 값보다 커야 한다. 이 규칙을 힙 조건(heap condition)이라 부른다.
-
트리는 완전(complete)해야 한다.
힙 조건
힙 조건(heap condition)이란 각 노드의 값이 그 노드의 모든 자손의 값보다 커야 한다는 뜻이다.
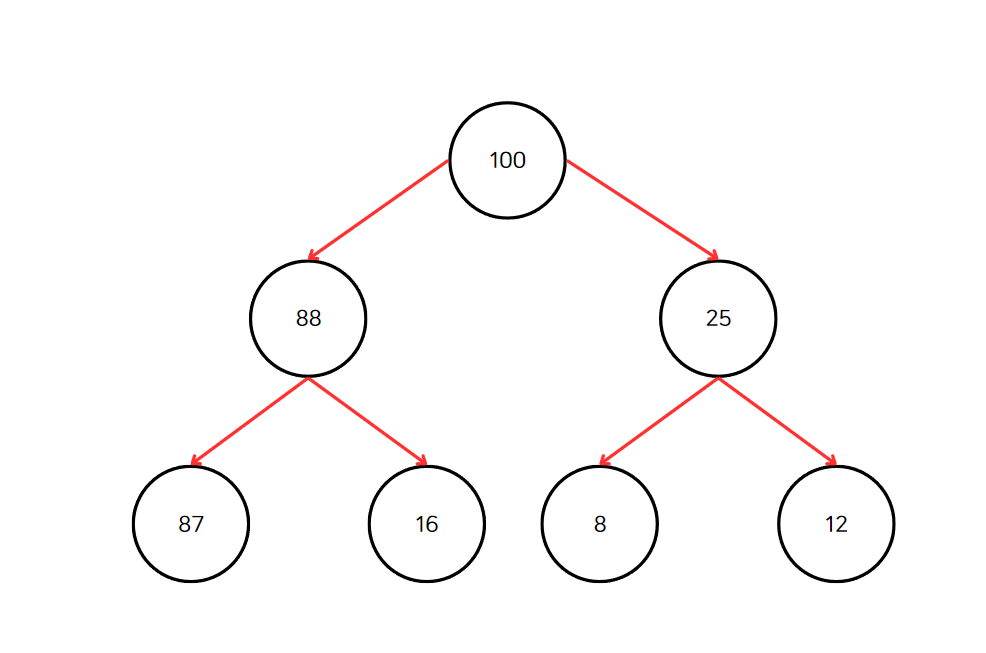
위의 이미지와 같이 루트 노드인 100보다 큰 자손은 없다. 그 하위 노드에 대해서도 마찬가지이다.
하지만 아래와 같은 트리는 힙 조건을 만족하지 않으니 유효한 힙이 아니다.
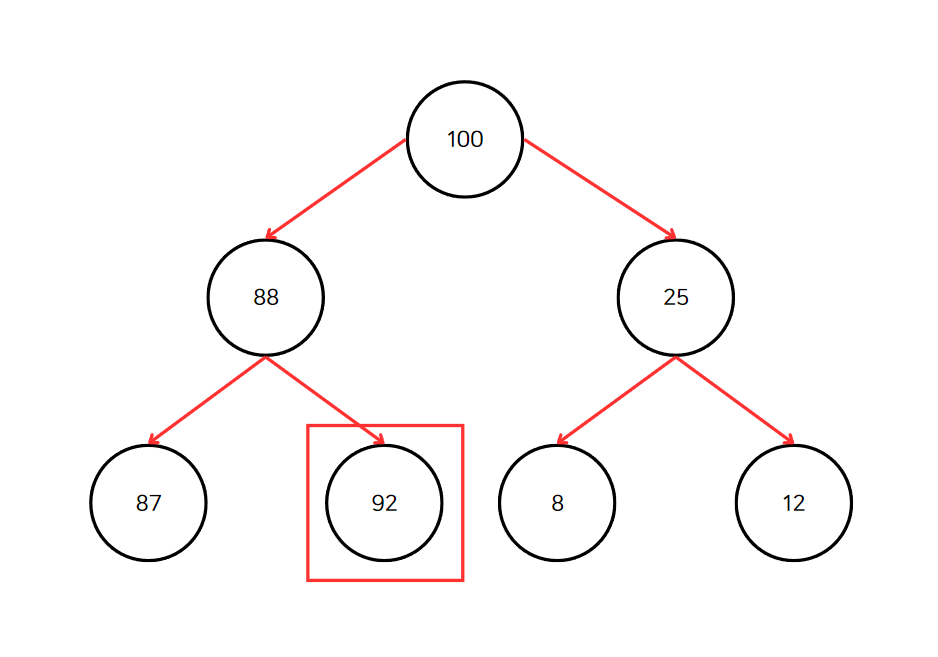
92가 부모 노드 88보다 크다. 힙 조건을 만족하지 않는다.
모든 노드의 크기가 자손보다 크다는 힙 조건을 만족하는 트리를 최대 힙이라고 한다. 반대로 노드의 크기가 자손보다 작다는 힙 조건을 갖는 트리를 최소 힙이라고 한다.
완전 트리
완전 트리(complete tree)는 빠진 노드 없이 완전히 채워진 트리다.
트리의 각 레벨을 왼쪽에서 오른쪽까지 읽었을 때 모든 자리마다 노드가 있어야한다.
하지만 바닥 줄에는 빈 자리가 있을 수 있는데, 이 때, 빈 자리의 오른쪽으로는 어떤 노드도 없어야 한다.
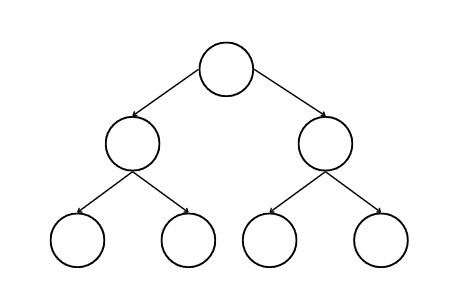
다음 세 개의 트리 중 어떤 트리가 완전하지 않은 트리일까? 한 번 생각해보자.
1.
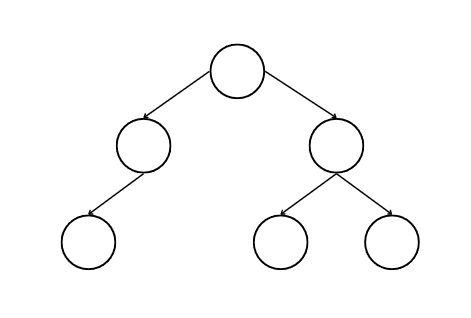
2.
3.
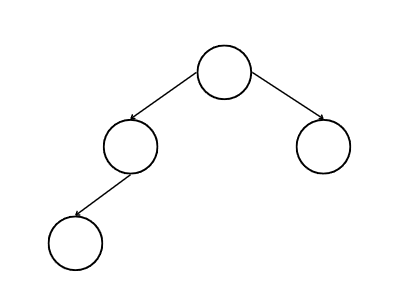
완전하지 않은 트리는 2번 트리이다. 1번 트리는 빈 노드 없이 가득 채워져있다. 3번 트리는 바닥 레벨에 모든 노드가 있지는 않지만, 노드의 오른쪽으로 어떤 노드도 없으므로 완전하다.
2번 트리는 세 번째 레벨에 한 노드가 빠졌으므로 완전하지 않다.
배열로 힙 구현하기
이진 힙은 내부적으로 트리 구조뿐만아니라 연결 리스트, 배열로도 구현할 수 있다.
하지만 배열로 구현하는 방식이 더 널리 쓰인다. 그 이유는 마지막 노드 문제를 쉽게 해결할 수 있기 때문이다.
마지막 노드 문제가 뭘까?이진 힙의 연산을 자세히 살펴보면서 마지막 노드 문제도 해결해보자.
삽입
힙에 새 값을 삽입하기 위해서는 다음과 같은 단계를 수행한다.
-
새 값을 포함하는 노드를 생성하고 가장 아래 레벨의 가장 오른쪽 노드 옆에 삽입한다. 이 값은 힙의 마지막 노드가 된다.
-
새로 삽입한 노드와 그 부모 노드를 비교한다.
-
새 노드가 부모 노드보다 크면 새 노드와 부모 노드를 바꾼다.
-
새 노드보다 더 큰 부모 노드를 만날 때까지 위의 1,2,3 단계를 반복하며 바닥 레벨에 있던 노드를 위로 상승시킨다.
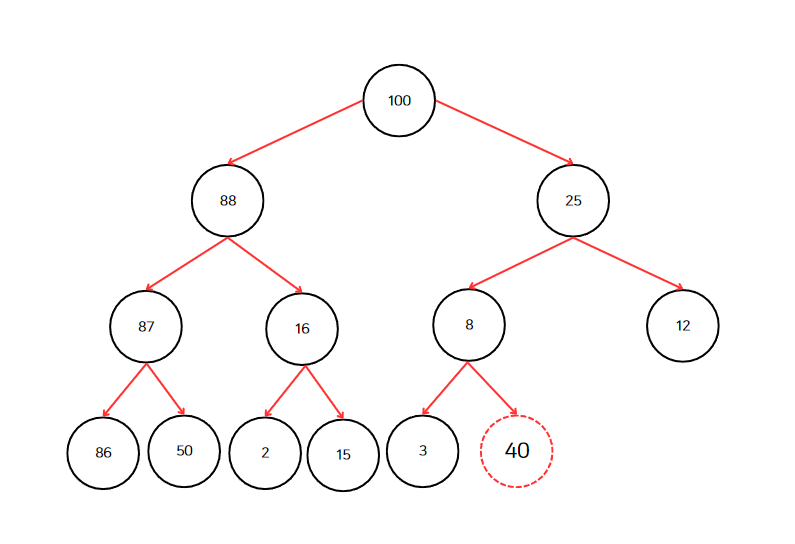
위의 단계를 따라서 값 40을 새로 추가해보자.
가장 아래 레벨 가장 오른쪽 노드 옆이라고 하였으니 값 3 옆자리에 삽입될 것이다.
그리고 2단계 40과 부모노드 8을 비교해보자. 40이 더 크다. 고로 8과 40을 바꾼다.
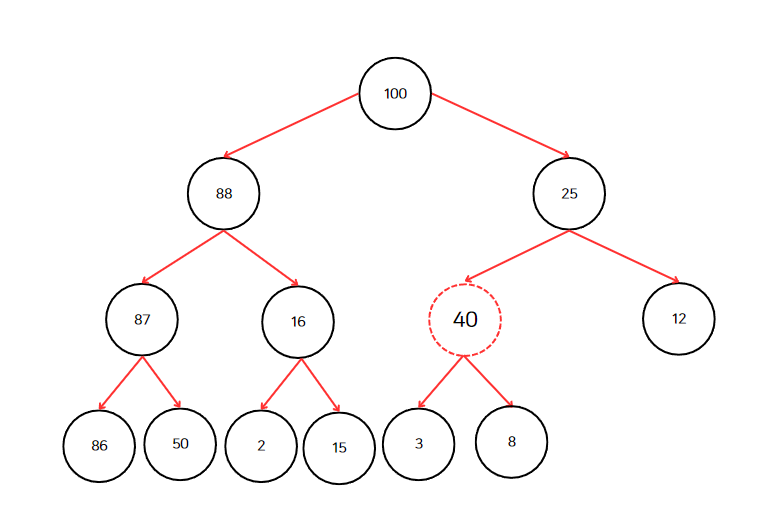 2단계부터 다시 반복한다. 40과 25를 비교한다. 40이 더 크므로 25와 40을 바꾼다.
2단계부터 다시 반복한다. 40과 25를 비교한다. 40이 더 크므로 25와 40을 바꾼다.
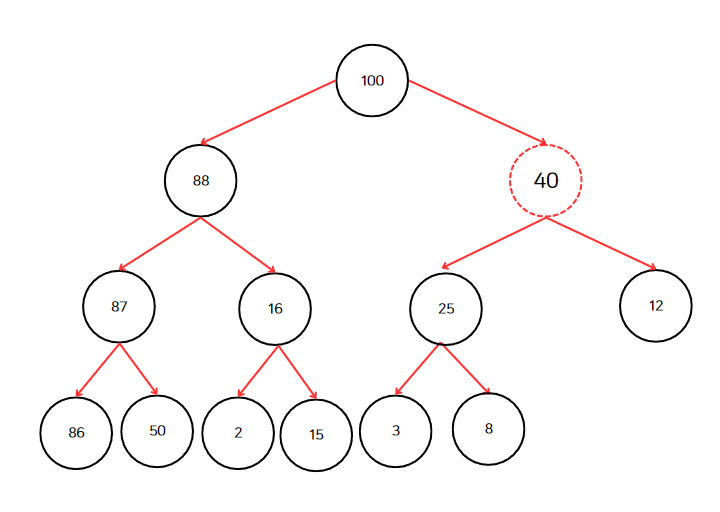 40과 부모 노드인 100과 비교한다. 40은 100보다 작으므로 끝이난다.
40과 부모 노드인 100과 비교한다. 40은 100보다 작으므로 끝이난다.
새 노드를 힙 위로 올리는 과정을 노드를 위로 트리클링(tricling)한다고 표현한다.
힙 삽입의 효율성은 O(logN)이다. 앞서 포스팅한 이진 탐색 트리와 같이 노드가 N개인 이진 트리는 약 log(N)개 줄을 갖으므로 최대 log(N)단계가 걸린다.
마지막 노드 탐색
새 노드를 마지막 노드에 삽입하고 트리클링 하는 것까지는 무척 간단해보인다. 그런데 앞서 말한 문제가 있다. 위의 1단계는 새 노드를 가장 아래 레벨 가장 오른쪽 노드 옆, 즉 마지막 자리에 넣는다.
이 자리를 어떻게 찾으면 좋을까?
이 마지막 노드 문제를 손쉽게 해결하기 위해 주로 힙을 배열을 사용해 구현한다.
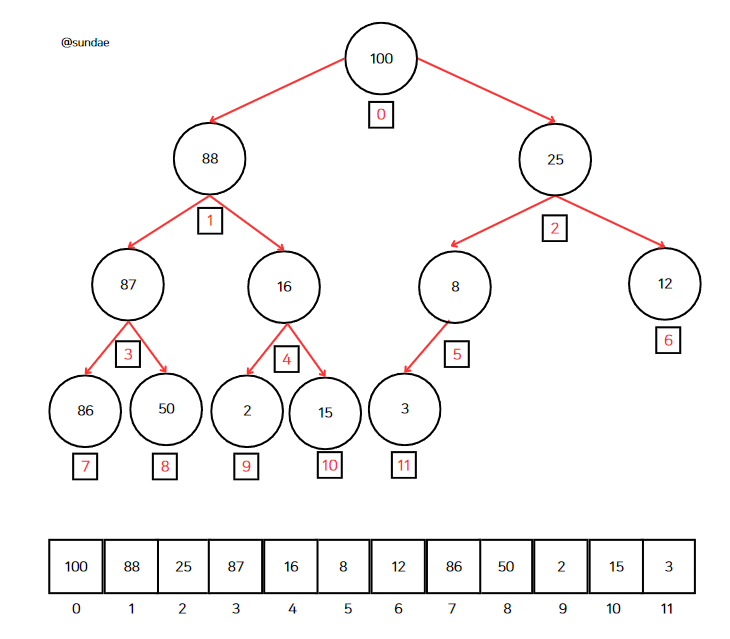 위의 그림은 값을 어떻게 배열에 저장하는지 보여준다.
위의 그림은 값을 어떻게 배열에 저장하는지 보여준다.
각 노드에 인덱스를 할당한다. 루트 노드는 항상 인덱스 0에 저장한다. 이렇게 힙을 배열로 구현하면 배열의 마지막 인덱스에 접근할 수 있어 마지막 노드 문제를 쉽게 해결할 수 있다.
힙 클래스 만들기
다음은 자바로 구현한 힙 클래스이다. 이번에 학습하면서 작성한 이진 힙 클래스는 제네릭 타입을 사용했다. 나중에 삽입이나 삭제 메서드에 비교 연산이 필요하므로 T 타입 클래스는 Comparable 인터페이스를 구현해야한다.
public class CusHeap<T extends Comparable<T>> {
private List<T> data;
public CusHeap(){
data = new ArrayList<>();
}
/*
* 루트 데이터 반환
* */
public T rootNode(){
if( !data.isEmpty() )
return data.get(0);
else
return null;
}
/*
* 마지막 데이터 반환
* */
public T lastNode(){
if( !data.isEmpty() )
return data.get( data.size()-1 );
else
return null;
}힙 삽입에는 노드를 위로 올리는 트리클링이 반복된다고 했다. 그렇다면 노드의 부모나 자식에 접근할 수 있어야 하는데, 이번 자료구조는 트리가 아닌 배열이다. 어떻게 노드에서 노드를 이동할 수 있을까?
여기에는 다행히도 공식이 존재한다. 다음과 같은 공식을 사용하면 노드의 부모나 자식에 접근할 수 있다.
- 어떤 노드의 왼쪽 자식을 찾으려면(index * 2) + 1 공식을 사용한다.
- 어떤 노드의 오른쪽 자식을 찾으려면 (index * 2) + 2 공식을 사용한다.
- 어떤 노드의 부모 노드를 찾으려면 (index-1) / 2 공식을 사용한다.
아래의 세 개의 메서드를 CusHeap 클래스에 추가했다.
/*
* 어떤 노드의 왼쪽 자식을 찾으려면(index * 2) + 1 공식을 사용한다
* 어떤 노드의 오른쪽 자식을 찾으려면 (index * 2) + 2 공식을 사용한다.
* 어떤 노드의 부모 노드를 찾으려면 (index-1) / 2 공식을 사용한다.
* */
public int leftChildIndex( int index ){
return (index * 2) + 1;
}
public int rightChildIndex( int index ){
return (index * 2) + 2;
}
public int parentIndex( int index ){
return (index-1) / 2;
}이진 힙 - 삽입 코드 구현
다음은 삽입 메서드이다. CusHeap 클래스에 추가했다.
/*
* 힙 삽입 메서드
* */
public void insert( T value ){
// value를 배열 끝에 삽입해 마지막 노드로 만든다.
data.add( value );
// 새로 삽입한 노드의 인덱스를 저장한다.
int newNodeIndex = data.size() - 1;
// 다음 루프는 "위로 트리클링"하는 알고리즘을 실행한다.
// 새 노드가 루트 자리에 없고
// 새 노드가 부모 노드보다 크다면
while( (newNodeIndex > 0) &&
( data.get(newNodeIndex)
.compareTo(data.get(parentIndex( newNodeIndex ))) > 0 )){
// 새 부모와 부모 노드를 스왑한다.
T tmp = data.get(parentIndex( newNodeIndex ) );
data.set( parentIndex( newNodeIndex ), data.get(newNodeIndex) );
data.set( newNodeIndex, tmp );
// 새 노드의 인덱스를 업데이트한다.
newNodeIndex = parentIndex( newNodeIndex );
}
}삭제
힙에서 값을 삭제할 때 루트 노드만 삭제할 수 있다는 제약이 있다.
이는 가장 높은 우선순위를 갖는 항목만 접근하고 삭제하는 우선순위 큐의 동작 방식과 일치한다.
힙의 루트를 삭제하는 단계는 다음과 같다.
- 마지막 노드를 루트 노드 자리로 옮긴다.
- 루트 노드를 적절한 자리까지 아래로 트리클링한다.
단계를 처음부터 수행해보자.
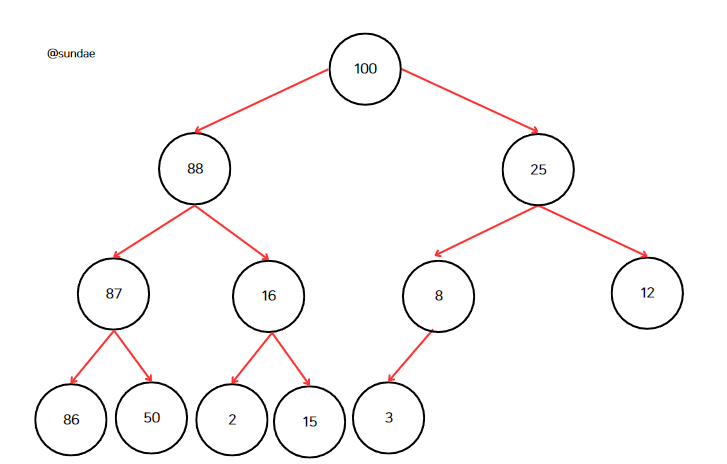 삭제 메서드를 호출했을 때 루트 노드인 100이 삭제가 되어야한다. 위의 1단계를 수행하면 마지막 노드 3을 루트 노드에 덮어쓴다.
삭제 메서드를 호출했을 때 루트 노드인 100이 삭제가 되어야한다. 위의 1단계를 수행하면 마지막 노드 3을 루트 노드에 덮어쓴다.
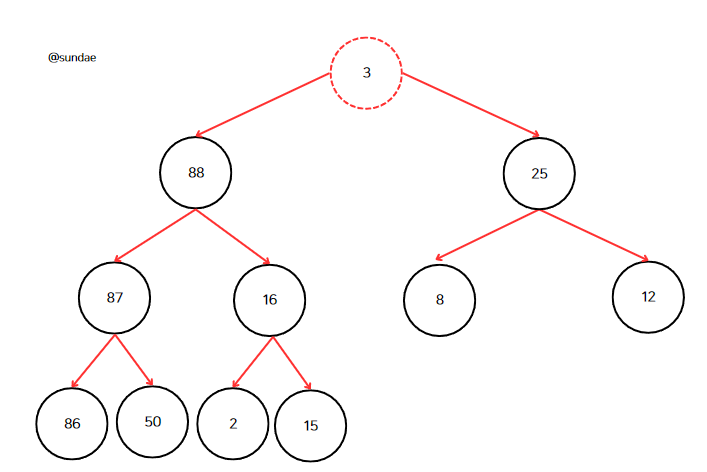
각 노드의 값이 그 노드의 모든 자손의 값보다 커야하는 힙 조건이 깨졌다. 힙 조건이 만족할 때까지 3을 아래로 트리클링해야 한다.
아래로 트리클링할 때 내려갈 수 있는 방향은 왼쪽과 오른쪽 두 방향이다. 아래로 트리클링하는 단계는 다음과 같다.
- 노드의 두 자식을 확인해 어느 쪽의 값이 큰지 본다.
- 노드가 두 자식 중 더 큰 자식 노드보다 작으면 스왑한다.
- 노드에 노드보다 큰 자식이 없을 때까지 1, 2단계를 반복한다.
루트 노드에 위치한 3의 자식 노드는 88과 25가 있다. 둘 중 88이 더 크며 이는 3보다 큰 숫자이다. 그러므로 3과 88을 바꾼다.
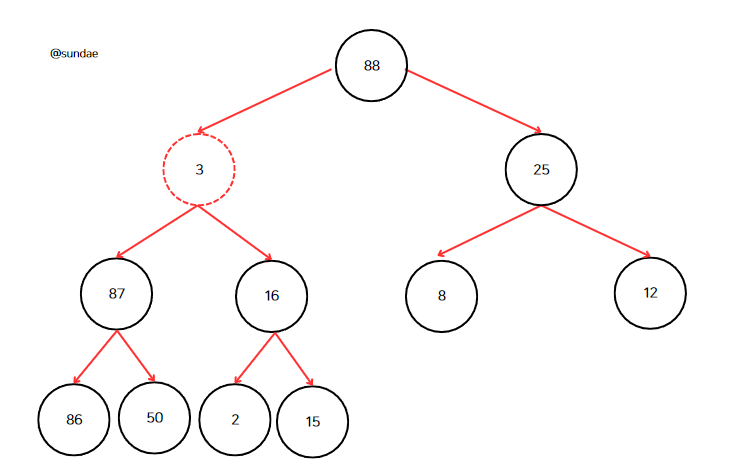
다시 1단계를 반복한다. 87과 16 중 더 큰 숫자는 87이다. 그러므로 3과 87을 바꾼다.
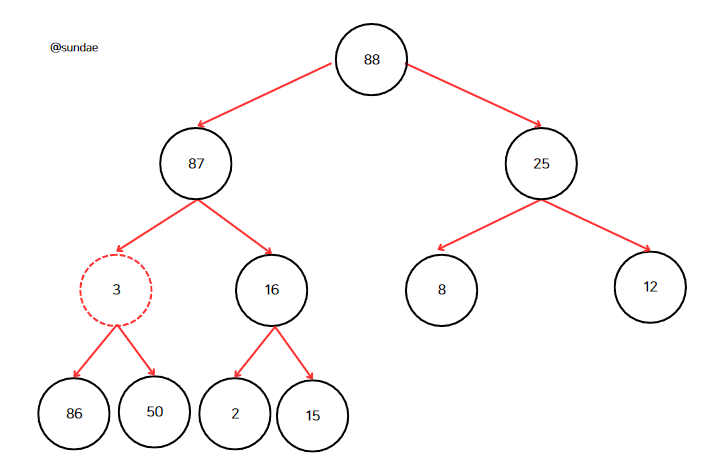
다시 반복하면 86과 50 중 더 큰 노드는 86이므로 3과 바꾼다.
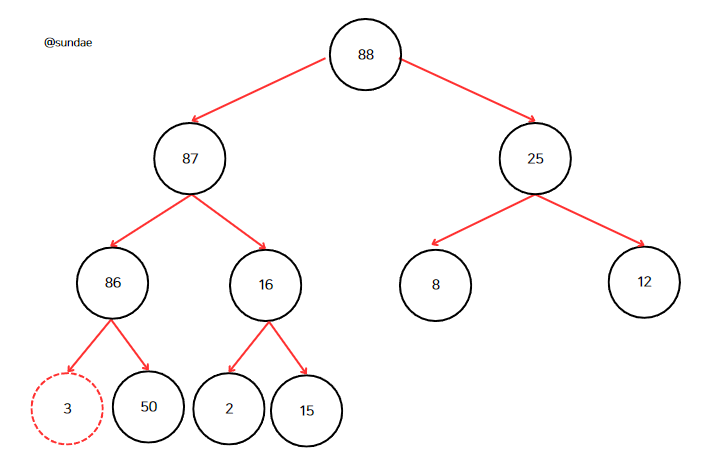
3 노드에 자식이 없으며, 힙 조건을 만족하므로 삭제가 끝났다.
여담으로 아래로 트리클링하는 단계 중 2단계는 '노드가 두 자식 중 더 큰 자식 노드보다 작으면 스왑한다'이다.
만약 큰 자식 노드와 바꾸는 것이 아닌 작은 노드와 바꾸면 어떻게 될까? 3이 루트 노드에 위치했을 때 더 큰 노드인 88이 아닌 25와 바꾸면 아래 이미지와 같이 바로 힙 조건이 깨지므로 큰 자식과 바꿔야한다.
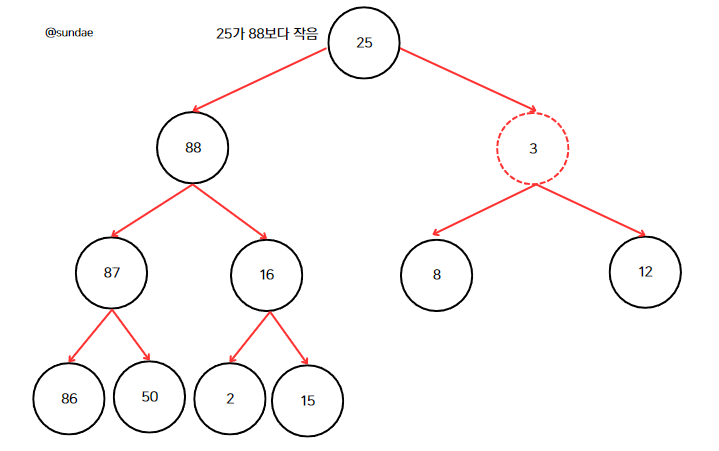
삽입과 마찬가지로 루트부터 log(N)개 레벨을 거쳐 노드를 아래로 트리클링해야 하므로 시간 복잡도가 O(logN)이다.
이진 힙 - 삭제 코드 구현
다음은 삭제 메서드이다. 아래로 트리클링하는 단계에 대한 알고리즘은 hasGreaterChild() , calculateLargerChildIndex() 두 개의 보조 메서드로 나눴다. hasGreaterChild() 메서드는 1단계(노드의 두 자식을 확인해 어느 쪽의 값이 큰지 봄)에 대한 로직을 수행한다. calculateLargerChildIndex() 메서드는 둘 중 큰 노드의 인덱스를 반환한다.
CusHeap 클래스에 추가했다.
/*
* 힙 삭제 메서드
* */
public void delete(){
// 힙에서는 루트 노드만 삭제하므로
// 배열에서 마지막 노드를 팝해 루트 노드로 넣는다.
data.set( 0, data.remove( data.size()-1 ) );
// "트리클 노드"의 현재 인덱스를 기록한다.
int tricleNodeIndex = 0;
// 다음 루프는 "아래로 트리클링"하는 알고리즘을 수행한다.
// 트리클 노드에 자기보다 큰 자식이 있으면 루프를 실행한다.
while( hasGreaterChild(tricleNodeIndex) ){
int largerChildIndex = calculateLargerChildIndex( tricleNodeIndex );
// 트리클 노드와 더 큰 자식을 스왑한다.
T temp = data.get(largerChildIndex);
data.set( largerChildIndex, data.get(tricleNodeIndex) );
data.set( tricleNodeIndex, temp );
// 트리클 노드의 새 인덱스를 업데이트한다.
tricleNodeIndex = largerChildIndex;
}
}
/*
* 자신보다 더 큰 자식을 찾는 메서드
* */
public boolean hasGreaterChild( int index ){
// index에 있는 노드에 왼쪽 자식이나 오른쪽 자식이 있는지
// 어느 한 자식이라도 index에 있는 노드보다 큰지 확인한다.
return ((data.get(leftChildIndex(index)) != null) && (data.get(leftChildIndex(index)).compareTo(data.get(index)) > 0)) ||
((data.get(rightChildIndex(index)) != null) && (data.get(rightChildIndex(index)).compareTo(data.get(index)) > 0));
}
/*
* 더 큰 자식의 인덱스를 반환하는 메서드
* */
public int calculateLargerChildIndex( int index ){
// 오른쪽 자식이 없으면
if ( data.get( rightChildIndex(index) ) == null ){
// 왼쪽 자식의 인덱스를 반환한다.
return leftChildIndex(index);
}
// 오른쪽 자식의 값이 왼쪽 자식의 값보다 크면
if( data.get( rightChildIndex(index) ).compareTo( data.get( leftChildIndex(index)) ) > 0 ){
// 오른쪽 자식 인덱스 반환
return rightChildIndex(index);
}
// 왼쪽 자식의 값이 오른쪽 자식의 값보다 크거나 같으면
else
// 왼쪽 자식의 인덱스 반환
return leftChildIndex(index);
}
힙의 효율성
이제 힙을 구현해봤으니, 우선순위 큐를 구현할 때 일반 정렬된 배열보다 힙을 구현하는 것이 왜 더 나은 방식인지 알아보자.
아래 표는 정렬된 배열과 힙을 비교한 표이다.
| 정렬된 배열 | 힙 | |
|---|---|---|
| 삽입 | O(N) | O(logN) |
| 삭제 | O(1) | O(logN) |
정렬된 배열은 삽입이 힙보다 느리지만 삭제가 O(1)로 힙과 비교했을 때 매우 빠르다. O(1)이 매우 빠르긴 하지만 O(logN)도 매우 빠른 축에 속한다. 이에 반해 O(N)은 느린 편이다. 만약 때때로 엄청나게 빠르지만, 느릴 때도 있는 자료 구조와 일관되게 빠른 자료구조 중 어떤 것을 사용하는 것이 좋을까? 후자가 좋을 것이다.
느낀점
트리 자료 구조를 배열로 충분히 구현할 수 있음을 느꼈다..!
처음 마지막 노드 문제를 보고 어떻게 문제를 해결할 수 있을까? 생각하다 정답을 보니, 자료 구조를 배열로 바꿔 구현하면 인덱스에 바로 접근할 수 있으니 놀랍도록 쉬운 문제로 바뀌는게 눈에 보인다.....
이진 힙을 배열뿐만아니라 트리, 연결 리스트로 구현할 수 있다고 들었다. 트리나 연결리스트에서 마지막 노드 자리를 어떻게 찾는지 궁금해진다... 빠른 시일 내에 찾아봐야겠다.
