
트라이
우리가 사용하는 스마트폰의 자동 완성같은 기능이 어떻게 동작하는지 예상해보자. 아마 전체 단어 사전에 접근할 것이다.
영단어를 전부 배열에 저장했다고 생각해보자. 그리고 "al"로 시작하는 단어를 찾으려한다. 만약, 알파벳 순으로 정렬되지 않은 배열이라면 단어를 찾기 위해 배열 내 모든 단어를 검색해야하므로 O(N)가 걸린다.
이번엔 알파벳 순으로 정렬된 배열에 영단어를 전부 저장했다고 생각해보자. 이때는 이진 검색을 사용할 수 있으므로 O(logN) 안에 "al"로 시작하는 단어를 찾을 수 있다.
O(logN)도 빠르지만 트라이 자료구조를 사용하면 훨씬 더 빨라질 수 있다.
트라이(trie) 자료구조는 자동 완성 같은 텍스트 기반 기능에 뛰어난 성능을 보인다.
트라이가 어떻게 동작하는지 한 번 살펴보자.
트라이 노드
트라이도 대부분의 트리와 같이 다른 노드를 가리키는 노드들의 리스트이다.
다만, 이진 트리처럼 자식 노드에 제한이 있는 트리와는 달리 트라이는 자식 노드 개수에 제한이 없다.
트라이를 구현하는 방법은 다양하지만 본 게시글의 구현에서는 트라이 노드마다 해시 맵을 포함한다. 또한, 해시 맵에서 key는 알파벳이고 값은 트라이의 다른 노드이다.
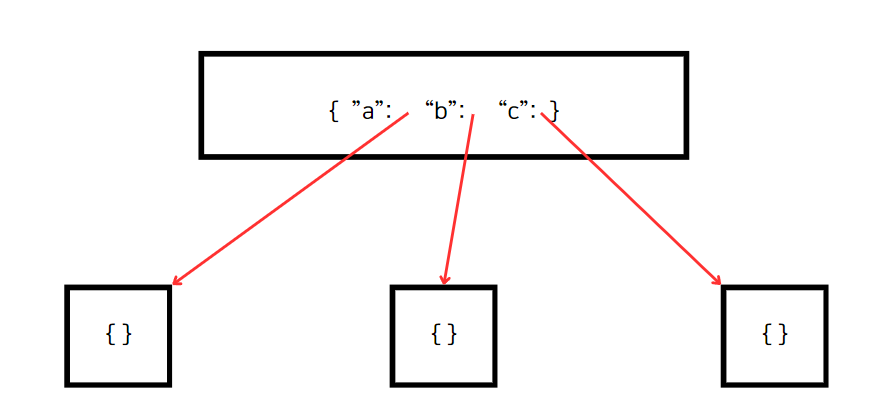
위 이미지는 루트(root) 노드에 대해 표현한 것이다. 루트 노드는 키가 "a" "b" "c"인 해시 맵을 갖고 있다. 값(value)은 해당 노드의 자식 트라이 노드다.
자식 노드도 마찬가지로 그 다음 자식 노드를 가리키는 해시 맵을 포함한다.
먼저 트라이 노드 클래스를 구현해보면 다음과 같다.
트라이 노드 클래스 만들기
public class TrieNode {
private Map<Character, TrieNode> children;
public TrieNode(){ children = new HashMap<>(); }
public Map<Character, TrieNode> getChildren(){return children;}
}위 코드에도 마찬가지로 트라이 노드는 해시 맵만을 갖고 있다. 다시 상기시키면, key는 알파벳으로 이루어지며 value는 다른 TrieNode 객체이다.
트라이 클래스
public class Trie {
// TrieNode 타입
private TrieNode root;
// 생성자, root 노드에 새 TrieNode 인스턴스
public Trie(){ root = new TrieNode(); }
public TrieNode getRoot(){ return root; }
} 위와 같이 루트 노드를 추적하는 Trie 클래스도 별도로 필요하다. 여러 연산 메서드를 Trie 클래스에 추가하며 Trie 자료구조를 알아가보자.
단어 저장
다음 "ace", "bad", "cat" 이 세 단어를 어떻게 트라이에 저장하는지 보자.
트라이는 각 단어의 각 문자를 트라이 노드로 바꿔 저장한다. 즉, "ace"라는 단어를 "a", "c", "e" 문자로 바꿔 세 개의 트라이 노드에 저장한다.
그렇게 만든 세 개의 트라이 노드를 노드들의 값에 저장하여 서로 링크 시킨다. "a"는 "c"의 부모 트라이 노드이며, "c"는 "e"의 부모 트라이 노드이다.
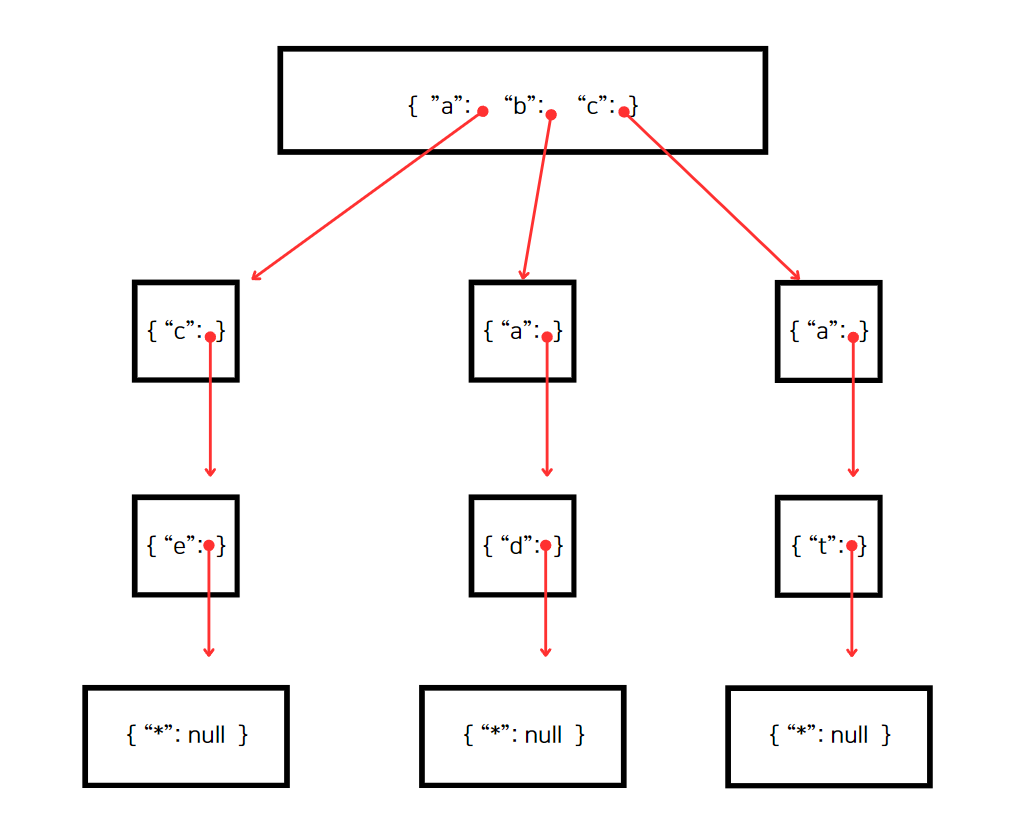
위 이미지를 보면 "a" "c" "e" 를 세 개의 트라이 노드에 저장해서 각 value에 자식 트라이 노드가 있다는 것을 알 수 있다.
또한, 위 이미지에 단어 "act"를 추가적으로 저장할 때는 어떻게 할 수 있을까?
"a" "c"는 이미 존재하는 key이므로 "t"를 key로 갖는 새로운 노드를 추가한다.
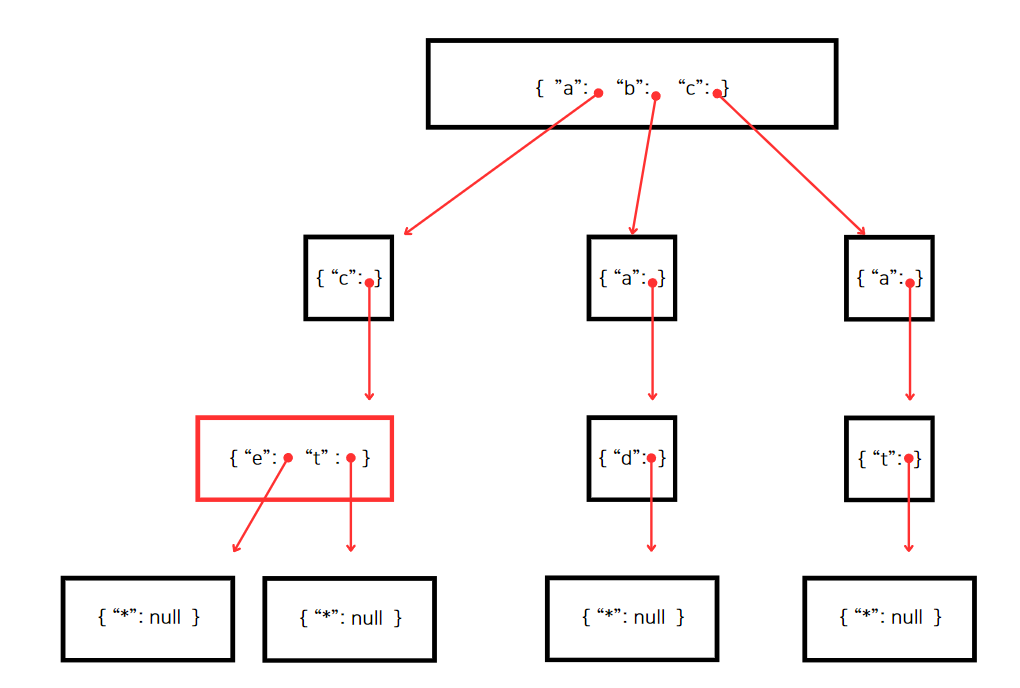
이제 "ace"와 "act"는 둘 다 트라이 내에서 유효한 단어가 됐다.
단어의 끝을 알리는 key
그런데, 이미지 가장 아래 존재하는 마지막 노드는 뭘까? key가 "*"이며 value는 null을 갖고 있다.
"*"은 단어의 끝을 나타내는 중요한 요소이다. 다음 예제로 이해해보자.
트라이에 "bat"과 "batter"를 저장해보자. 단어에서 유추할 수 있는 부분은 우선 "b" "a" "t"는 서로 곂친다는 것이다.
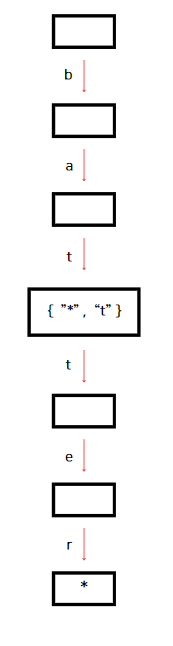
중간의 노드에서 "*"은 key이고 "t"가 value이다. 이때, 알아야할 점은 "*"로 접근한 value인 "t"는 새로운 트라이 노드라는 점이다. "*"은 "bat"단어가 끝났다는 것을 알려주고 "*"로 접근한 "t" 노드를 통해 다음 단어인 batter로 이어갈 수 있게 해준다. 즉, "bat" 자체는 하나의 단어임과 동시에 "batter"의 접두사임을 알려준다.
트라이의 검색
검색은 트라이에 어떤 문자열이 있는지 알아내는 것이다.
검색 알고리즘은 다음과 같은 단계를 수행한다.
-
currentNode라는 변수를 만든다. 알고리즘이 시작할 때 이 변수는 루트(root) 노드를 가리킨다.
-
검색 문자열의 각 문자를 순회한다.
-
검색 문자열의 각 문자를 가리키며 currentNode에 그 문자를 키로 갖는 자식이 있는지 본다.
-
자식이 없으면 검색 문자열이 트라이 내에 없다는 뜻이므로 null을 반환한다.
-
currentNode에 현재 문자를 키로 갖는 자식이 있다면 currentNode 변수는 그 자식 노드를 가리킨다. 다시 2단계로 돌아가 반복한다.
-
검색 문자열을 끝까지 순회했다면 검색 문자열을 찾았다는 뜻이다.
위 단계를 직접 해보기 위해 트라이에서 "cat"을 검색해보자.
먼저 currentNode 변수에 루트 노드를 할당한다. 그리고 아래 이미지처럼 첫 번째 문자 'c'를 가리킨다.
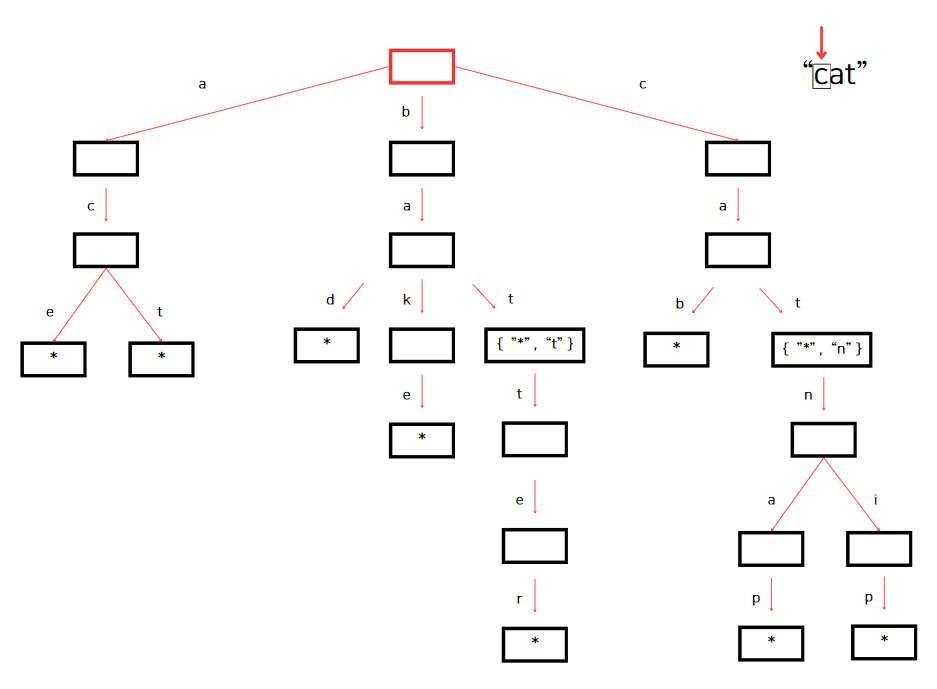
루트 노드에 키가 'c'인 자식이 있다. currentNode를 해당 자식 노드를 가리킨다.
그리고 이어서 다음 문자인 'a'를 가리키고 currentNode에 'a'를 key로 갖는 자식 노드가 있으니 currentNode는 해당 노드를 가리킨다. 이후, currentNode에서 't'를 key로 갖는 자식이 있는지 확인한다.
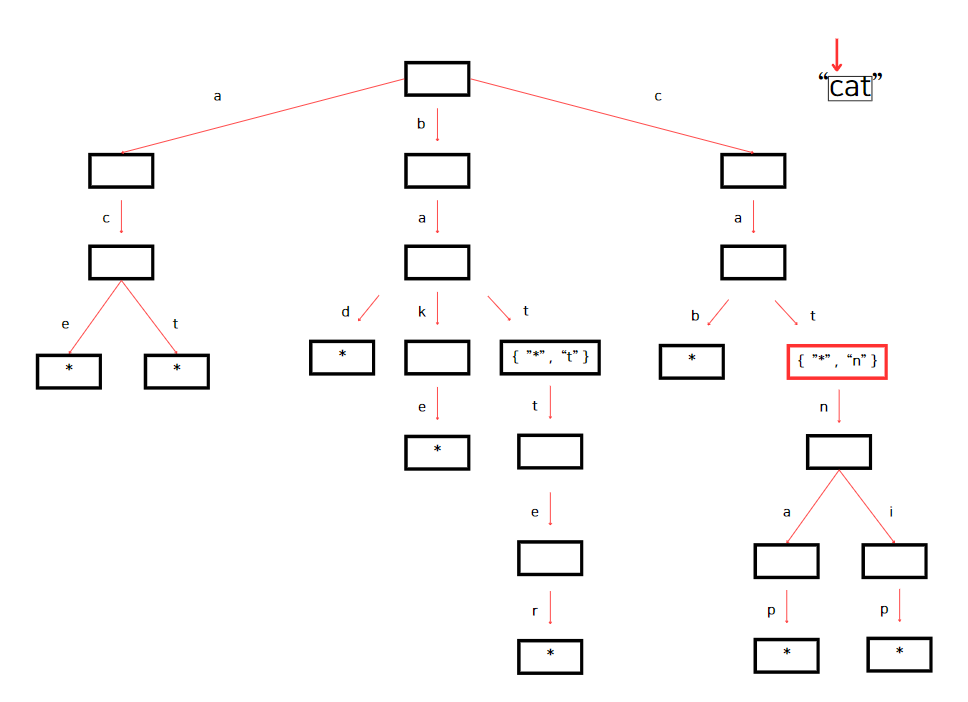
currentNode에 "t"를 key로 갖는 자식이 있으므로 검색 문자열 끝까지 도달했다. 트라이에서 "cat"을 찾은 것이다.
트라이 - 검색 코드 구현
다음은 Java로 구현한 검색 메서드이다. 위에서 만든 Trie 클래스에 search 메서드를 추가했다.
public class Trie {
private TrieNode root;
public Trie(){ root = new TrieNode(); }
public TrieNode getRoot(){return root;}
/*
* 검색 메서드
* */
public TrieNode search( String word ){
TrieNode currentNode = this.root;
for(char c : word.toCharArray()) {
// 현재 노드에 현재 문자를 키로 하는 자식이 있으면
if (currentNode.getChildren().containsKey(c)) {
// 자식 노드를 따라간다.
currentNode = currentNode.getChildren().get(c);
}
else
// 현재 노드의 자식 중에 현재 문자가 없으면
// 검색하려는 단어가 트라이에 없는 것이다.
return null;
}
return currentNode;
}
}return 타입을 boolean으로 하지않고 현재 노드로 반환하는 이유는 이후의 기능과 연계하기 위해서이다.
트라이 검색의 효율성
처음에 말했듯이 트라이 자료구조는 텍스트 기반 기능에 뛰어난 성능을 보인다고 했었다.
위의 검색 알고리즘은 입력 값으로 주어진 검색 문자열의 각 문자를 순회한다. 그러면서 각 노드의 해시 맵을 사용해 한 단계로 자식 노드를 찾는다.
해시 테이블로 자식 노드에 접근하는 단계 수는 1단계이므로 검색 알고리즘에 걸리는 단계 수는 검색 문자열의 문자 수 만큼 걸린다.
이는 정렬된 배열이나 이진 트리의 이진 검색이 O(logN)이 걸리는 것에 비견하면 훨씬 빠르다.
이를 빅 오로 나타내면 O(K)로 표현할 수 있다. 흔히 N을 사용하여 표기하지만 N은 보통 자료 구조 내 데이터 양을 뜻하므로 많은 교과서에서 표기하는 K를 사용한다.
트라이의 삽입
트라이에 새 단어를 삽입하는 과정은 검색과 비슷하며 다음 단계를 따른다.
-
currentNode 변수를 만든다. 알고리즘이 시작할 때 이 변수는 루트(root) 노드를 가리킨다.
-
검색 문자열의 각 문자를 순회한다.
-
검색 문자열의 각 문자를 순회하며 currentNode에 그 문자를 키로 갖는 자식이 있는지 확인한다.
-
자식이 있다면 currentNode는 그 자식 노드를 가리키고 다시 2단계부터 반복한다.
-
currentNode에 검색 문자열의 현재 문자와 일치하는 자식 노드가 없으면 자식 노드를 생성하고 currentNode를 생성한 자식노드를 가리킨다. 그리고 다시 2단계부터 반복한다.
-
마지막 문자까지 삽입했으면 마지막 노드에 "*"를 key로 갖는 자식을 추가한다.
위 단계를 토대로 "can"을 삽입해보자.
검색 구현 때 처럼, 먼저 currentNode 변수에 루트 노드를 할당한다. 그리고 아래 이미지처럼 첫 번째 문자 'c'를 가리킨다.
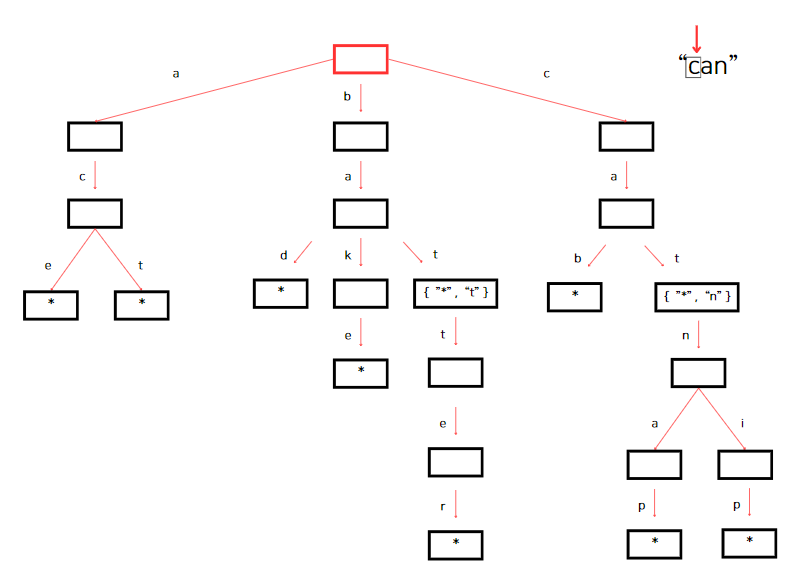
루트(root) 노드에 키가 'c'인 자식이 있으니 currnetNode는 그 자식 노드를 가리킨다. 이어서 currentNode에 'a'를 key로 갖는 자식 노드가 있는지 확인한다. 'a'를 key로 갖는 자식노드가 있으므로 currentNode는 해당 노드를 가리킨다. 그 후, currentNode에서 다음 검색 문자인 'n'을 key로 갖는 노드를 찾는다.
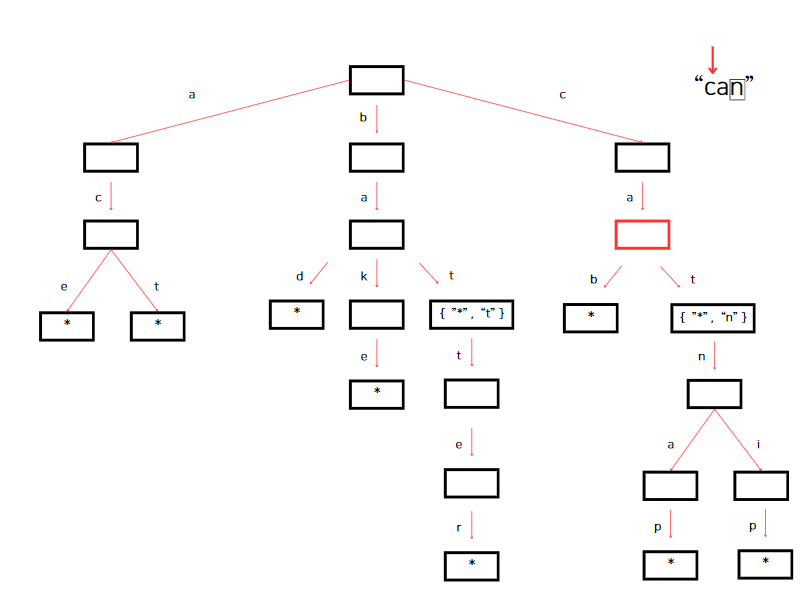
currentNode에 'n'이 없다. 'n'을 key로 갖는 자식 노드를 생성해야한다.
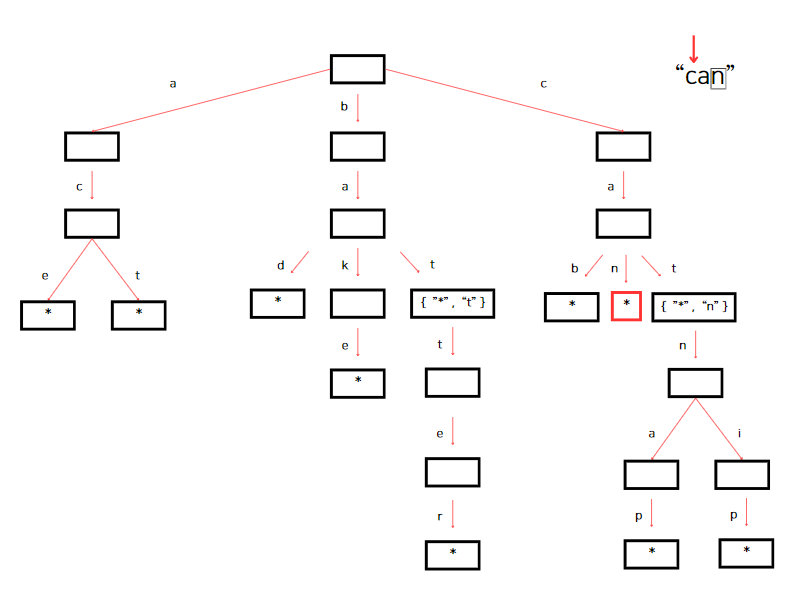
트라이에 "can"을 성공적으로 삽입했다. "*"를 넣어 단어가 끝임을 알려준다.
트라이 - 삽입 코드 구현
다음은 Java로 구현한 삽입 메서드이다. 위에서 만든 Trie 클래스에 insert 메서드를 추가했다. 위에서 구현했던 검색 메서드와 거의 유사하다.
public class Trie {
private TrieNode root;
public Trie(){ root = new TrieNode(); }
public TrieNode getRoot(){return root;}
/*
* 삽입 메서드
* */
public void insert( String word ){
TrieNode currentNode = this.root;
for( char c : word.toCharArray() ){
// 현재 노드에 현재 문자를 키로 하는 자식이 있으면
if(currentNode.getChildren().containsKey(c)){
// 자식 노드를 따라간다
currentNode = currentNode.getChildren().get(c);
}
else {
// 현재 노드의 자식 중에 현재 문자가 없으면
// 그 문자를 새 자식 노드로 추가한다.
currentNode.getChildren().put(c, new TrieNode());
// 새로 추가한 노드를 따라간다.
currentNode = currentNode.getChildren().get(c);
}
}
// 단어 전체를 트라이에 삽입했으면
// 마지막으로 *를 추가한다.
currentNode.getChildren().put('*', null);
}
}트라이 삽입의 효율성
트라이에서 삽입 연산의 효율성은 검색과 똑같이 O(K)가 걸린다. 마지막에 "*"을 추가하는 것까지 합하면 K + 1이지만 빅오 표기법에선 상수는 무시한다.
자동 완성 기능
위에서 학습한 검색 연산과 삽입 연산을 토대로 간단한 자동 완성 기능을 만들어보자.
자동 완성 기능을 완성하기 위해 Trie 클래스에 두 개의 메서드를 추가할 것이다.
단어 수집 메서드
단어 수집 메서드는 트라이 내의 모든 단어를 배열로 반환하는 메서드이다. 모든 단어를 배열로 반환하는 일은 드물지만 단어 수집 메서드는 특정 노드를 인수로 받아 해당 노드부터 시작되는 단어를 수집한다. '특정 노드를 인수로 받는다' 라는 부분은 검색 메서드와 연계 된다. 검색 메서드에서 반환 값은 TrieNode니 말이다. 이 다음 메서드에서 연계 되는 부분을 알 수 있을 것이다.
다음은 Java로 구현한 단어 수집 메서드이다. 위에서 만든 Trie 클래스에 collectAllWords(단어 수집) 메서드를 추가했다.
(재귀를 많이 사용하는 메서드라 한번에 이해하기 어려울 수도 있다.)
public class Trie {
private TrieNode root;
public Trie(){ root = new TrieNode(); }
public TrieNode getRoot(){return root;}
/*
* 단어 수집 메서드
* */
public List<String> collectAllWords(TrieNode node, String word, ArrayList<String> words){
/*
* 메서드는 인수 세 개를 받는다.
* 첫 번째 인수인 node는 그 자손들에게서 단어를 수집할 노드이다.
* 두 번째 인수인 word는 빈 문자열로 시작하고
* 트라이를 이동하면서 문자가 추가된다.
* 세 번째 인수인 words는 빈 배열로 시작하고
* 함수가 끝날 때는 트라이 내 모든 단어를 포함한다.
*
* 현재 노드는 첫 번째 인자로 전달받은 node다.
* 아무것도 받지 않았으면 루트 노드다.
* */
TrieNode currentNode = node == null ? this.root : node;
// 매개 값이 null이라면 빈 문자열로 초기화
if (word == null) word = "";
// 현재 노드의 모든 자식을 순회한다.
for(Map.Entry<Character, TrieNode> entry : currentNode.getChildren().entrySet()){
// 현재 키가 *이면 완전한 단어 끝에 도달했다는 뜻이므로
// 이 단어를 words 리스트에 추가.
if( entry.getKey() == '*' ) words.add(word);
else
// 아직 단어 중간이면
// 그 자식 노드에 대해 이 함수를 재귀적으로 호출한다.
collectAllWords(entry.getValue(), word + entry.getKey() , words );
}
return words;
}
}자동 완성 메서드
자동 완성 메서드는 위에서 구현한 검색 메서드와 단어 수집 메서드를 연계하여 구현된다. 똑같이 Java로 구현했으며 Trie 클래스에 추가했다.
public class Trie {
private TrieNode root;
public Trie(){ root = new TrieNode(); }
public TrieNode getRoot(){return root;}
/*
* 자동 완성 메서드
* */
public List<String> autocomplete( String prefix ){
TrieNode currentNode = search(prefix);
return currentNode == null ? null
: collectAllWords( currentNode, prefix, new ArrayList<>() );
}위의 세 줄이 끝이다. 미리 구현해둔 검색 메서드인 search 메서드로 일치하는 노드를 반환하여 currentNode에 저장한다. 그 후, 단어 수집 메서드의 인자 값으로 넘겨주고, 리스트를 반환받는다.
나가는 글
트라이(Trie) 자료구조에 대해 학습하고 정리하였다.
트라이 자료구조는 자동 완성에 특화 됐다고 볼 수 있다. 자동 완성 기능을 정렬된 배열이나 이진 트리로 구현 했을 때 삽입과 검색 연산에 못해도 O(logN) 단계가 걸릴 것이다.
하지만 트라이를 사용하니 어떠한가. 딱 문자열의 길이만큼만 걸린다. 분명 연산 속도 차이가 엄청날 것이다.
자료 구조와 알고리즘을 학습하는 이유는 적재적소에 알맞은 자료구조를 적용하는 것이다.
처음 자료구조 학습의 이유를 들었을 때는 "음.. 그렇겠다." 하며 대충 수긍하고 넘어갔었다. 그런데, 트라이 자료구조를 포함하여 여러 자료 구조를 학습하고 나서 그 중요성이 직접적으로 와닿았다. 자동 완성 기능은 실제로 여러 소프트웨어에서 필수적인 기능이니 말이다.
앞으로도 내가 구현해야할 수많은 기능에 있어 적합한 자료구조를 아느냐 모르느냐에 따라 기능의 완성도는 천차만별일 것이다. 자료구조는 무척 중요하다.
