
이 농어는 몇kg일까?
이번에는, 해당 농어의 크기를 통해 농어의 무게를 맞추는 프로그램이 필요하다.
이를 위해서 회귀 알고리즘(Regression)을 사용 할 것이다.
산점도 출력하기
# 56마리의 농어의 길이와 무게
perch_length = np.array([8.4, 13.7, ...])
perch_weight = np.array([5.9, 32.0, ...])
import matplotlib.pyplot as plt
plt.scatter(perch_length,perch_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()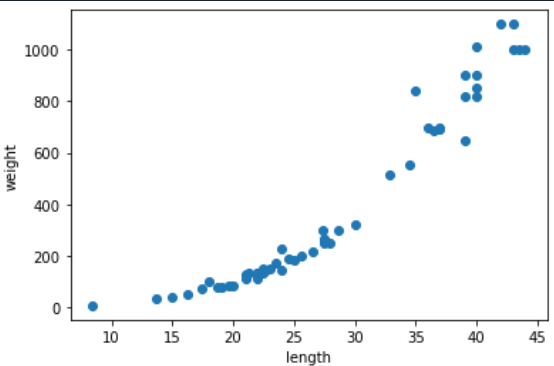
reshape를 통해 2차원 배열로 수정
train_input = train_input.reshape(-1,1)
test_input = test_input.reshape(-1,1)
print(train_input, test_input)결정계수
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor();
knr.fit(train_input, train_target)
print(knr.score(test_input, test_target) # 0.9928...이제 데이터를 학습(fit) 시킨 후, score를 출력하면 ㄷ음과 같은 값이 나온다.
위 값을 결정계수라고 한다.
오차값
from sklearn.metrics import mean_absolute_error
test_prediction = knr.predict(test_input)
mae = mean_absolute_error(test_target, test_prediction)
print(mae) # 19.15... 위 코드를 통해 대략 19정도의 오차값을 가짐을 알 수 있다.
과대적합, 과소적합?
이제 훈련세트를 통해 결정계수를 확인해보자
knr.fit(train_input, train_target)
print(n, knr.score(test_input,test_target)) # 0.96...위 훈련 세트와 값이 다름을 알 수 있다.
과대적합
위처럼
훈련 세트의 점수만 높은 경우를과대적합이라고 한다.과소적합
반대로
테스트 세트의 점수가 높거나, 둘 다 지나치게 낮은 경우를과소적합이라고 한다.
위 경우를 피하기 위해서는
- 더 많은 샘플
- 더 복잡한 모델
이 필요하다. 더 복잡한 모델을 만들기 위해서는 neighbors 숫자를 조정하면 된다.
knr.fit(train_input, train_target)
print(n, knr.score(test_input,test_target)) # 0.9746...
prtin(knr.score(train_input,train_target)) # 0.9804...결론
print(knr.predict([[25]]))