
얘는 빙어일까 도미일까

이전 모델에서 25센치, 150g 물고기가 들어왔다.
직관적으로 표를 보면 주황색 점은 도미라고 판단할것이다.
하지만...
print(kn.predict([[25,150]]))위 코드를 실행시키면 0(빙어)를 출력한다. 어째서일까?
이웃 확인하기
import matplotlib.pyplot as plt
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(25, 150)
plt.scatter(train_input[indexes,0], train_input[indexes,1])
plt.xlabel('length')
plt.ylabel('weight')
plt.show()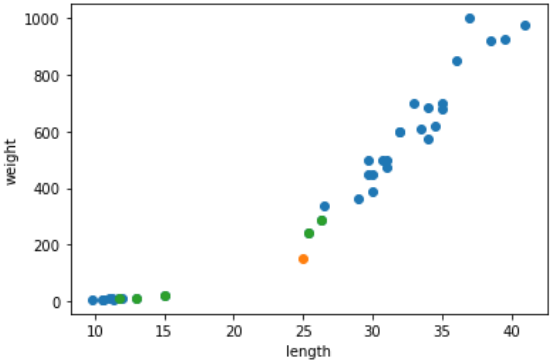
이전 장에서 우리는 KNN이 이웃을 확인하여 이를 검사한다고 학습했다. 이웃을 출력해보면 위와같이 빙어그룹에서 3개, 도미그룹에서 2개가 선택됨을 알 수 있다.
이처럼 무게와 길이는 각 특성의 스케일이 다르다고 이야기한다.
그렇기에 우리는 데이터 전처리작업이 필요하게 된다.
전처리 작업
가장 대표적인 전처리 작업으로는 표준점수가 있다.

x가 원수치, σ는 표준편차, μ는 평균이며, 이를 구하기 위한 메소드는
mean = np.mean(train_input, axis=0) # 표준편차
std = np.std(train_inpt, axis=0) # 평균이며,
train_scaled = (train_input - mean) / std를 통해 전처리 작업을 할 수 있다.
mean = np.mean(train_input,axis=0)
std = np.std(train_input,axis=0)
# 전처리 후, 전처리한 데이터를 fit
train_scaled = (train_input - mean) / st d
kn.fit(train_scaled, train_target)
scaled_new = ([25,150] - mean) / std
print(kn.predict([scaled_new])) # 1.0 출력, 도미
