기존 프로그래밍에서...
# 35마리의 도미의 길이
bream_length = [25.4, 26.3, ...]
# 35마리의 도미의 무게
bream_weight = [242.0, 290.0, 340.0, ...]
# 14마리의 빙어의 길이
smelt_length = [9.8, 10.5, 10.6, ...]
# 14마리의 빙어의 길이
smelt_weight = [6.7, 7.5, 7.0, ...]물고기의 몸무게와 길이 정보를 통해, 우리는 이 물고기가 빙어인지, 도미인지 확인하고자 하는 프로그램이 필요하다.
기존 코드를 짤때,
도미는 30cm보다 크다
라는 정보와 함께
fish_length = 31
if fish_length > 30:
print("도미입니다")와 같은 코드를 짤 수 있을것이다.
하지만 실제로도 위와 같은 코드로 도미를 구분 할 수 없다.
그렇기에 머신러닝을 통해 위와같은 문제를 해결하고자 한다.
데이터 준비
import matplotlib.pyplot as plt
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.xlabel('length')
plt.ylabel('weight')
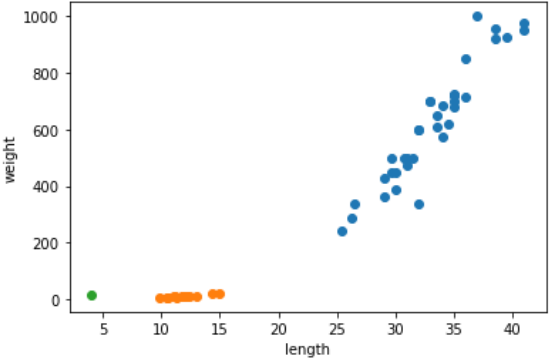
plt.show()
위처럼 파란 점에는 도미, 주황 점에는 빙어가 분포함을 볼 수 있다.
머신러닝 생성
우리 위 데이터를 머신러닝에 사용하기 위해 2차원 배열의 형태로 저장할것이다.
| 분류(0:빙어,1:도미) | 길이 | 무게 |
|---|---|---|
| 0 | 9.8 | 6.7 |
| 0 | 11.8 | 7.5 |
| ... | ... | ... |
| 1 | 25.4 | 242 |
| ... | ... | ... |
length = bream_length + smelt_length1
weight = bream_weight + smelt_weight
# 특성을 저장
fish_data = [[l,w] for l,w in zip(length, weight)]
# 타겟을 저장
fish_target = [1]*35 + [0]*14여기서 길이와 무게를 특성이라고 한다
K-Nearest Neighbor
위 예시에서, 특정 점에 가장 가까운 n개의 샘플을 이웃(neighbor)라고 설정한다.
이때 더 가까운 분류로 값을 판단한다
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(fish_data, fish_target) # 훈련
print(kn.score(fish_data, fish_target)) # 1.0
print(kn.predict([[4,17]]))# 0. 빙어라는 뜻