오늘은 RDB 및 Document, Graph 데이터베이스 모델과 각 모델의 특징을 다룬다.
관계형 모델과 문서모델의 개념
- 관계형 모델(RDBMS)
- SQL은 1970년에 탄생
- 데이터는 테이블이라 불리는 관계로 구성되고 각 관계는 순서 없는 튜플(tuple)(SQL에서의 row)의 모음이다.
- 주로 비즈니스 데이터 처리에서 사용되며, 트랜잭션처리와 일괄처리를 수행한다.
- NoSQL(Document, Graph)
- 탄생 배경
- 대규모 데이터셋이나 높은 쓰기 처리량 달성, 뛰어난 확장성이 필요
- 무료 오픈소스에 대한 선호도 확산
- RDB에서 지원하지 않는 특수 질의 동작
- 동적이고 표현력이 풍부한 데이터 모델에 대한 바람
- 탄생 배경
데이터 모델은 상황에 맞게 선택해서 사용하는 것이 바람직하며, 관계형 데이터베이스와 비관계형 데이터스토어를 함께 사용할 수 있다.(이를 다중 저장소 지속성이라 함)
- 객체 관계형 불일치
- 관계형 테이블에 데이터를 저장하려면 애플리케이션 코드와 데이터베이스 모델 객체 사이에 전환계층이 필요함. 이러한 두 모델 사이의 분리를 임피던스 불일치라고 부름
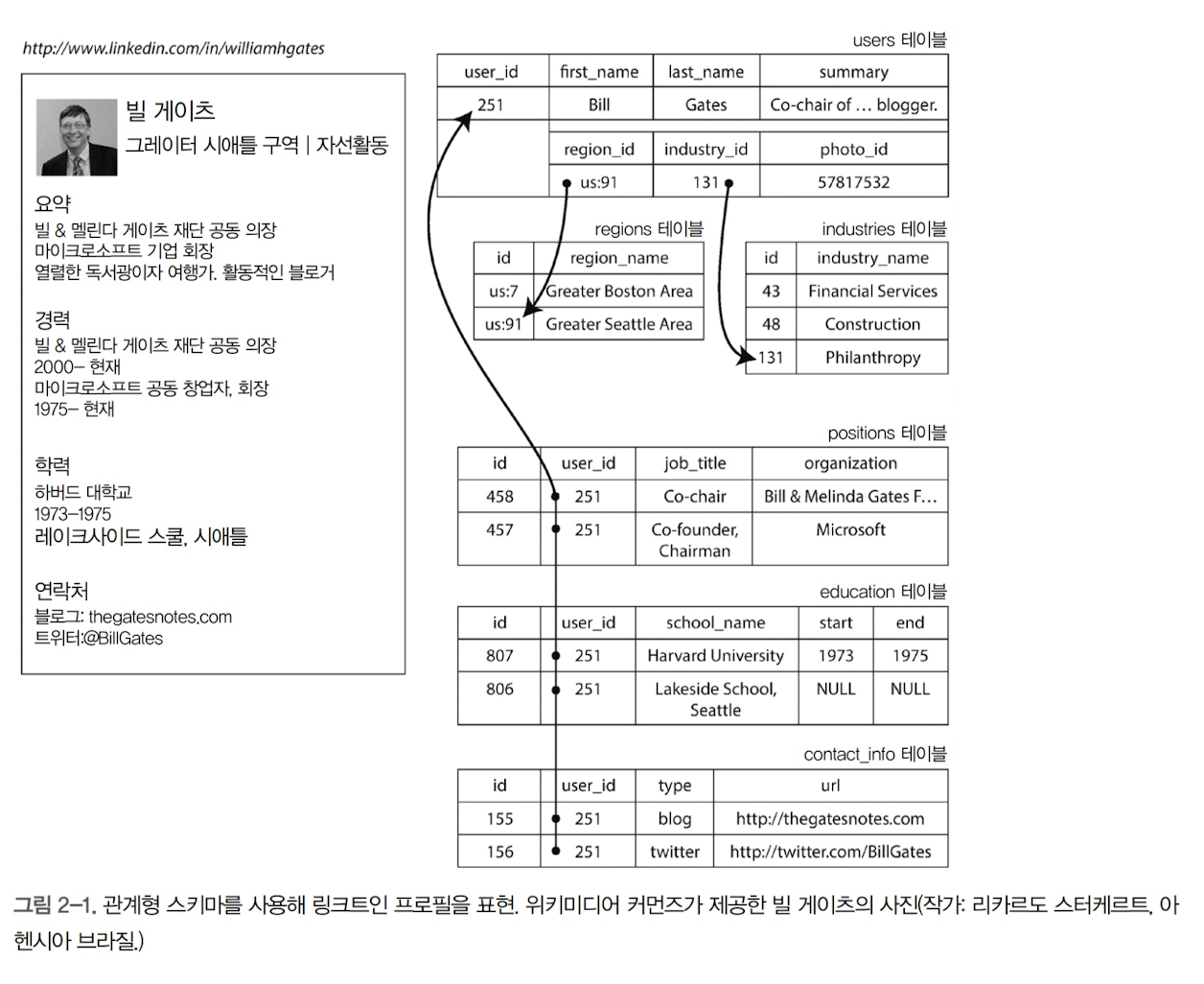
- 위 그림과 같은 일대다(one-to-many)관계를 표현하기 위한 방법은 다음과 같다.
- SQL 정규화 표현을 사용한다. 직위, 학력, 연락처를 개별 테이블에 넣고 외래키로 users 테이블을 참조한다.
- 구조화된 데이터타입, XML, JSON 타입의 칼럼을 사용한다.
- Text칼럼에 JSON이나 XML문서로 저장한 다음, 애플리케이션이 구조와 내용을 해석한다.
- 위 그림에서도 알 수 있듯이 관계형으로 이를 표현하려면 매우 복잡하다.
- 위 예시(이력서) 같은 데이터는 구조를 갖춘 문서라서 JSON 구조가 매우 적합하다. 몽고DB, 리싱크DB 데이터베이스는 JSON 데이터 모델을 지원한다.
// JSON으로 표현한 이력서
{
"user_id": 251,
"first_name": "Bill",
"last_name": "Gates",
"summary": "Co-chair of the Bill & Melinda Gates... Active blogger.",
"region_id": "us:91",
"industry_id": 131,
"photo_url": "/p/7/000/253/05b/308dd6e.jpg",
"positions": [
{"job_title": "Co-chair", "organization": "Bill & Melinda Gates Foundation"},
{"job_title": "Co-founder, Chairman", "organization": "Microsoft"}
],
"education": [
{"school_name": "Harvard University", "start": 1973, "end": 1975},
{"school_name": "Lakeside School, Seattle", "start": null, "end": null}
],
"contact_info": {
"blog": "http://thegatesnotes.com",
"twitter": "http://twitter.com/BillGates"
}
}- JSON 표현의 특징
- SQL의 다중 테이블 스키마보다 더 나은 지역성(locality)을 갖는다.
- 관계형에서 프로필을 다져오려면 다중 질의(user_id로 각 테이블에 질의)를 수행하거나 난잡한 다중 조인을 수행해야 함
- 반면, JSON은 한 곳에 모든 정보가 있어 질의 하나로도 충분함
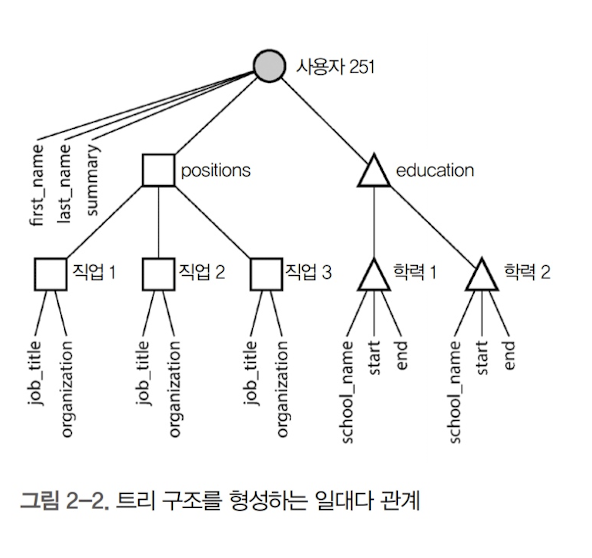
- 이러한 일대다 관계는 의미상 트리 구조와 같다.
- 테이블에서 id를 쓰는 이유?
- 예제에서 region_id와 industry_id는 평문이 아닌 id로 주어짐. id를 쓰는 것의 장점은 다음과 같음
- 프로필 간 일관된 스타일과 철자
- 모호함 회피(동일 이름의 도시가 여러 개일 경우)
- 갱신의 편의성
- 더 나은 검색. 예를 들어 워싱턴 주에 있는 자선가를 검색하려 할 때 지역 목록에 시애틀이 워싱턴에 있다는 사실을 부호화(“그레이터 시애틀 구역” 문자열로는 “워싱턴”을 식별하지 못함)할 수 있기 때문에 원하는 프로필을 찾을 수 있다.
- 텍스트를 직접 저장하면 그것을 저장하는 모든 레코드에서 정보를 중복해서 저장하게 됨
- 또한, id는 아무런 의미가 없기 때문에 변경할 필요가 없음. 데이터가 변동되더라도 id는 그대로 쓸 수 있음
- 즉, 쓰기 오버헤드(모든 정보를 변경해야하는) 불일치(일부만 변경되는)의 위험을 제거
- 이런 중복을 제거하는 것이 데이터베이스 정규화에 놓인 핵심 개념
- 예제에서 region_id와 industry_id는 평문이 아닌 id로 주어짐. id를 쓰는 것의 장점은 다음과 같음
다대일, 일대다, 다대다 관계
다대일(many-to-one)과 일대다(one-to-many) 관계
- 중복된 데이터를 정규화하려면 보통 다대일(many-to-one) 관계가 필요함
- 하지만 문서 모델은 이를 표현하는 데 적합하지 않음(tree를 생각하면 쉬움)
- 반면 일대다 트리 구조를 지원하는 데 있어서는 문서 모델이 적합함
- 그러면, 이력서(예시)는 문서 모델로 표현하면 되지 않나?
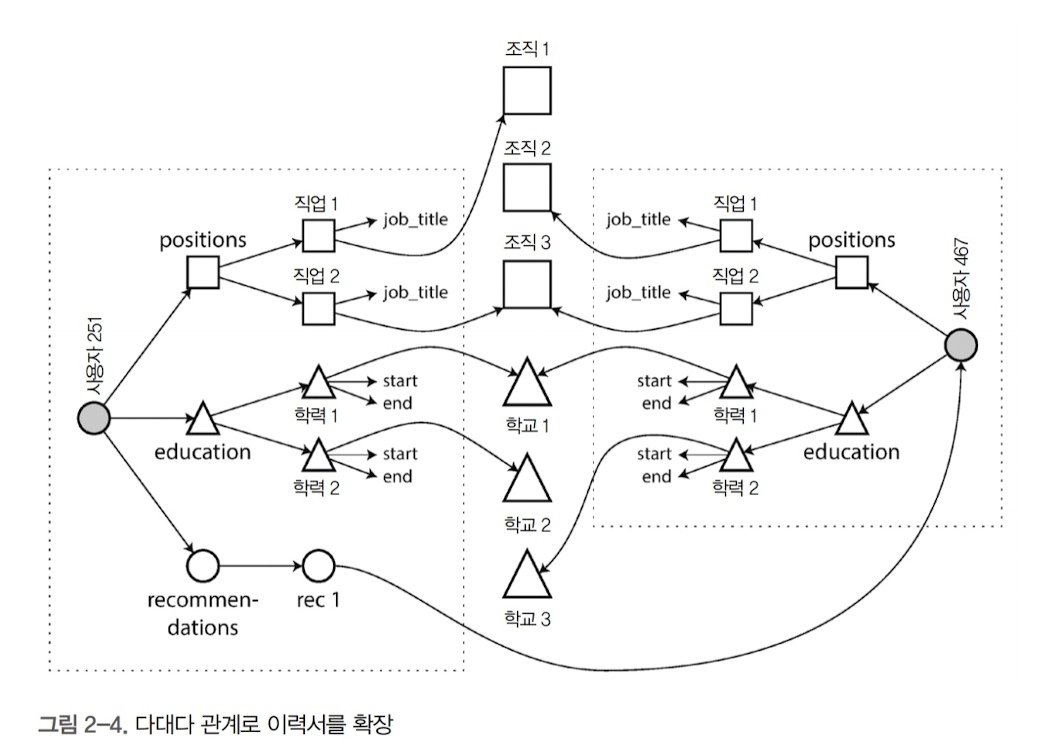
- 새로운 기능이 추가된다고 생각해보자
- 이력서에 쓰인 회사(organization)와 학교(school_name)를 링크로해서 해당 조직의 정보를 띄우는 기능
- 추천서 기능. 추천서에는 추천인의 이름과 사진이 보여지고, 추천인이 사진을 변경하면 추천서에도 반영되어야 함
- 다대다(many-to-many) 관계
- 위의 신규기능을 추가한 도식은 다음과 같으며, 이는 다대다 관계이다.
- 데이터는 문서로 묶을 수 있지만, 조직, 학교, 기타 사용자는 참조로 표현해야 하고 질의할 때는 조인이 필요하다.
그래프형 데이터 모델
-
이처럼 다대다 관계의 데이터가 일반적이라면, 그래프형 데이터 모델을 고려해볼 수 있음
-
그래프는 두 유형의 객체로 이루어짐. 노드와 간선 (자료구조의 그것과 같다.)
-
일반적인 예는 다음과 같음
- 소셜 그래프 : 노드는 사람이고 간선은 서로 알고 있음을 나타냄
- 웹 그래프 : 노드는 웹 페이지고 간선은 다른 페이지에 대한 링크를 나타냄
- 도로 네트워크 : 노드는 교차로이고 간선은 교차로 간 도로를 나타냄
-
그래프는 속성 그래프 모델과 트리플 저장소 모델을 살펴본다.
-
속성 그래프(Neo4j, Titan, InfiniteGraph 등)
-
속성그래프의 노드는 다음과 같은 요소로 구성된다.
- 고유한 식별자
- 유출 간선 집합
- 유입 간선 집합
- 속성 컬렉션(key-value 쌍)
-
간선은 다음과 같은 요소로 구성된다.
- 고유 식별자
- 간선이 시작하는 노드(꼬리 노드)
- 간선이 끝나는 노드(머리 노드)
- 두 노드 간 관계를 설명하는 레이블
- 속성 컬렉션(key-value 쌍)
-
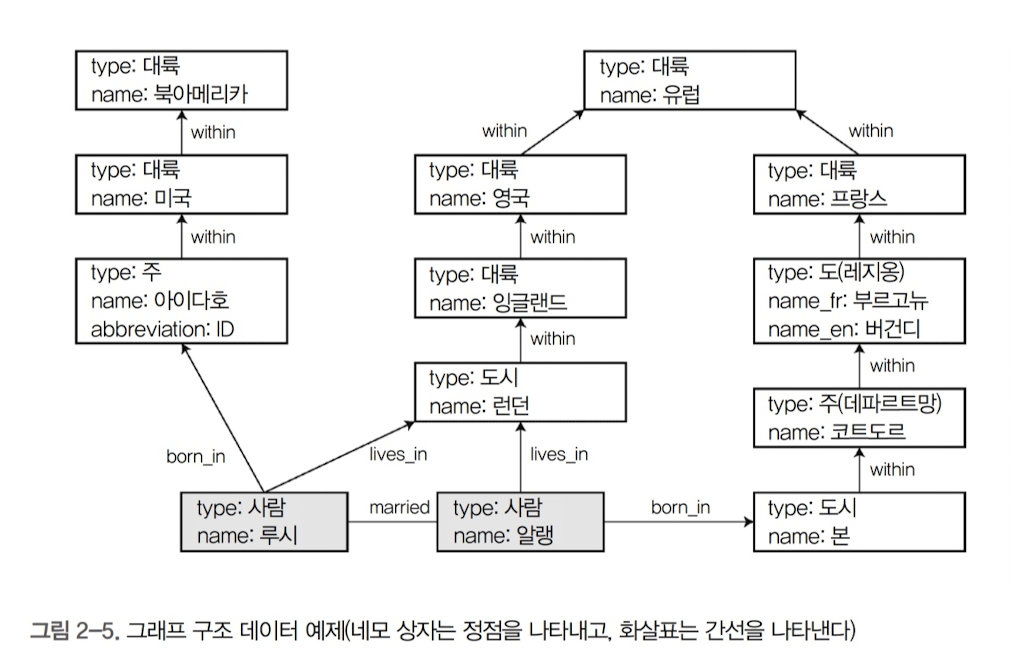
속성 그래프의 간단한 예시(사이퍼 질의)
-
CREATE
(NAmerica:Location {name:'North America', type:'continent'}),
(USA:Location {name:'United States', type:'country' }),
(Idaho:Location {name:'Idaho', type:'state' }),
(Lucy:Person {name:'Lucy' }),
(Idaho) -[:WITHIN]-> (USA) -[:WITHIN]-> (NAmerica),
(Lucy) -[:BORN_IN]-> (Idaho)- 속성 그래프의 특징
- 노드는 다른 노드와 간선으로 연결된다. 특정 유형과 관련 여부를 제한하는 스키마는 없다.
- 노드가 주어지면 노드의 유입과 유출 간선을 효율적으로 찾을 수 있고 그래프를 순회할 수 있다. 즉 일련의 노드를 따라 앞뒤 방향으로 순회한다.
- 다른 유형의 관계에 서로 다른 레이블을 사용하면 단일 그래프에 다른 유형의 정보를 저장하면서도 데이터 모델을 깔끔하게 유지할 수 있다.
- 관계형 스키마와의 비교
- 그래프 데이터는 데이터 모델링을 위한 많은 유연성과 확장성을 제공한다.
- 국가마다 지역 구조가 다르다면?
- 그래프를 확장해야 한다면?
- 이를 RDB에서 표현하는 것은 까다로운 일이다.
- 트리플 저장소(Datomic, Allegrograph 등)
- 트리플 저장소는 속성 그래프 모델과 거의 동등하다.
- 모든 정보를 주어, 서술어, 목적어처럼 세 부분 구문(three-part statement)형식으로 저장한다.
- 데이터의 일부를 터틀(Turtle)형식의 트리플로 표현하면, 다음과 같다.
@prefix : <urn:example:>.
_:lucy a :Person.
_:lucy :name "Lucy".
_:lucy :bornIn _:idaho.
_:idaho a :Location.
_:idaho :name "Idaho".
_:idaho :type "state".
_:idaho :within _:usa.
_:usa a :Location.
_:usa :name "United States".
_:usa :type "country".
_:usa :within _:namerica.
_:namerica a :Location.
_:namerica :name "North America".
_:namerica :type "continent".- 즉, 속성그래프가 노드 간 관계를 특정 레이블을 통해 설명한다면, 트리플 저장소는 주어, 서술어, 목적어로 설명하는 차이가 있다.
요약
- 오늘은 세 가지 데이터 모델에 대해서 알아봤다.
당연한 말이지만, 데이터 형식에 따라 알맞는 데이터 모델을 선택하는 것이 합리적일 것이다.
(관계형 데이터 모델로도 다대다 관계를 표현할 수는 있다. 다만, 엄청나게 복잡해질 뿐.)
이 책에선 세 가지 형태로 데이터 형식을 분류하고, 그에 알맞는 데이터 모델의 특징을 설명한다.
- 데이터가 주로 다대일(many-to-one)관계라면 중복된 데이터를 정규화할 수 있는 관계형 데이터 모델을 선택하는 것을 고려할 수 있다.
- 데이터가 주로 일대다(one-to-many)(tree 구조)관계라면 하나의 문서로 데이터를 관리할 수 있는 문서 데이터 모델을 선택하는 것을 고려할 수 있다.
- 데이터가 주로 다대다(many-to-many)관계라면 유연성과 확장성에 강점이 있는 그래프형 데이터 모델을 선택하는 것을 고려할 수 있다.
