오늘은 RDB, Document, Graph 데이터 모델의 질의 언어에 대해 살펴본다.
각 질의 언어의 비교
-
네트워크 모델
-
1970년대 가장 많이 사용한 데이터베이스는 IBM의 정보관리스템(IMS)였다.
-
IMS의 설계는 계층 모델(JSON과 비슷)에 기반했는데, 이런 특징때문에 IMS는 문서 데이터 모델과 마찬가지로 일대다 관계에서는 잘 작동했지만, 다대다 관계에서는 한계점을 지녔다.
-
이러한 한계를 극복하고자 나온 데이터 모델이 관계형 모델과 네트워크 모델이었다.
-
네트워크 모델은 계층 모델을 일반화한다.
-
계층 모델에서 모든 레코드는 정확히 하나의 부모가 있다.
-
네트워크 모델에서는 다중 부모가 있을 수 있다.(다대다 관계를 모델링하기 위해서)
-
그렇기 때문에, 레코드에 접근하는 유일한 방법은 최상위 레코드에서부터 연속된 연결 경로를 따르는 방법뿐이다. 이를 접근 경로라고 한다.
-
만약 레코드가 다중 부모를 가진다면, 애플리케이션 코드는 다양한 관계를 모두 추적해야한다는 것을 의미한다.
-
애플리케이션 코드는 복잡해지고, 유연하지 못한 문제가 생긴다.
-
즉, 새로운 접근 경로로 변경하기 위해서는 데이터베이스 질의 코드를 살펴봐야 하고 새로운 접근 경로를 다루기 위해 재작성해야한다는 것을 의미한다. 이를 수동 접근 경로 선택이라 한다.
-
-
관계형 모델
-
관계형 모델은 네트워크 모델에 비해 단순하다.
-
관계(테이블)은 단순히 튜플(row)의 컬렉션이 전부이며, 얽히고설킨 중접 경로와 복잡한 접근 경로가 없다.
-
일부 칼럼을 키로 지정해 칼럼과 일치하는 특정 로우를 읽을 수 있으며, 다른 테이블과의 외래키 관계에 대해 신경쓰지 않고 임의 테이블에 새 로우를 삽입할 수 있다.
-
질의 최적화기(query optimizer)
- 관계형 데이터베이스에서 질의 최적화기는 질의의 어느 부분을 어떤 순서로 실행할지 결정하고 사용할 색인을 자동으로 결정한다.
- 이 선택은 "접근 경로" 다. 하지만, 개발자가 수동으로 조작하는 것이 아니라, 질의 최적화기가 자동으로 만든다는 점에서 네트워크 모델에서의 접근 경로 조작과는 확연한 차이가 생긴다.
-
-
문서 데이터 모델
-
문서 데이터 모델은 네트워크 모델의 과실을 범하지 않기 위해 일대다 관계를 별도 테이블이 아닌 상위 레코드 내에 중첩된 레코드를 저장한다.
-
다대일, 다대다 관계를 표현할 때는 관계형 데이터베이스와 크게 다르지 않다. 관계형 모델에서 외래 키라부르는 것을 문서 모델에서 문서 참조(document reference)라고 부를 뿐이다.
-
스키마 유연성
-
문서 모델은 종종 스키마리스(schemaless)로 불리지만, 오해의 소지가 있다.
-
데이터를 읽는 코드는 보통 구조의 유형을 어느 정도 가정한다. 즉, 암묵적인 스키마가 존재하지만, 데이터베이스가 이를 강제하지는 않는다.
-
조금 더 정확한 용어로 말하자면 읽기 스키마(schema-on-read)다.
-
읽기 스키마 : 데이터 구조는 암묵적이고 데이터를 읽을 때만 해석한다.
-
쓰기 스키마 : 관계형 데이터베이스의 접근 방식, 스키마는 명시적이고 데이터 베이스는 쓰여진 모든 데이터가 스키마를 따르고 있음을 보장한다.
-
읽기 스키마는 프로그래밍 언어에서 동적 타입 확인과 유사하고, 쓰기 스키마는 정적(컴파일 타임) 타입과 유사하다.
-
이러한 차이는 데이터 타입을 변경하려 할 때 뚜렷이 나타난다.
-
예를 들어, 현재 하나의 필드에 사용자 전체 이름이 있고, 성과 이름을 분리해서 저장한다고 가정한다.
-
문서 데이터 모델의 경우 예전 문서를 읽은 경우를 처리하는 코드만 있으면된다.
-
하지만, 정적 타입의 데이터베이스 스키마에서는 보통 마이그레이션을 수행한다. 특히 mysql은 ALTER TABLE 시, 전체 테이블을 복사해 시간이 오래걸릴 수 있다.
-
not null 에 Default 값을 지정하는 경우엔 전체 행을 갱신, 최근엔 Not null 에 Default 지정시 전체행을 갱신하지 않고 Dictionary 에서만 해당 정보를 관리하는 새로운 기능이 나왔다고 함(자세히 찾아보진 않음)
-
-
// 문서 데이터 모델
if(user && user.name && !user.first_name){
user.first_name = user.name.split(" ")[0];
} -- 관계형 데이터 모델(mysql)
ALTER TABLE users ADD COLUMN first_name text;
UPDATE users SET first_name = substring_index(name, ' ', 1);선언형 질의와 명령형 질의
- SQL은 선언형 질의 언어이고, IMS는 명령형 코드를 사용해 데이터베이스에 질의한다.
- 예를 들어 명령형 코드에서 동물의 종 목록이 있을 때 목록에서 상어만 반환하는 코드는 다음과 같다.
function getSharks() {
var sharks = [];
for (var i = 0; i < animals.length; i++) {
if (animals[i].family === "Sharks") {
sharks.push(animals[i]);
}
}
return sharks;
}- 선언형 질의 언어(SQL)에서는 다음과 같다.
SELECT * FROM animals WHERE family = 'Sharks'-
명령형 언어는 특정 순서로 특정 연산을 수행하도록 컴퓨터에게 지시한다.
-
하지만 선언형 질의 언어(SQL)에서는 목표를 달성하기 위한 방법이 아니라, 알고자 하는 데이터의 패턴, 즉 결과가 충족해야하는 조건과 데이터를 어떻게 변환(ex. 정렬, 그룹화)할지를 지정하기만 하면 된다. 목표를 달성하기 위한 방법은 쿼리 최적화기가 수행한다.
-
선언형 언어는 간결하고 쉽다는 장점보다 더 큰 장점을 가지고 있는데, 이는 데이터베이스 엔진의 상세 구현이 숨겨져 있어 질의를 변경하지 않고도 데이터베이스 시스템의 성능을 향상시킬 수 있다는 점이다.
-
예를 들어 이번 절을 시작할 때 나왔던 명령형 코드에는 동물 목록이 특정 순서로 나타난다. 만약 데이터베이스 내부적으로 사용되지 않는 디스크 공간을 회수하고 싶다면 레코드를 옮겨야 할 수 있다. 하지만 그러면 동물이 나타나는 순서가 바뀔지도 모른다. 이 작업을 데이터베이스가 질의에 영향을 주지 않고 안전하게 수행할 수 있을까?
-
SQL 예제는 특정 순서를 보장하지 않으므로 순서가 바뀌어도 상관없다. 하지만 질의가 명령형 코드로 작성됐다면 데이터베이스는 코드가 순서에 의존하는지 여부를 확신할 수 없다.
-
하지만 선언형 언어는 종종 병렬 실행에 적합하다. 오늘날 CPU가 코어 수를 추가하는 방향으로 속도를 개선하는데, 명령어 코드는 특정 순서로 수행하게끔 지정하기 때문에 다중 코어나 다중 장비에서 병렬 처리가 매우 어렵다. 그에 반해 선언형 언어는 결과를 결정하기 위한 알고리즘을 지정하는 게 아니라 결과의 패턴만 지정하기 때문에 병렬 실행으로 더 빨라질 가능성이 크다.
사이퍼 질의
-
사이퍼(Cypher)는 속성 그래프를 위한 선언형 질의 언어로, 네오포제이(Neo4j) 그래프 데이터베이스용(Datahub에서 리니지 표현용으로 쓰이고 있음)으로 만들어졌다.
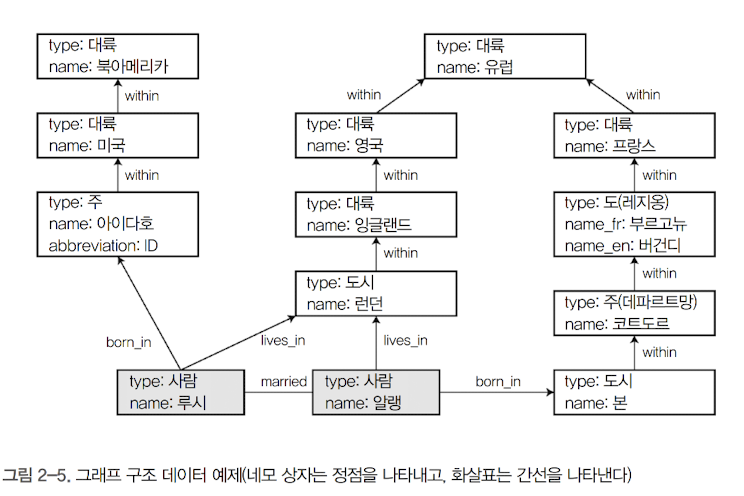
-
위 예제의 왼쪽 부분을 그래프 데이터베이스로 삽입하는 사이퍼 질의의 예시는 다음과 같다.
CREATE
(NAmerica:Location {name:'North America', type:'continent'}),
(USA:Location {name:'United States', type:'country' }),
(Idaho:Location {name:'Idaho', type:'state' }),
(Lucy:Person {name:'Lucy' }),
(Idaho) -[:WITHIN]-> (USA) -[:WITHIN]-> (NAmerica),
(Lucy) -[:BORN_IN]-> (Idaho)-
사이퍼 질의 모델에서는 노드 간 간선을 화살표 표기를 사용해 만들 수 있다. 즉, (Idaho) -[:WITHIN]-> (USA)의 경우 꼬리 노드는 Idaho, 머리 노드는 USA인 WITHIN 레이블의 간선이 된다.
-
이같은 사이퍼 질의 모델의 장점은 다대다 관계에서의 구현이다. 예를 들어 미국에서 유럽으로 이민 온 모든 사람들의 이름 찾기와 같은 질문을 떠올려보자.
MATCH
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}),
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'})
RETURN person.name-
질의는 다음과 같이 해석된다.
-
person은 BORN_IN 유출 간선을 가진다. 이 정점에서 name속성이 United States인 Location 유형의 정점에 도달할 때까지 일련의 WITHIN 유출 간선을 따라간다.
-
같은 person 정점은 LIVES_IN 유출 간선도 가진다. 이 간선을 따라가면 결국 name 속성이 Europe인 Location 유형의 정점에 도달한다.
-
각 person 정점마다 name 속성을 반환한다.
-
선언형 질의 언어는 질의를 작성할 때 이처럼 수행에 대해 자세히 지정할 필요가 없다. 질의 최적화기가 가장 효율적이라고 예측한 전략을 자동으로 선택하므로 작성자는 나머지 애플리케이션만 작성하면 된다.
사이퍼 질의를 SQL로 구현해본다면?
-
관계형 데이터베이스의 질의로 그래프 질의를 만들기 어려운 이유
-
관계형 데이터 베이스에서는 보통 질의에 필요한 조인을 미리 알고 있다.
-
그래프 질의에서는 찾고자 하는 정점을 찾기 위해 가변적인 여러 간선을 수행해야 한다. 즉, 미리 조인 수를 고정할 수 없다.
-
SQL에서 순회 경로에 대한 질의는 재귀 공통 테이블 식(resursive common table expression)을 사용한다.
-
위 예시와 같은 데이터를 찾는 과정을 SQL로 구현한다면 다음과 같다.
-
WITH RECURSIVE
-- in_usa는 미국 내 모든 지역의 정점 ID 집합이다.
in_usa(vertex_id) AS (
SELECT vertex_id FROM vertices WHERE properties->>'name' = 'United States' ➊
UNION
SELECT edges.tail_vertex FROM edges ➋
JOIN in_usa ON edges.head_vertex = in_usa.vertex_id
WHERE edges.label = 'within'
),
-- in_europe은 유럽 내 모든 지역의 정점 ID 집합이다.
in_europe(vertex_id) AS (
SELECT vertex_id FROM vertices WHERE properties->>'name' = 'Europe' ➌
UNION
SELECT edges.tail_vertex FROM edges
JOIN in_europe ON edges.head_vertex = in_europe.vertex_id
WHERE edges.label = 'within'
),
-- born_in_usa는 미국에서 태어난 모든 사람의 정점 ID 집합이다.
born_in_usa(vertex_id) AS ( ➍
SELECT edges.tail_vertex FROM edges
JOIN in_usa ON edges.head_vertex = in_usa.vertex_id
WHERE edges.label = 'born_in'
),
-- lives_in_europe은 유럽에서 태어난 모든 사람의 정점 ID 집합이다.
lives_in_europe(vertex_id) AS ( ➎
SELECT edges.tail_vertex FROM edges
JOIN in_europe ON edges.head_vertex = in_europe.vertex_id
WHERE edges.label = 'lives_in'
)
SELECT vertices.properties->>'name'
FROM vertices
-- 미국에서 태어나 유럽에서 자란 사람을 찾아 조인한다.
JOIN born_in_usa ON vertices.vertex_id = born_in_usa.vertex_id ➏
JOIN lives_in_europe ON vertices.vertex_id = lives_in_europe.vertex_id;