RDBMS
RDBMS란
-
Relational Database Management System
-
RDB를 이용하는 총체적인 시스템을 일컫는다.
-
RDB 기능 뿐만 아니라, Transaction, Stored Procedure과 같은 기능들을 제공
-
특징
-
데이터를 row와 column로 구성된 테이블로 표현
-
각 row는 구분할 수 있는 unique(primary) key(PK)를 가짐
-
row의 primary key를 이용해 다른 테이블의 row와 연결할 수 있음
- 다른 테이블에서 해당 row를 연결할 수 있는 column을 FK(Foreign Key)라 함
-
PK와 FK를 이용해 두 테이블의 관계를 일대일, 일대다로 구현할 수 있음
- 중간 테이블을 이용해 다대다를 구현할 수도 있음
-
RDBMS의 종류
-
Oracle
-
장점
- 신뢰성
- 속도
- 다양한 기능
-
다양한 RDBMS 오픈소스가 있지만, 압도적으로 많이 사용되는 RDBMS다. 이유는 장점으로 언급된 것들의 노하우들
-
거의 유일한 단점은 비싸다는 점
-
-
MySQL
-
오픈소스로 구현된 RDBMS 중에서 가장 많이 사용되는 데이터베이스
-
Oracle에 있는 SQL, 기능들을 지원하는 데 장점이 있음
-
오픈소스 중에서는 역사가 오래되고 Oracle과 유사한 부분이 많아 많은 기업들에서 사용
-
-
PostgreSQL
-
분석에 특화된 RDBMS
-
분석을 위한 편리한 기능들을 SQL에서 사용할 수 있는 점이 가장 큰 장점
-
초기에는 안정성, scale과 관련된 기능들이 부족했지만, 시간이 지나며 좋아지는 중
-
-
MariaDB
-
MySQL에서 fork되어 나온 Database
-
MySQL이 Oracle에 인수되면서, 관련 개발자들이 MySQL을 fork하고 대부분의 MySQL 기능을 호환하는 식으로 개발한 데이터베이스
-
-
Cloud Vendor Managed DBMS
-
AWS, Azure, GCP 등 클라우드 업체에서 제공하는 데이터베이스
-
초기에는 오픈소스 구현체들을 Wrapping한 제품들이었지만, 시간이 지나며 클라우드 운영상 효율이 좋은 아키텍처로 자체적으로 만들기도 함
-
Amazon Aurora DB, Azure SQL Database 등이 대표적
-
FK 제약 설정
-
참조하고 있는 테이블에서 해당 row가 없어진다면 어떻게 처리해야 할까?
-
프로그래밍 언어라면 처리하면 그만이지만, SQL에서는?
-
ON UPDATE/ON DELETE constraint는 FK로 참조되고 있는 원본 테이블에서 변경(UPDATE)/삭제(DELETE)가 일어날 때, 그것을 참조하고 있는 테이블에서 어떤 동작이 일어나도록 하는 설정
-
MySQL 기준으로 설명한다.
-
ON DELETE/UPDATE CASCADE
- 부모 테이블의 row가 지워지면, 그것을 참조하고 있는 자식 테이블의 row도 함께 지워진다/업데이트 된다.
-
ON DELETE/UPDATE SET NULL
- 부모 테이블의 row가 지워지면, 그것을 참조하고 있는 자식 테이블의 해당 row의 참조 칼럼을 null로 바꿔준다. 단, 참조 칼럼이 nullable이어야 한다.
-
ON DELETE/UPDATE RESTRICT(= NO ACTION[default])
- 다른 테이블에 참조하고 있는 곳이 있다면 부모 테이블의 row는 지울/업데이트할 수 없다.
CREATE TABLE parent (
id INT NOT NULL,
PRIMARY KEY (id)
) ENGINE=INNODB;
CREATE TABLE child (
id INT,
parent_id INT,
INDEX par_ind (parent_id),
FOREIGN KEY (parent_id)
REFERENCES parent(id)
ON DELETE CASCADE
) ENGINE=INNODB;JDBC
JDBC란
-
Java DataBase Connectivity
-
Java application이 client로서 어떻게 데이터베이스에 접근하는지 정의해놓은 표준 인터페이스
-
DB에 접속하고 데이터를 업데이트하거나 쿼리를 보내는 메소드들을 제공
-
기본적으로는 RDBMS를 상정하고 만들어짐
-
ODBC(Open Database Connectivity)란
- 프로그래밍 언어나 운영체제에 상관없이 DBMS에 독립적으로 사용할 수 있는 전송계층을 만들려는 노력으로 만들어진 ODBC Driver
JDBC 구성요소
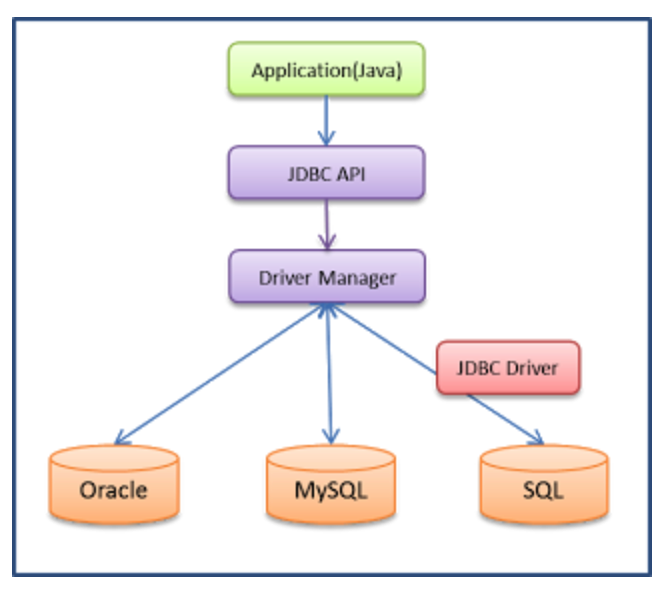
-
DriverManager → Connection → Statement → ResultSet
-
사용법은 위의 구성요소들을 차례대로 동작시키는 것
-
DriverManager
-
User와 Driver 사이의 인터페이스를 담당
-
Database와 Driver 사이의 Connection을 관리
-
Driver 등록/해제, Connection의 연결/해체
-
Connection con = DriverManager.getConnection( "jdbc:mysql://localhost:3306/{database}", "root", null);
-
Connection
-
Connection 객체 하나는 DB와 Java Client 사이의 하나의 물리적인 연결을 의미
-
DB입장에서는 하나의 Session
-
Session은 변경 사항의 묶음을 관리하는 단위
-
해당 연결에서 사용할 Statement, PreparedStatement, DatabaseMetaData 객체를 얻어올 수 있다.
-
주요 메소드
-
Statement createStatement() : Statement 객체 생성
-
PreparedStatement prepareStatement(String sql) : Parameterized된 sql과 함께 PreparedStatement 객체를 생성
-
DatabaseMetaData getMetaData() : DatabaseMetaData 객체를 제공
-
setAutoCommit(boolean status) : autocommit을 사용할지 여부. 기본값은 true
-
commit() : 지금까지 Connection(Session)에서 수행한 변경사항들을 DB 원본 테이블에 반영
-
rollback : 지금까지 Connection(Session)에서 수행한 변경사항들을 DB 원본 테이블에 반영하지 않고, Connection의 상태도 초기화
-
close() : 연결을 즉시 끊음
-
-
-
Statement
-
Statement를 이용해 실제 수행할 쿼리 작성. 수행 결과는 ResultSet 객체로 받아옴. 정적인 쿼리를 작성
-
주요 메소드
- ResultSet executeQuery(String sql) : sql을 수행하고 ResultSet을 받아옴. 결과가 있는 쿼리이므로 SELECT문을 쓸 때 사용
- int executeUpdate(String sql) : INSERT, UPDATE, DELETE 등 결과를 받아오지 않는 sql작성. return 값은 변경사항이 적용된 row의 수.
- boolean execute(String sql) : 여러개의 결과를 얻는 sql 수행. 결과가 ResultSet이면 true 반환. getResultSet()을 호출해 결과값을 얻을 수 있음. 결과가 ResultSet이 아니면, false를 리턴. getUpdateCount()를 호출해 결과를 얻음
- int[] executeBatch() : addBatch(String sql)로 쌓인 sql을 배치로 수행.
- void addBatch(String sql) : 현재 Statement 객체에 배치로 실행할 sql 명령어를 추가
-
-
ResultSet
-
ResultSet은 결과를 cursor를 이용해 다룰 수 있도록 하는 객체
-
쿼리의 결과를 테이블 형태로 가정하고, 특정 row를 가리키는 cursor를 가짐
-
배열 등으로 한번에 리턴하지 않는 이유는 메모리 제약 등의 이유
-
주요 메소드
-
public boolean next()
-
public boolean previous()
-
public boolean first()
-
public boolean last()
-
public boolean absolute(int row) : ResultSet의 특정 row로 cursor 이동
-
public boolean relative(int row) : 현재 위치로부터 정해진 순번의 row로 커서 이동
-
public int getInt(int columnIndex) : 현재 cursor가 가리키는 데이터 행의 column index에 해당하는 칼럼의 값을 int로 가져옴
-
public int getInt(String columnName) : 현재 cursor가 가리키는 데이터 행의 column name에 해당하는 칼럼의 값을 int로 가져옴
-
public String getString(int columnIndex)
-
public String getString(String columnName)
-
public Blob getBlob(int columnIndex) : 대용량 이진수 객체(이미지, 동영상 등)
-
public Blob getBlob(String columnName)
-
public Clob getClob(int columnIndex) : 대용량 문자 객체
-
public Clob getClob(String columnName)
-
-
-
예제 JDBC로 Hive, Trino 연결하기
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class JdbcConnectionExample {
public static void main(String[] args) throws SQLException, ClassNotFoundException {
// Properties
// Connect to trino
String url = "jdbc:trino://{{192.168.56.110:8990}}/hive/{{database}}";
// Connect to hive
//String url = "jdbc:{{hive2://192.168.56.110}}:10000/{{database}}";
Properties properties = new Properties();
properties.setProperty("user", "user");
properties.setProperty("SSL", "false");
Connection connection = DriverManager.getConnection(url, properties);
Statement statement = null; // or PrepareStatement
statement = connection.createStatement();
//Select hive table
String sql = "select title, url from test_dw";
ResultSet resultSet = statement.executeQuery(sql);
while (resultSet.next()) {
//Retrieve by column name
String title_col = resultSet.getString("title");
String url_col = resultSet.getString("url");
//Display values
System.out.println("title=" + title_col);
System.out.println("url=" + url_col);
}
//Clean-up environment
resultSet.close();
statement.close();
connection.close();
}
}-
PreparedStatement
-
Statement의 subinterface
-
parameterized query를 사용할 때 사용
-
여러 종류의 쿼리를 사용하지만, 컴파일은 한번만 하면 되므로 성능상 이점이 존재
-
쿼리에서 parameterized하고 싶은 부분을 ?로 작성
-
주요 메소드(Statement 메소드 + 아래 함수)
- public void setInt(int paramIndex, int value) : paramIndex 자리에 있는 파라미터를 int값으로 세팅
- public void setString(int paramIndex, String value) : paramIndex 자리에 있는 파라미터를 String값으로 세팅
- public void setFloat(int paramIndex, float value) : paramIndex 자리에 있는 파라미터를 float값으로 세팅
- public void setDouble(int paramIndex, double value) : paramIndex 자리에 있는 파라미터를 double값으로 세팅
-
