Superset을 Production에 적용하기 위한 분석, 설계를 진행하다 Superset Cache 처리을 위해 Redis에 대해 학습해야 할 일이 생겼다. 여기서는 간단히 Redis에 대해 알아본 내용을 정리한다.
Redis란
-
Redis는 데이터베이스, 캐시, 메시지 브로커 및 스트리밍 엔진으로 사용되는 비관계형 인메모리 데이터 구조(key-value) 저장소
-
디스크 기반 색인으로 구현하기 어려운 데이터 모델을 제공(String, hash, list, set, sorted set 이외에도 hyperloglogs, geospatial index, stream을 지원)
Redis 활용 사례
- Twitter의 Timeline Cache
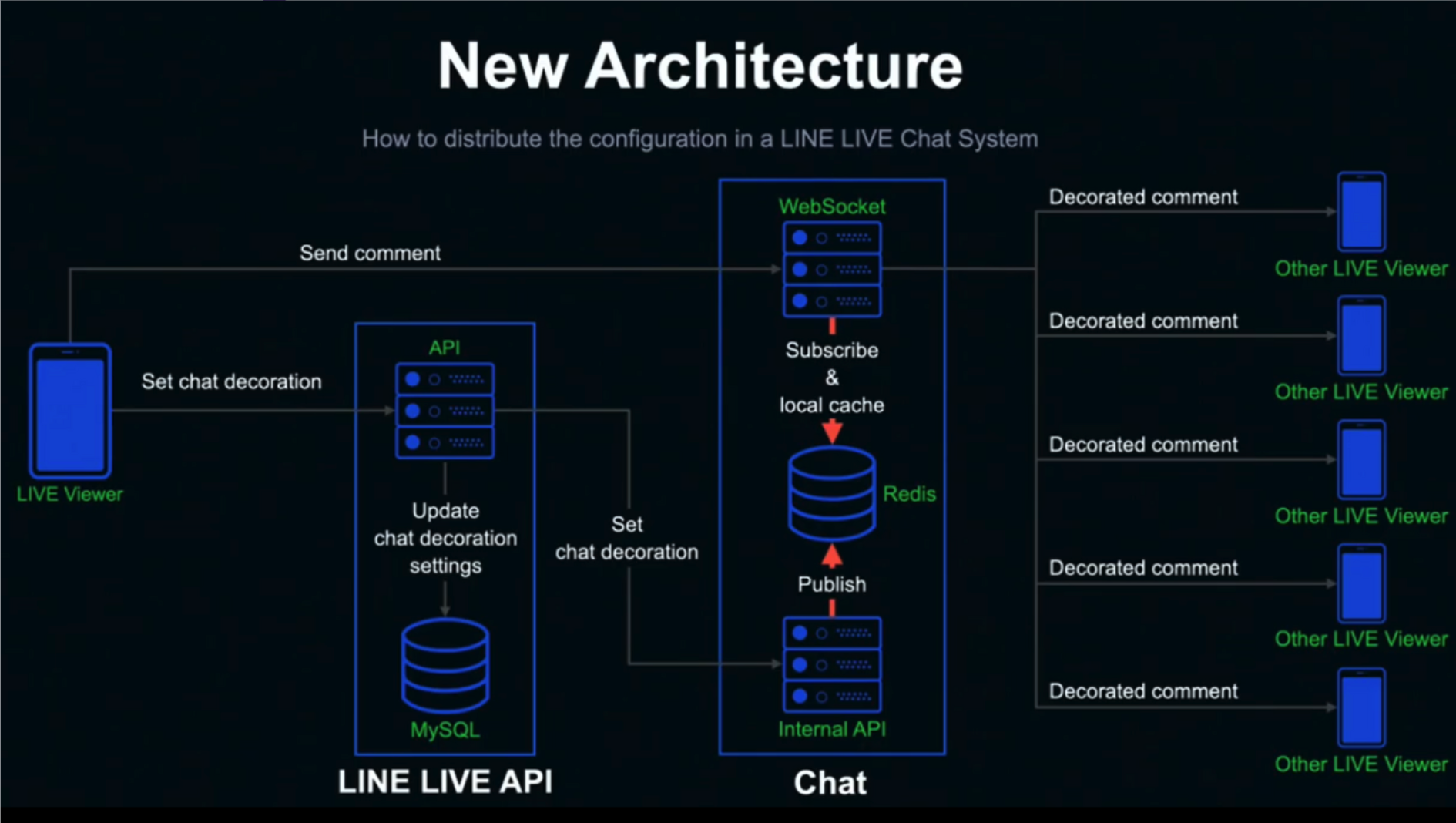
- LINE Live Chat Pub-Sub(Mysql to Redis)
Redis의 데이터 구조(Collections)

-
일반적으로 String(key - value 형태로 저장)을 사용하며, Score 집계 같은 처리를 하기 위해 Sorted Set을 사용하기도 함
-
즉, 여러 방식의 데이터 처리를 위해 유연하게 Collection을 선택할 수 있다는 점이 Redis의 장점
Redis의 영속성(Persistence) 보장
-
Redis는 RDB, AOF라는 방식으로 데이터 영속성을 보장
-
이 점이 Memcached와 같은 인메모리 캐시와의 차이이며, 이 때문에 관점에 따라 Redis를 NoSQL로 분류하기도 함
-
RDB
-
특정 시점에 Redis 데이터의 스냅샷 파일(*.rdb)를 생성하는 방식
-
이 방식은 Redis 읽기/쓰기에 영향을 미치지 않음
-
RDB는 자식 프로세스를 생성하여 수행하기 때문
-
이 때 메모리 사용량이 2배가 되므로 사용시 주의해야 함
-
데이터가 너무 큰 경우 자식 프로세스를 fork하는 과정에서 서비스 중단이 발생할 수 있음
-
-
-
AOF(Append Only File)
-
각 쓰기 명령을 로그로 간주하고 log파일에 저장. Redis가 다시 시작되면 AOF 로그에 저장된 명령을 재실행하여 데이터를 복구하는 방식
-
이 방식은 RDB보다 데이터 손실을 더 적게 가져갈 수 있음
-
백그라운드 스레드를 통해 1초마다 fsync 명령을 수행하기 때문(조절 가능)
-
하지만, AOF 로그 파일이 일반적으로 RDB 파일보다 큼
-
RDB, AOF가 모두 존재한다면, AOF를 사용하여 데이터 복구(더 최신일 가능성이 높기 때문)
-
-
Redis와 싱글 스레드
-
Redis는 싱글 스레드를 사용
-
싱글 스레드로 인한 장점
-
멀티 스레드를 사용하며 발생하는 Context-Switch 비용을 줄임
-
스레드 간 자원 공유로 인한 문제에서 자유로움
-
-
싱글 스레드임에도 High-Performance를 보장
-
Redis는 CPU-intensive 하지 않음
-
Redis Cluster 기능을 활용해 더 많은 요청 처리 가능
-
이벤트 루프를 이용하여 요청을 수행. 즉, 실제 명령에 대한 작업은 커널 레벨에서 Multiplexing을 통해 처리하여 동시성을 보장
-
-
Redis가 멀티 스레드를 사용하는 경우
-
RDB 스냅샷을 생성할 때 자식 프로세스를 생성
-
Redis 4.0에서 도입된 ULINK 명령은 백그라운드 스레드에서 데이터를 삭제
-
Redis 6.0부터 멀티 스레드 도입, 명령 처리에서는 여전히 싱글 스레드 이용(원자성 보장)
-
클라이언트가 전송한 명령을 네트워크로 읽어서 Parsing하는 부분
-
명령이 처리된 결과 메시지를 클라이언트에게 네트워크로 전달하는 부분
-
-
-
Multiplexing을 쓰는 이유
-
Redis의 명령 처리에서 주요 버틀넥은 CPU가 아닌 네트워크 전송 대역폭에 있음
-
다중 소켓/다중 코어를 사용한다면 병렬처리를 위한 스레드 간 동기화가 매우 비쌈
-
따라서 동기화가 필요없는 고립된 이벤트루프(queue와 같은 형식으로 하나의 컨넥션에서 여러 요청들을 모아서 전송)를 통해 작업들을 수행
-
Redis의 복제 구성
-
복제란
-
레디스의 데이터를 거의 실시간으로 다른 레디스 노드로 복사하는 작업
-
AOF를 사용하고 있더라도 인스턴스를 재시작하는 데는 시간이 소요됨, 다운의 원인이 하드웨어라면, 재시작 및 데이터 복구가 되지 않을 수도 있음
-
-
Master Slave 구조
-
복제는 Master-Slave 구조로 이루어 짐. 이 때 Slave는 Read-Only만 가능
-
복제는 비동기(자식 프로세스)로 진행되어 Master의 서비스 운용에는 문제가 없음
-
-
복제 방식
-
전체 동기화(Full synchronization)
- Master가 RDB파일을 복제서버에 전송해 데이터를 동기화 하는 방식
-
부분 동기화(Partial resynchronization)
- Master와 Slave가 서로 간의 run id와 replication offset을 비교하여 부분 동기화
-
-
싱글 복제
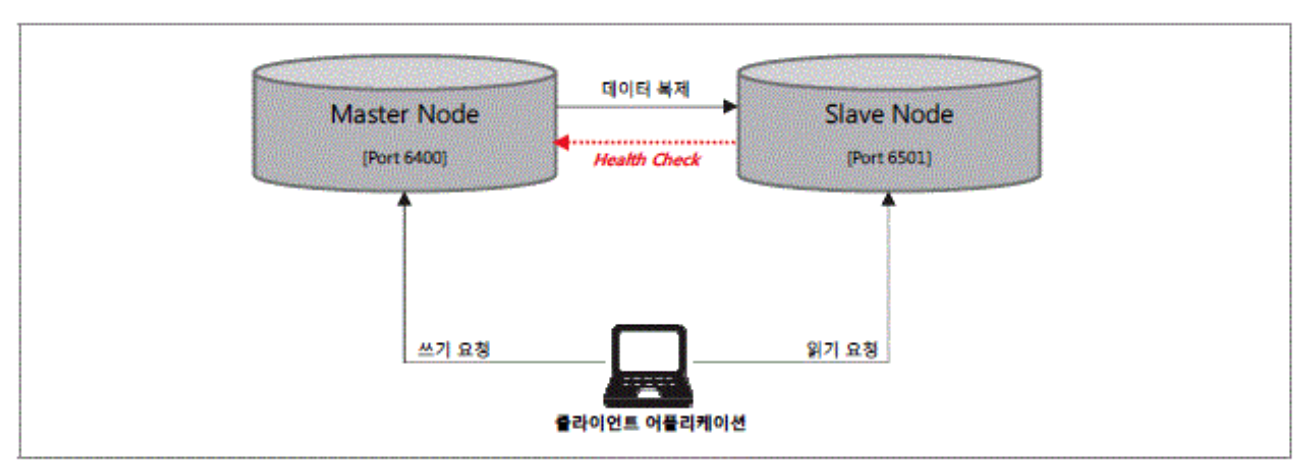
-
마스터와 슬레이브의 최초 연결시, 슬레이브에서 마스터 노드의 모든 데이터를 복제
-
이후 슬레이브 노드는 마스터 노드에 대한 지속적인 Health Check를 수행하며, 변경된 데이터를 전달 받음
-
마스터 노드는 쓰기 요청을, 슬레이브 노드는 읽기 요청을 담당
-
-
다중 복제
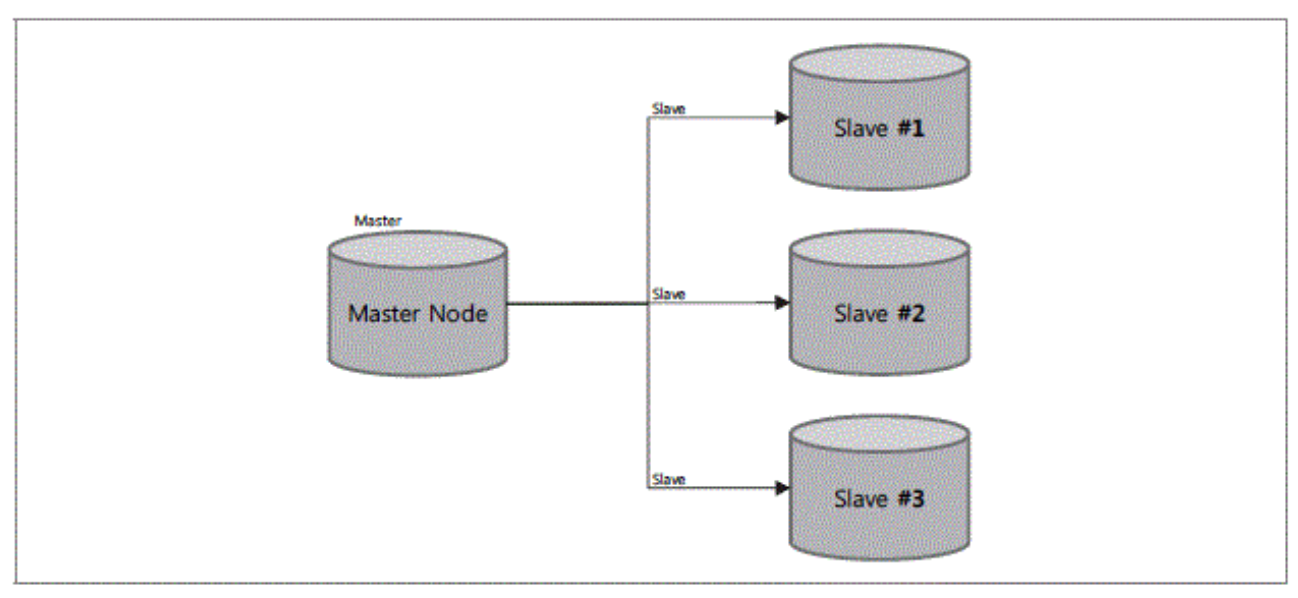
-
쓰기보다 읽기 요청이 높을 때 이에 대한 대응으로 다중복제를 사용
-
복제 방식은 싱글 복제와 동일
-
하지만 마스터 노드의 컴퓨팅 자원이 슬레이브 데이터 복제에 소모되어 서비스 성능 저하를 불러일으킬 수 있음
-
-
계층 복제
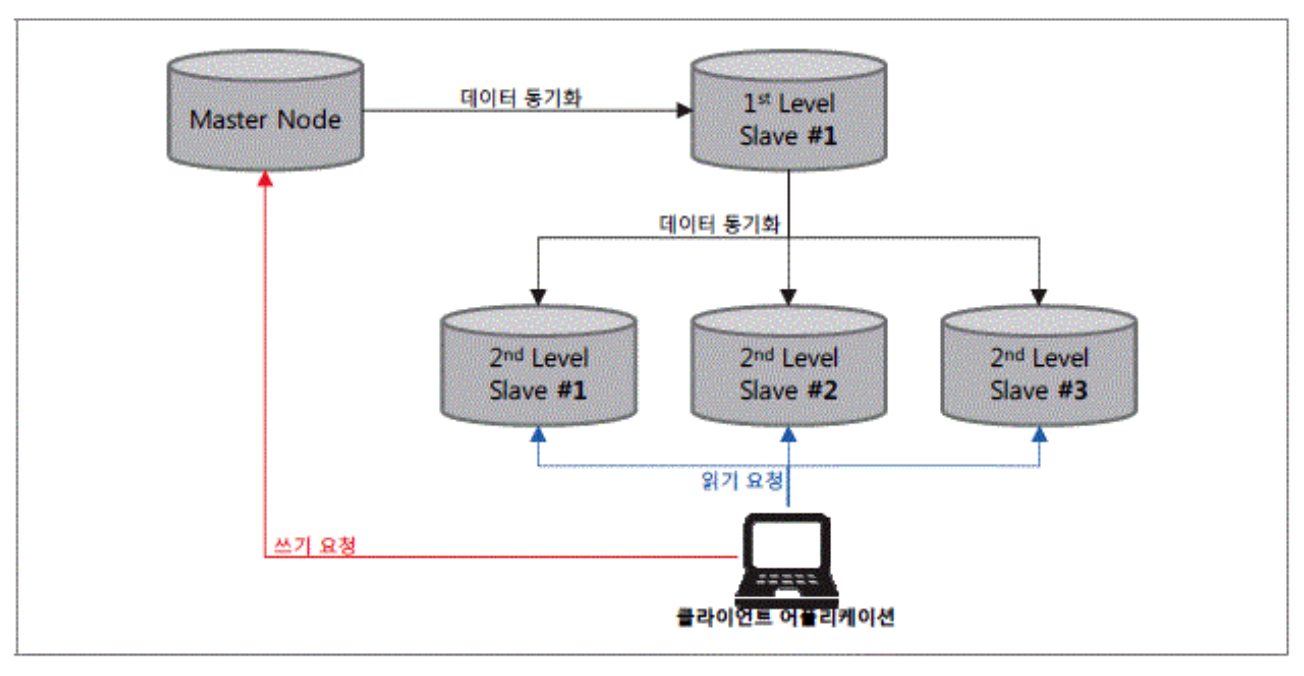
-
1 수준 슬레이브 노드가 2 수준 슬레이브 노드들에게 복제를 수행
-
다중 복제 대비 서비스 성능 향상
-
-
마스터 HA 복제(Sentinel)
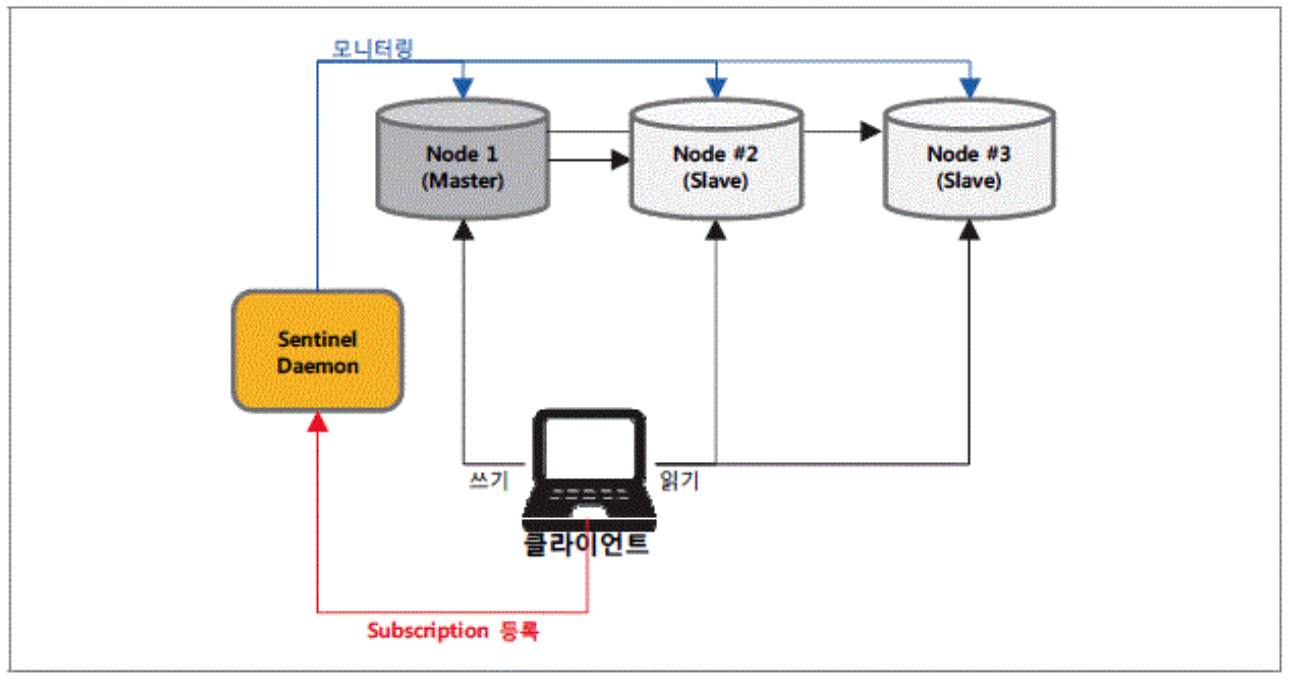
-
앞선 복제방식은 마스터 노드가 SPOF가 될 수 있음. 고가용성 HA 구성을 위해 서버 클러스터 구성을 사용
-
Redis에서는 Sentinel이라는 데몬을 통해 HA 요구사항을 충족. 마스터 노드의 교체 사실을 인지할 필요가 있는 클라이언트 노드들은 Redis Pub/Sub으로 Sentinel에 등록해야 함
-
Sentinel은 홀수 개로 구성하면 과반 정족수 이상이 Master의 fail을 감지하면, Failover을 진행하는 방식임(위 그림에서와 같이 Sentinel이 단일장애지점이 되지는 않음)
-
-
마스터 HA 복제(Sentinel)의 동작 방식
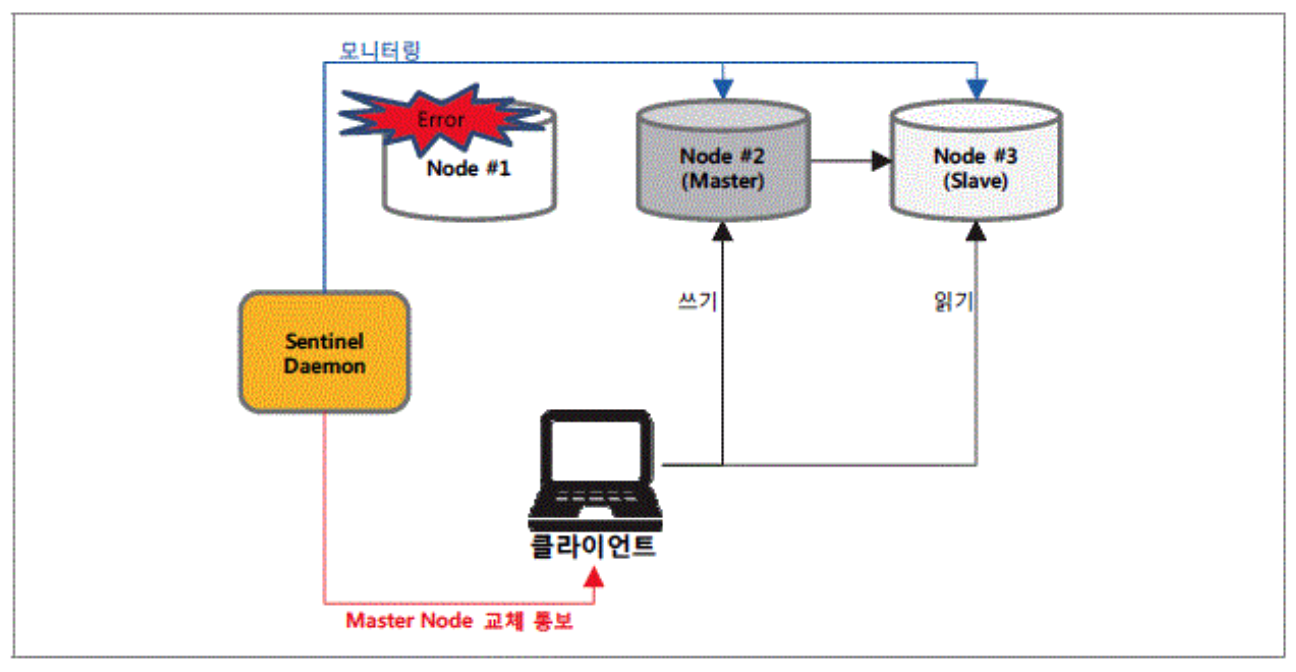
-
마스터 노드에 장애가 발생하면, Sentinel 데몬이 슬레이브 노드들 중 마스터 노드를 선택
-
신규 마스터 노드를 바라보도록 슬레이브 노드 설정을 변경
-
클라이언트에게 마스터 데몬 교체 사실을 통보
-
즉, 다중화 구성 및 Sentinel 적용으로 무중단 운영이 가능해짐을 의미
-
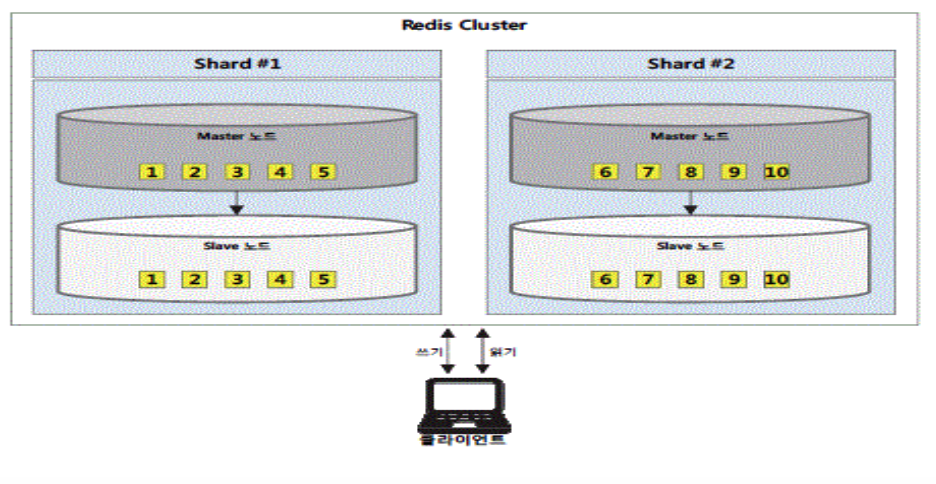
클러스터 구성 및 샤딩
-
Redis는 클러스터 구성을 활용하여 HA 및 샤딩을 지원함
-
클러스터 구성 시엔, 다중 Master(쓰기를 나눠서 함) 및 다중 Slave(각 마스터의 백업)가 필요
-
쓰기 성능 향상을 위한 레디스 샤딩
-
데이터 세트를 분산 저장하여 쓰기 성능 향상 도모
-
샤딩의 유형
-
수직 샤딩 : 데이터 성격을 기준으로 논리적으로 분할(데이터 분배가 골고루 되지 않을 수 있음)
-
영역 샤딩 : key value에 따라 데이터가 저장될 노드 결정(확장 축소에 유연하지 못함)
-
해시 샤딩 : Key의 해시 값에 따라 데이터가 저장될 노드를 결정(확장 축소에 유연, 권장 사항)
- 각 노드는 마스터 노드로 동작하며 해시 함수는 선택 가능
-
-