Data Fault Tolerance (고장 감내성)
-
Software
-
Hadoop은 기본적으로 data block에 대해 3개의 복제본을 유지(replication-factor)
-
이 data block은 fault tolerance를 위해 물리적으로 다른 위치(rack, data center)로 분산시킴
-
복제본 정책은 데이터 유실에 대한 좋은 수단이지만, trade-off(데이터 write 시 부하, 복제본 유지를 위한 추가 공간 필요)가 존재
-
-
Hardware
-
HW RAID 구성을 통해 소프트웨어 변경없이 데이터의 Fault Tolerance 수준을 높일 수 있음
-
단 추가 데이터 공간이 필요한 것은 동일하며, 저장/복구 과정에서 자원을 더 소모
-
RAID
-
RAID는 Redundant Array of Inexpensive Disks의 약어
-
이름 그대로 하드 디스크를 여러개의 독립적인 드라이브의 배열로 가상화하는 방식
-
RAID 하드웨어 컨트롤러를 사용하는 방식과, 운영체제 수준에서 소프트웨어 드라이브로 구현하는 방식이 있음
-
여기서는 Eraser Coding을 이해하는 데 도움이 되는 RAID-5와 RAID-6만 살펴볼 예정
- RAID-5

-
RAID-5는 최소 3개 이상의 드라이브로 구성
-
하나의 데이터 블록이 여러 개의 드라이브에 걸쳐 존재하도록 블록을 나눔
-
Parity라 불리는 블록을 추가로 다른 드라이브에 분산해서 저장
-
Write 시 parity 계산이 이루어져야 하므로 느림
-
하나의 드라이브에 장애가 발생하면, 해당 드라이브에 위치했던 블록의 데이터는 다른 드라이브에 있는 복제본과 패리티 블록을 이용해(Parity bit, XOR 연산) 복구가 가능. 단, 위 그림에서라면 2개 이상의 드라이브에 장애가 발생할 경우, 복구하지 못함
-
드라이브 수는 최대 16개까지 구성이 가능
-
RAID-6
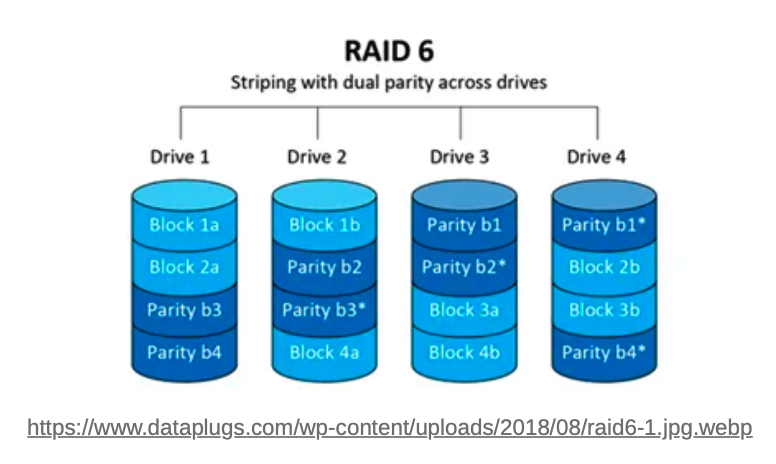
- RAID-6는 5와 유사하지만, Parity가 두 개의 드라이브에 나누어 쓰여짐
- 또한, Parity 연산이 XOR이 아닌 Reed-Solomon 부호로 패리티를 생성
- 최소 4개의 드라이브로 구성해야 하며, 위 동시 2개 의 드라이브 장애에 대해 복구할 수 있음
- Read는 RAID-5 정도로 빠르지만, Parity 블록이 하나 더 추가되므로 write는 RAID-5 보다 느림
- 주로 read 위주의 transaction이 필요한 웹 서버에 적합. write 부하가 높은 데이터베이스 등에는 부적합함
Eraser Coding
-
Hadoop의 Eraser Coding(EC)는 RAID 방식을 소프트웨어로 구현한 것. RAID 5, 6과 같이 패리티를 이용해 복구. 차이점은 패리티를 계산하는 방법
-
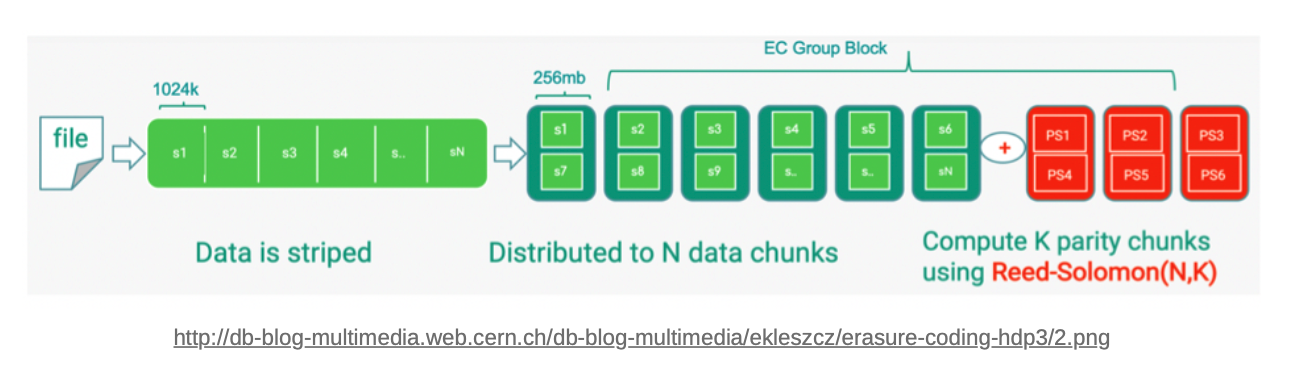
EC는 RAID-6처럼 데이터를 조각으로 나눠 Reed-Solomon과 같은 알고리즘을 사용해 데이터 패리티를 생성하며, 데이터 보호 수준을 유연하게 설정할 수 있다는 점에서 RAID와 차별화 됨
-
N 개의 블록 조각을 연산을 통해 K개의 패리티를 생성. 이 N + K 개 중 최대 K 개의 데이터가 손실되어도 원본 데이터의 복구가 가능
- N : 몇 개의 Chunk로 나눌지
- K : 몇 개의 Parity로 구성할 지
- RS(N,K)
-
Eraser Coding의 장점
-
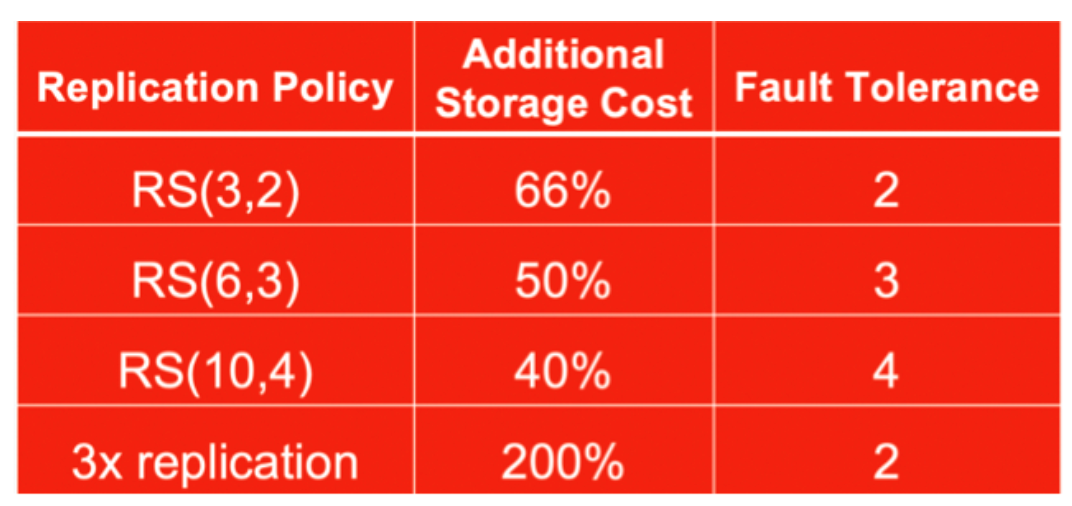
EC를 통해 데이터 복구 가능성은 높이면서 Storage의 Capacity Loss(추가로 할당해야 하는 공간)를 줄일 수 있음
-
N, K 설정 값에 따라 달라지지만, 기존 3개의 replica로 최소한 2배 이상의 Storage를 추가로 사용하는 것보다 모든 경우에 좋음(아래 그림 참조)
-
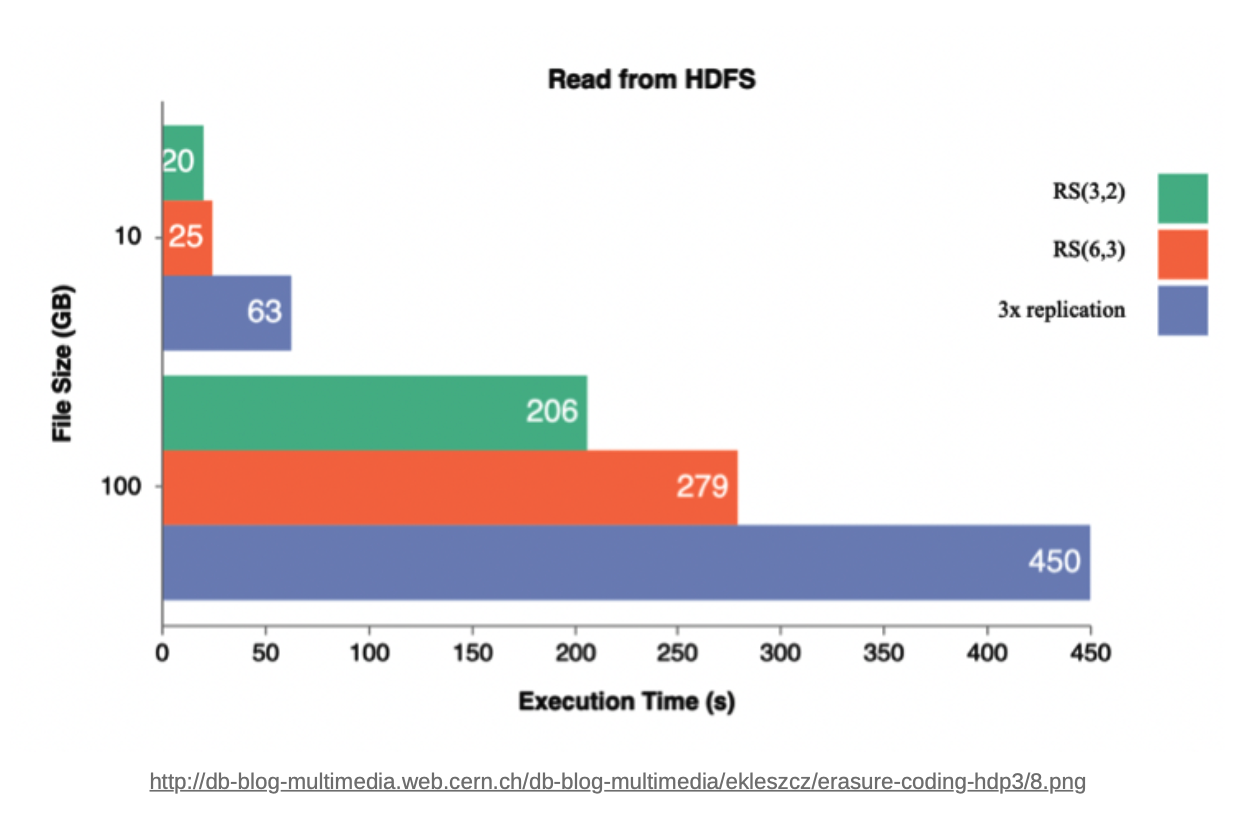
Striped block을 통해 논리적인 블록 1개에 대한 병렬성이 높아지므로, read performance도 향상됨(아래 그림 참조)
-
-
Eraser Coding의 단점
-
EC는 단순 복사에 비해 encoding 과정이 추가되며, Write 시에 Parity 계산이 동반되므로 Write 성능이 떨어짐
-
다만, Intel에서 개발한 ISA-L encoder library으로 단점이 어느 정도 상쇄됨(약 30% 감소)
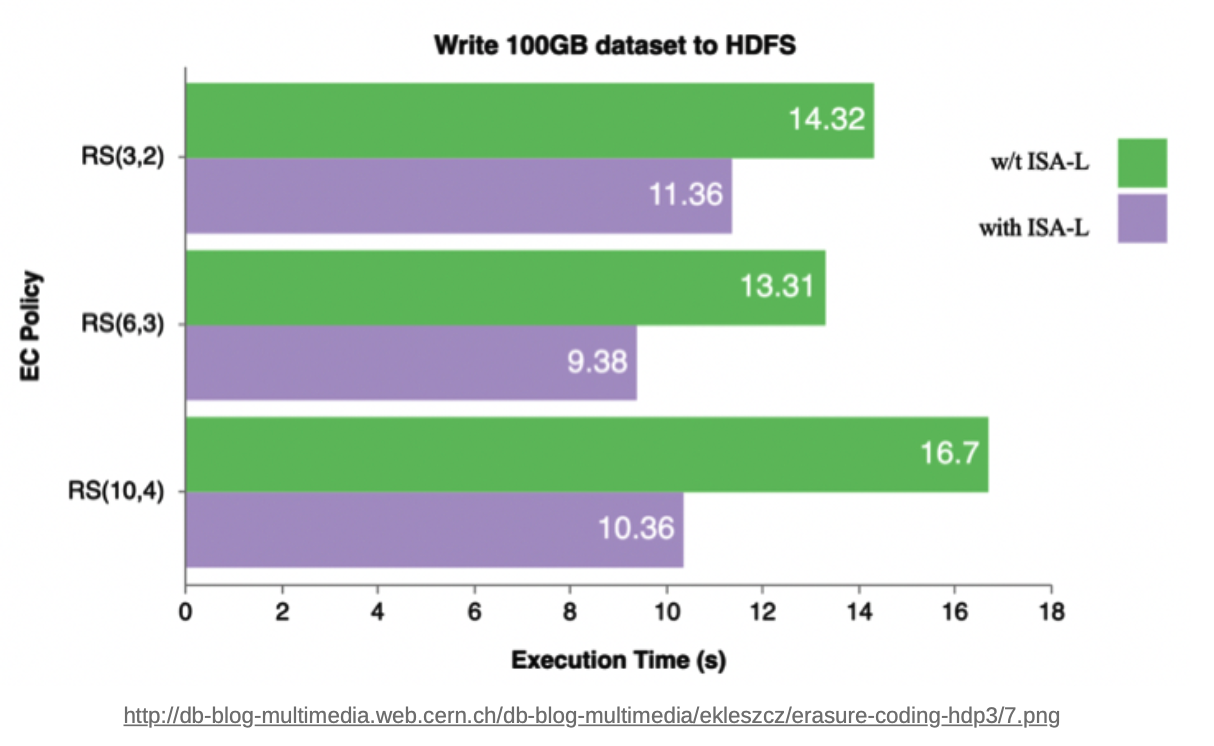
-
데이터 지역성 확보가 어려움. HDFS는 기본적으로 MR 등의 작업을 처리할 때, 실제 Data가 저장 중인(혹은 가까운) Data Node를 통해 작업을 수행하여 네트워크 자원 낭비를 줄이며 속도를 개선함. 하지만 EC의 경우 여러 노드에 거쳐 데이터가 분산 저장되므로 기존 대비 속도 저하가 발생함
-
