스키마와 상위/하위 호환성
-
앞선 예제에서와 같이 부호화된 레코드는 결국 부호화된 필드의 연결일 뿐임. 각 필드는 태그 숫자(예제 스키마의 숫자 1,2,3)로 식별하고 데이터 타입을 주석으로 달고, 필드 값을 설정하지 않은 경우엔 단순히 부호화 레코드에서 생략하는 방식
-
필드 태그는 부호화된 데이터를 해석하기 위한 방식이기 때문에, 변경할 수 없음(변경시, 기존 모든 부호화된 데이터를 인식할 수 없기 때문)
-
스키마에 새로운 필드를 추가하기 위해선 새로운 필드번호를 부여하기만 하면 되고, 이전 코드에서 새로운 데이터를 읽으려는 경우 해당 필드를 무시하기만 하면 됨. 즉, 상위 호환성을 간단하게 유지할 수 있음
-
하위 호환성은 새로운 필드가 추가될 때 required가 아닌 optional로 지정하는 방식으로 해결. 이전 코드가 데이터를 기록할 때 새로운 필드를 기록할 수 없기 때문에 최신 코드가 해당 데이터를 읽으려 시도할 때 에러가 발생할 수 있음. 따라서 optional 형태의 필드로 추가해 최신 코드가 해당 데이터가 없더라도 문제가 없게 함
-
필드를 삭제할때는 앞선 방식과 정반대로 작용. 즉, optional 필드만 삭제할 수 있고, 같은 태그를 절대 다시 사용하지 않음
-
데이터 타입의 변경
-
불가능하지는 않지만, 정밀도에 문제가 생길 수 있음
-
이를테면 32비트 정수를 64비트 정수로 바꾼다면 누락된 비트를 단순히 0으로 채우기만 하면 됨. 하지만, 이전 코드는 여전히 64비트 정수를 읽기 위해 32비트 변수를 사용하므로 잘리게 되는 위험이 존재
-
아브로(Avro)
-
앞선 포스팅에 예시로 나온 스리프트 등이 하둡의 사용 사례에 적합하지 않아 2009년 하둡의 하위 프로젝트로 시작한 이진 부호화 형식
-
역시 스키마를 사용하며 Avro IDL이나 JSON 기반 언어로 작성 가능. 보통 JSON으로 사용함

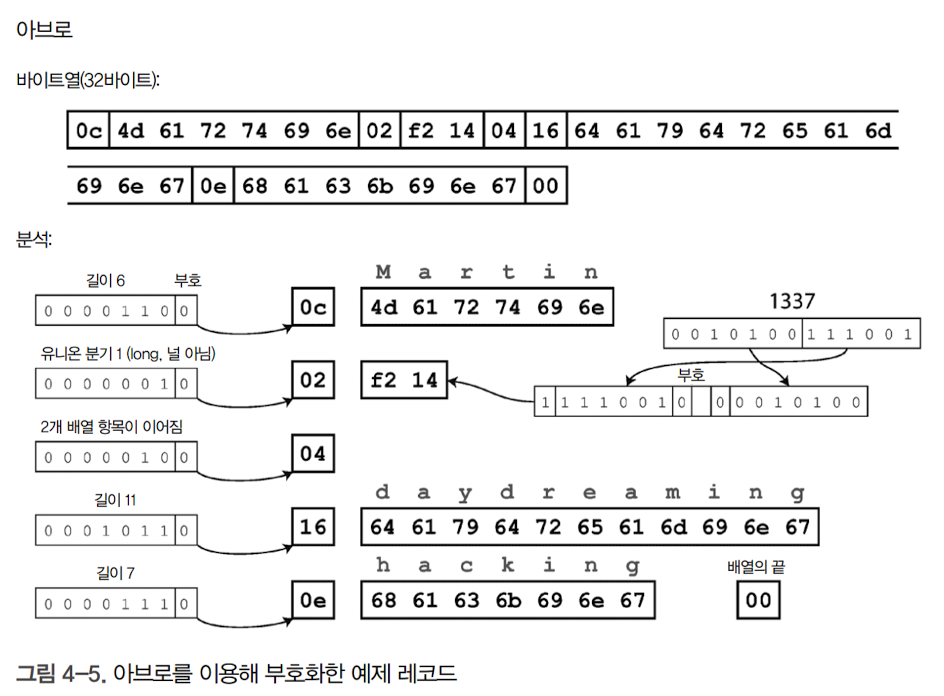
-
특징
-
스키마에 태그 번호가 없으며, 바이트열에도 필드나 데이터 타입을 식별하기 위한 정보가 없음. 부호화는 단순히 연결된 값으로 구성됨
-
즉, 아브로는 이진 데이터를 파싱하기 위해 스키마에 나타난 순서대로 필드를 살피고, 스키마를 이용해 각 필드의 데이터 타입을 미리 파악해야 함을 의미
-
이는 데이터를 읽는 코드가 데이터를 기록한 코드와 정확히 같은 스키마를 사용해야만 이진 데이터를 올바르게 복호화할 수 있음을 의미
-
-
쓰기 스키마와 읽기 스키마의 분리
-
아브로는 부호화를 위한 쓰기 쓰키마(writer's schema)와 복호화를 위한 읽기 스키마(reader's schema)를 구분해서 사용
-
핵심 아이디어는 쓰기 스키마와 읽기 스키마가 동일할 필요가 없으며, 단지 호환 가능하면 된다는 것.
-
즉, 데이터를 복호화할 때 쓰기 스키마와 읽기 스키마를 함께 살핀 후, 쓰기 스키마에서 읽기 스키마로 데이터를 변환해 그 차이를 해소
-
필드의 순서가 달라도 상관없음(필드 이름으로 구분)
-
데이터를 읽는 코드가 읽기 스키마에 없고 쓰기 쓰기 스키마에만 존재하면 필드를 무시함
-
반대의 경우에는 기본값으로 채움
-
-
required, optional field가 존재하지 않음
-
대신 union type을 사용
-
를 들어 union { null, long, string } field;는 field가 수나 문자열 또는 널일 수 있다는 의미
-
-
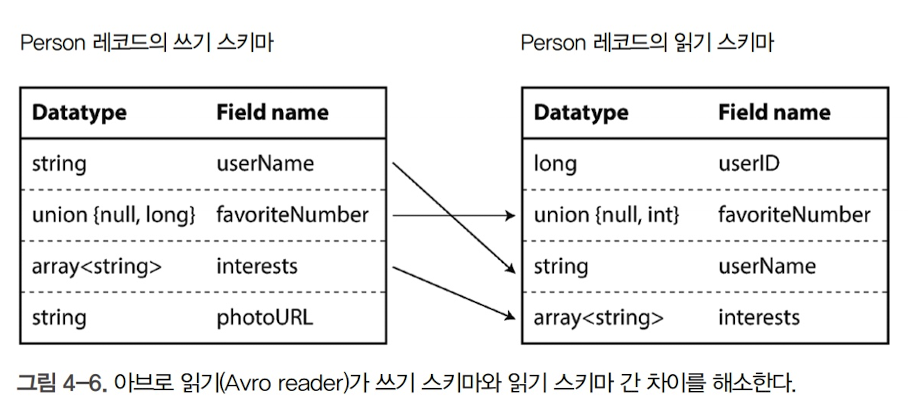
쓰기 스키마의 처리
-
모든 레코드에 쓰기 스키마를 처리하는 것은 공간적 낭비가 심함. 이를 위해 다양한 방식을 활용
-
많은 레코드가 있는 대용량 파일
- 아브로의 일반적인 용도(하둡)에서는 모두 동일한 스키마로 수백만 개의 레코드를 포함한 파일을 저장함. 따라서 쓰기 스키마를 파일의 시작 부분에 한 번만 씀
-
개별적으로 기록된 레코드를 가진 데이터베이스
- 데이터베이스의 다양한 레코드들은 다양한 쓰기 ㅅ스키마를 사용해 서로 다른 시점에 쓰여질 수 있음. 가장 간단한 해결책은 모든 부호화된 레코드의 시작 부분에 버전 번호를 포함하고 데이터베이스에는 스키마 버전 목록을 유지해서 필요한 스키마 버전을 가져오는 형태로 해결
-
네트워크 연결을 통해 레코드 보내기
- 두 프로세스가 양방향 네트워크를 통해 통신할 때 연결 설정에서 스키마 버전 합의하고 이후 합의된 스키마를 사용. 아브로 RPC 프로토콜이 이처럼 동작
동적 생성 스키마
-
아브로의 장점
-
앞서 살펴본 스리프트 등은 스키마에 태그 번호가 포함되어 있고, 아브로는 그렇지 않음
-
이 차이가 동적 생성 스키마에 강점으로 작용함
-
왜냐하면 스리프트의 경우 스키마 변경 시, 이전에 사용된 필드 태그가 다시 할당되지 않게끔해야하기 때문
스키마의 장점
- 아브로 스키마 언어는 XML 스키마나 JSON 스키마보다 훨씬 간단하며 더 자세한 유효성 검사 규칙을 제공
- 부호화된 데이터에서 필드 이름을 생략할 수 있으므로 이진 JSON 변형보다 크기가 훨씬 작음
- 복호화를 수행할 때 스키마의 최신성을 확인할 수 있음(수동으로 관리한다면 관리 포인트가 늘어나게 됨)
- 스키마 데이터베이스를 유지하면 스키마 변경이 적용되기 전에 상위/하위 호환성을 확인할 수 있음
