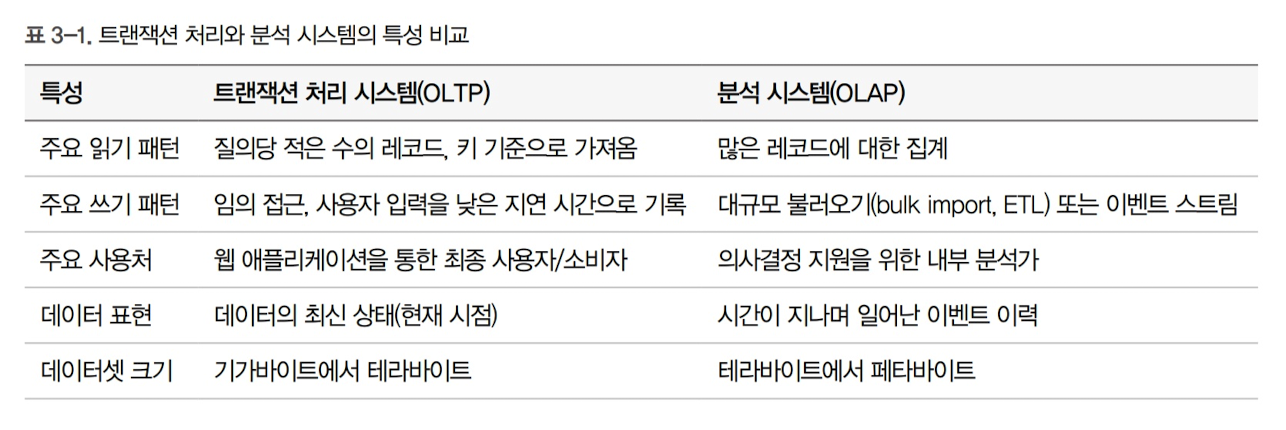
OLTP vs OLAP
-
고수준에서 저장소 엔진은 트랜잭션 처리 최적화(OLTP)와 분석 최적화(OLAP)라는 두 가지 범주로 나뉨
-
OLTP
- 보통 대량의 요청을 받음. 보통 애플리케이션이 각 질의마다 작은 수의 레코드를 다룸.저장소 엔진은 데이터를 찾기 위해 색인을 사용하며, 대개 디스크 탐색이 병목으로 작용
-
OLAP
- 데이터 웨어하우스와 유사한 분석 시스템은 비즈니스 분석가가 주로 사용. OLTP보다 적은 수의 질의를 다루지만, 대개 다루기 어렵고 짧은 시간에 수백만 개의 레코드를 스캔하는 질의. 이 경우, 디스크 탐색이 아닌 디스크 대역폭이 병목지점으로 작용.
-
트랜잭션 처리와 분석
트랜잭션이 반드시 ACID(원자성, 일관성, 격리성, 지속성)를 가질 필요는 없음. 트랜잭션 처리는 일괄 처리 작업과 달리 클라이언트가 지연 시간이 낮은 읽기와 쓰기를 가능하게 한다는 의미. (ACID, 일괄처리에 대해서는 추후에 다룰 예정)
-
트랜잭션 처리는 온라인 상거래에서 처음 시작. 여러 종류의 데이터를 다루는 트랜잭션도 접근 패턴은 비슷함. 애플리케이션은 색인을 사용해 일부 키에 대한 적은 수의 레코드를 찾음. 이러한 방식은 대화식이기 때문에 이를 온라인 트랜잭션 처리(OnLine Transaction Processing, OLTP) 라고 함
-
최근엔 데이터베이스를 데이터 분석에 사용하는 추이. 데이터 분석은 트랜잭션과 접근 방법이 다름. 분석 질의는 보통 원시 데이터를 반환하지 않으며 수 많은 레코드를 스캔해 레코드 당 일부 칼럼만 읽어(count, sum, avg) 집계 통계를 계산. 이런 데이터베이스 사용 패턴을 온라인 분석 처리(OnLine Analytic Processing, OLAP) 라고 함
-
이를 표로 나타내면 다음과 같음
데이터 웨어하우징
-
대개 기업은 수십 가지 트랜잭션 처리 시스템을 갖춤. 이런 시스템은 복잡해서 보통 각 시스템을 독자적으로 관리함. OLTP 시스템은 사업 운영에 매우 중요하기 때문에 일반적으로 높은 가용성과 낮은 지연시간의 트랜잭션 처리를 기대함.
-
따라서 비즈니스 분석가가 OLTP 데이터베이스에 애드혹 분석 질의를 실행하는 것을 꺼림. 애드혹 분석 질의는 비용이 비싸며, 이로 인해 트랜잭션 성능이 저하될 수 있기 때문
-
데이터 웨어하우스는 분석가들이 OLTP 작업에 영향을 주지않고 질의할 수 있는 개별 데이터베이스. 다시 말해, 회사 내의 모든 OLTP 시스템에 있는 데이터의 읽기 전용 복사본임
-
ETL
- 데이터는 OLTP 데이터베이스에서 추출(Extract)하고 분석 친화적인 스키마로 변환(Transform)하고 깨끗하게 정리한 다음 데이터 웨어하우스에 적재(Load)한다.
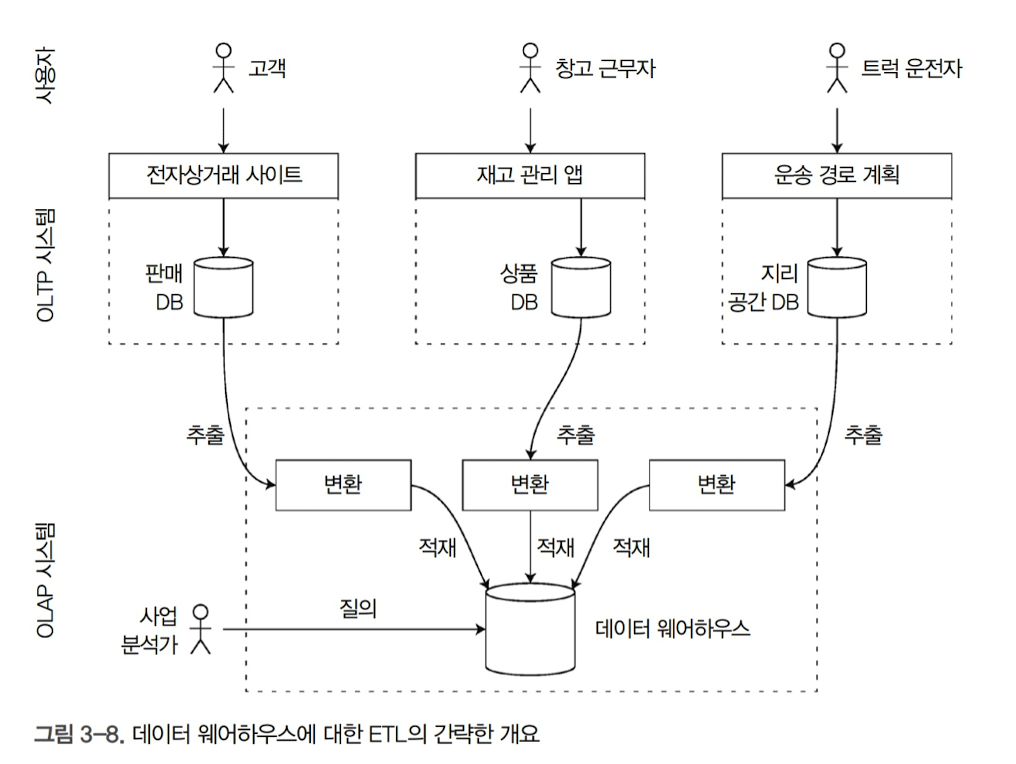
- 분석을 위해 데이터 웨어하우스를 사용하는 큰 장점은 분석 접근 패턴에 맞게 최적화를 할 수 있다는 점(분석에 최적화된 저장소 엔진을 사용)
분석용 스키마
-
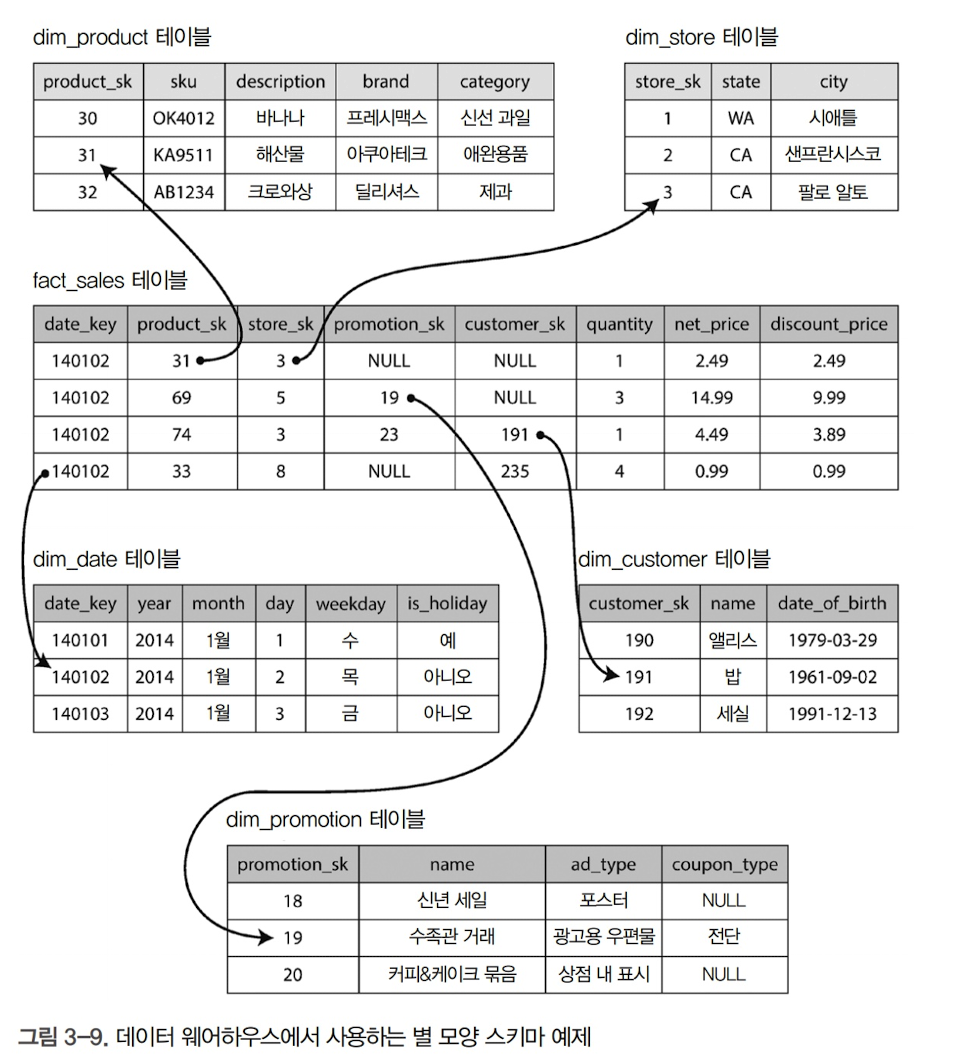
별 모양 스키마(Star Schema)(차원 모델링(Dimensional Modeling))
-
위 예제는 식료품 소매업에서 볼 수 있는 데이터 웨어하우스를 나타냄
-
스키마 중심에 소위 사실 테이블(Fact Table)이 존재하며, 사실 테이블의 각 로우는 특정 시각에 발생한 개별 이벤트에 해당됨
-
사실 테이블의 다른 칼럼은 차원 테이블(Dimension Table)이라고 불리는 다른 테이블을 가리키는 외래 키 참조임. 차원 테이블은 이벤트의 속인인 누가, 언제, 어디서, 무엇을, 어떻게, 왜를 나타냄
-
이러한 스키마를 사용하는 이유는 분석의 유연성을 극대화할 수 있기 때문
-
눈꽃송이 모양 스키마(Snowflake Schema)
- 별 모양 스키마의 변형이며, Dimension Table(하위 차원)을 또다른 하위 차원으로 세분화 하는 것을 말함
-
칼럼 지향 저장소
-
Fact Table은 보통 수 많은 칼럼과 로우(페타바이트 단위) 데이터로 이루어질 수 있음. 이에 반해, 차원 테이블은 보통 수백만 로우 정도로 훨씬 적음
-
Fact Table은 보통 칼럼이 100개 이상이지만 일반적인 데이터 웨어하우스 질의는 한 번에 4개 또는 5개 칼럼만 접근(분석용으로는 "Select *" 질의가 거의 필요하지 않음)
-
대부분의 OLTP 데이터베이스는 로우 지향으로 데이터를 배치하며, 몇 개의 칼럼만을 불러오는 질의를 실행하더라도 디스크로부터 모든 로우를 메모리로 적재한 다음 구문을 해석해 필요한 조건을 충족하지 않은 로우를 필터링해야하는 문제가 발생
-
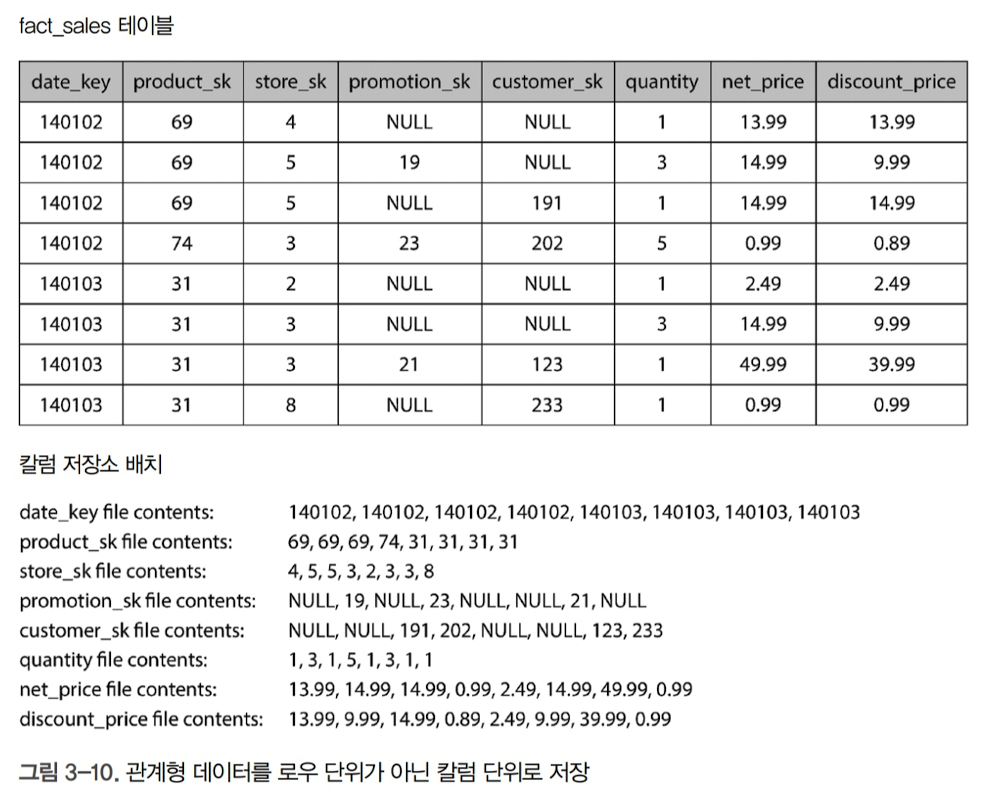
칼럼 지향 저장소의 개념은 모든 값을 하나의 로우에 함께 저장하지 않는 대신, 각 칼럼별로 모든 값을 함께 저장한다는 개념
-
칼럼 저장소의 배치는 각 칼럼 파일에 포함된 로우가 모두 같은 순서인 점에 의존함
-
칼럼 지향 저장소를 사용할 때의 또 다른 이점은 칼럼 압축임. 보통 칼럼에서 고유 값의 수는 로우 수에 비해 적음(수십억개의 판매 거래가 있더라도 고유 제품은 단지 몇 십만 개 수준일 것)
-
다양한 압축기법을 사용할 수 있으며, 대표적으로 비트맵 부호화(bitmap encoding)가 있음

카산드라와 HBase는 빅테이블로부터 내려오는 칼럼 패밀리 개념이 존재하지만, 이를 칼럼 지향이라고 부르기에는 오해의 소지가 있음. 각 칼럼 패밀리 안에는 로우 키에 따라 로우와 모든 칼럼을 함께 저장하며 칼럼 압축을 사용하지 않음. 따라서 빅테이블 모델은 여전히 대부분 로우 지향임
-
벡터화 처리
-
칼럼 압축은 CPU 주기를 효율적으로 사용할 수 있게 함
-
질의 엔진은 압축된 칼럼 데이터를 CPU의 L1 캐시에 딱 맞게 덩어리로 나누어 가져오고 이 작업을 (함수 호출이 없는) 타이트 루프(tight loop)에서 반복함.
-
칼럼 압축을 사용하면 같은 양의 L1캐시에 칼럼의 더 많은 로우를 저장할 수 있음. 비트 AND와 OR 같은 연산자는 압축된 칼럼 데이터 덩어리를 바로 연산할 수 있게 설계할 수 있음. 이런 기법을 백터화 처리(vectorized processing)라고 함 // 찾아보기
-
-
데이터 큐브와 구체화 뷰
-
데이터 웨어하우스 질의는 보통 SQL의 COUNT, SUM, AVG, MIN, MAX)와 같은 집계 함수를 포함
-
동일한 집계를 다양한 질의에서 사용한다면, 캐시하는 건 어떨까?라는 의문에서 생겨난 것이 구체화 뷰(materialized view)
-
원본 데이터가 변경되면 구체화 뷰를 갱신해야 함. 구체화 뷰는 원본 데이터의 비정규화된 복사본이기 때문. OLTP에서는 이러한 갱신으로 인한 쓰기 비용이 비싸기 때문에 자주 사용하지 않지만, 데이터 웨어하우스는 읽기 비중이 크기 때문에 구체화 뷰를 사용하는 전략이 합리적임
-
데이터 큐브(data cube) 또는 OLAP 큐브라고 알려진 구체화 뷰는 일반화된 구체화 뷰의 특별 사례임
-
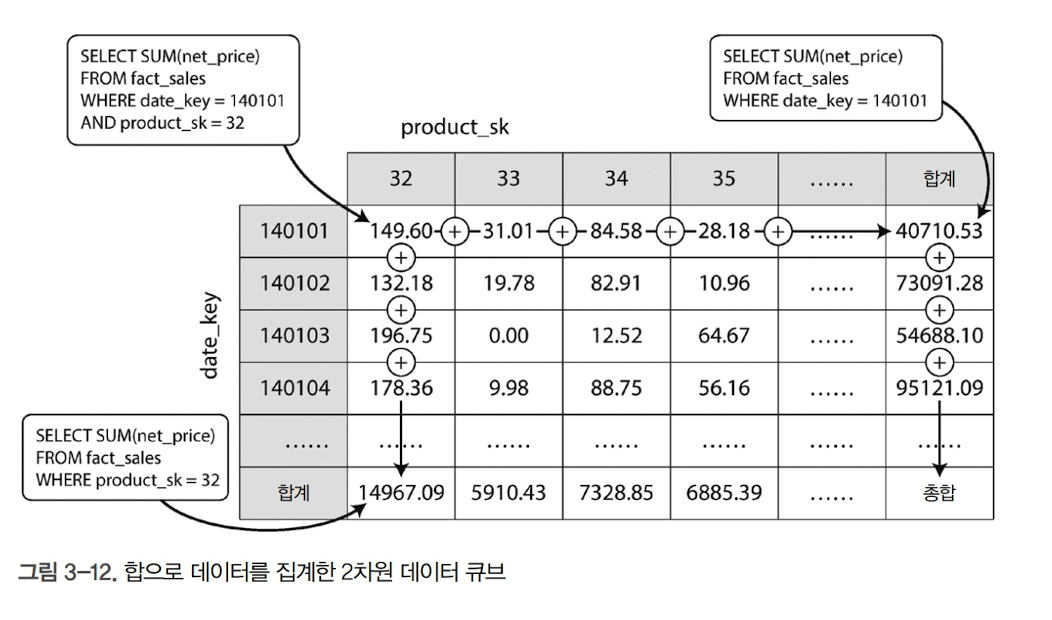
-
데이터 큐브의 장점은 특정 질의를 미리 계산했기 때문에 해당 질의를 수행할 때 매우 빠르다는 점임
-
하지만, 데이터 큐브는 원시 데이터에 직접 질의하는 것과 동일한 유연성은 없음. 이를 테면 가격이 차원 중 하나가 아니라면, 가격이 100달러 이상인 항목에서 발생한 판매량의 비율을 계산할 수 있는 방법이 없음
