스트림 처리
-
지금까지 스트림은 어디서 오는지(사용자 활동 이벤트, 센서, 데이터베이스에 쓰기)와 스트림이 어떻게 전송되는지(직접 메시징, 메시지 브로커, 이벤트 로그)에 대해 설명함
-
스트림을 처리하는 방법에는 크게 세 가지가 있음
-
이벤트에서 데이터를 꺼내 데이터베이스나 캐시, 검색 색인에 기록하고 다른 클라이언트가 이 시스템에 해당 데이터를 질의
-
이벤트를 사용자에게 직접 보냄. 예를 들어 이메일 경고나 푸시 알림 전송, 이벤트를 대시보드로 보내기
-
하나 이상의 입력 스트림을 처리해 하나 이상의 출력 스트림을 생성. 스트림은 1, 2번 선택지(최종 출력)에 이르기까지 여러 처리 단계로 구성된 파이프라인을 통과할 수 있음
-
-
이번 장은 스트림을 처리해 다른 파생 스트림을 생산하는 3번에 대해 다룸
-
이처럼 스트림을 처리하는 코드 조각을 연산자(operator)나 작업(job)이라고 부름
-
유닉스 프로세스, 맵리듀스 작업과 밀접한 관련을 지니며, 스트림 처리자는 읽기 전용 방식으로 입력 스트림을 소비해 추가 전용 방식으로 다른 곳에 출력을 씀
-
스트림 처리자를 파티셔닝하고 병렬화하는 양식도 맵리듀스, 데이터플로 엔진의 양식과 유사함
-
다만 일괄처리와 다른 점은 스트림은 끝나지 않는다는 것
-
끝없는 데이터셋을 정렬하는 것은 불가능함. 즉, 정렬 병합 조인을 사용할 수 없음
-
내결함성 메커니즘의 변경이 필요함. 일괄처리는 실패한 태스크를 처음부터 재시작하는 것으로 충분하지만, 몇 년 동안 실행 중인 스트림을 처음부터 재시작하는 것은 비현실적임
-
스트림 처리의 사용
-
스트림 처리는 특정 상황이 발생하면 경고를 해주는 모니터링 목적으로 오랜 기간 사용되어 왔음
-
사기 감지 시스템은 신용카드 사용 패턴의 변화를 감지해 도난된 것으로 의심되면 카드 결제를 막음
-
거래 시스템은 금융 시장의 가격 변화를 감지해서 특정 규칙에 딸 거래를 실행
-
제조 시스템은 공장의 기계 상태를 모니터링하다 오작동을 발견하면 빨리 문제를 규명함
-
-
그러나 시간이 흐르며 다른 용도로 스트림 처리를 사용하기 시작함
복잡한 이벤트 처리
-
복잡한 이벤트 처리(complex event proccessing, CEP)는 1990년대 이벤트 스트림 분석용으로 개발된 방법
-
CEP는 특정 이벤트 패턴을 검색하는 애플리케이션에 특히 적합
-
CEP는 정규 표현식으로 문자열에서 특정 문자 패턴을 찾는 방식과 유사하게 스트림에서 특정 이벤트 패턴을 찾는 규칙을 규정할 수 있음
-
해당 매치를 발견하면 엔진은 감지한 이벤트 패턴의 세부 사항을 포함하는, 글자 그대로 복잡한 이벤트를 방출함
-
이 시스템에서 질의와 데이터의 관계는 일반적인 데이터베이스와 반대로 작동함. 데이터베이스는 데이터를 영구적으로 저장하고 질의를 일시적으로 다룸
-
하지만 CEP에서는 질의는 오랜 기간 동안 저장되고, 입력 스트림으로부터 들어오는 이벤트는 지속적으로 질의를 지나 흘러가면서 이벤트 패턴에 매칭되는 질의를 찾음
-
CEP 구현에는 에스퍼(Esper), IBM 인포스피어 스트림, 아파마(Apama), SQL스트림 등이 있으며, 쌈자(samza)와 같은 분산 스트림 처리자는 스트림에 선언형 질의를 하는 SQL도 지원
스트림 분석
-
스트림 처리를 사용하는 다른 영역에는 스트림 분석이 있음
-
CEP와 스트림 분석 사이의 경계는 불분명하지만, 일반적으로 분석은 연속한 특정 이벤트 패턴을 찾는 것보다 대량의 이벤트를 집계하고 통계적 지표를 뽑는 것을 더 우선함
-
특정 유형의 이벤트 빈도 측정(시간당 얼마나 자주 발생하는지)
-
특정 기간에 걸친 값의 이동 평균(rolling average) 계산
-
이전 시간 간격과 현재 통계값의 비교(추세를 감지하거나 지난 주 대비 비정상적으로 높거나 낮은 지표에 대해 경고)
-
-
일반적으로 이런 통계는 고정된 시간 간격을 기준으로 계산하며, 집계 시간 간격을 윈도우(window)라고 함
-
스트림 분석 시스템은 확률적 알고리즘을 사용하기도 함. 집합 구성원 확인 용도의 블룸 필터(Bloom filter), 원소 개수 추정 용도의 하이퍼로그로그(HyperLogLog), 백분위 추정 알고리즘 등이 있음
-
확률적 알고리즘은 근사 결과를 제공하며, 스트림 처리자 내에서 차지하는 메모리가 정확한 알고리즘을 쓸 때보다 상당히 적음
-
하지만 확률적 알고리즘을 이용한 스트림 처리가 본질적으로 근사적이라기보다는, 일종의 최적화 기법이라고 생각하는 것이 마땅함
-
아파치 스톰(Apache Storm), 스파크 스트리밍(Spark Streaming), 플링크(Flink), 콩코드(Concord), 쌈자(Samza), 카프카 스트림(Kafka Streams) 등 분산 스트림 처리 오픈소스 프레임워크가 분석 용도로 설계됨. 호스팅 서비스로는 구글 클라우드 데이터플로와 애저 스트림 분석이 있음
구체화 뷰 유지하기
-
스트림은 캐시, 검색 색인, 데이터 웨어하우스와 같은 파생 데이터 시스템이 원본 데이터베이스의 최신 내용을 따라잡게 하는 데 쓸 수 있음
-
이런 예들은 구체화 뷰를 유지하는 특별한 사례임
-
어떤 데이터셋에 대한 또 다른 뷰를 만들어 효율적으로 질의할 수 있게 하고 기반이 되는 데이터가 변경될 때마다 뷰를 갱신함
-
구체화 뷰의 경우 스트림 분석 시나리오와는 달리 어떤 시간 윈도우 내의 이벤트만 고려하는 것으로는 충분하지 않음
-
구체화 뷰를 만들려면 잠재적으로 임의의 시간 범위에 발생한 모든 이벤트가 필요하며, 그 결과 시작 지점까지 늘려진 윈도우가 필요함
-
대부분 분석 지향 프레임워크의 가정 아래에서 이벤트를 영원히 유지해야 할 필요성은 서로 상반되지만, 이론상으로는 어떤 스트림 처리자라도 구체화 뷰를 유지하는 데 쓸 수 있음. 쌈자와 카프카 스트림은 카프카의 로그 컴팩션 지원을 기반으로 구체화 뷰 유지 용도로 사용할 수 있음
스트림 상에서 검색하기
-
복수 이벤트로 구성된 패턴을 찾는 CEP 외에도 전문 검색 질의와 같은 복잡한 기준을 기반으로 개별 이벤트를 검색해야 하는 경우도 있음
-
엘리스틱서치의 여과(percolator) 기능은 이런 류의 스트림 검색을 구현하는 데 사용 가능한 선택지 중 하나
-
전통적인 검색 엔진은 먼저 문서를 색인하고 색인을 통해 질의를 실행하지만, 스트림 검색은 처리 순서가 뒤집힘
-
즉, 질의를 먼저 저장하며 CEP와 같이 문서는 질의를 지나가면서 실행됨
-
엄청나게 많은 질의가 있다면 매우 느리겠지만, 이 과정을 최적화하기 위해 문서뿐만 아니라 질의도 색인할 수 있음
메시지 전달과 RPC
-
"메시지 전달 데이터플로"에서 메시지 전달 시스템을 RPC 대안으로 사용할 수 있다고 설명했음
-
즉 액터 모델 등에서 쓰이는 서비스 간 통신 메커니즘으로 사용할 수 있음
-
액터 프레임워크는 주로 동시성을 관리하고 통신 모듈을 분산 실행하는 메커니즘임. 반면 스트림 처리는 기본적으로 데이터 관리 기법임
-
액터 간 통신은 주로 단기적이고 일대일임. 반면 이벤트 로그는 지속성이 있고 다중 구독이 가능함
-
액터는 임의의 방식으로 통신할 수 있음(순환 요청/응답 패턴) 그러나 스트림 처리자는 대개 비순환 파이프라인에 설정됨. 파이프라인에서 모든 스트림은 특정 작업의 출력이며 잘 정의된 입력 스트림 집합에서 파생됨
-
-
유사 RPC 시스템과 스트림 처리에는 겹치는 영역이 존재. 예를 들어 아파치 스톰에는 분산 RPC(distribueted RPC)라는 기능이 존재. 이 기능을 사용하면 이벤트 스트림을 처리하는 노드 집합에 질의를 맡길 수 있음. 이 질의는 입력 스트림 이벤트가 끼워지고 그 결과들을 취합해 사용자에게 돌려줌
-
반대적으로 액터 프레임워크를 이요해 스트림 처리도 가능하지만, 액터 프레임워크는 대부분 장애 상황에서 메시지 전달을 보장하지 않기 때문에 내결함성을 보장하지 못함
시간에 관한 추론
-
스트림 처리자는 종종 시간을 다뤄야 함. 주로 "지난 5분 동안 평균"과 같은 시간 윈도우를 의미함
-
"지난 5분"의 의미는 명확하다고 느껴지지만, 실제로는 놀랍도록 까다로움
-
스트림 처리 프레임워크는 윈도우 시간을 결정할 때 처리하는 장비의 시스템 시계(처리 시간)을 이용함
-
이 접근법은 간단하는 장점이 있으며, 이벤트 생성과 이벤트 처리 사이의 간격이 무시할 정도로 작다면 합리적임
-
그러나 눈에 띌 정도로 처리가 지연되면, 즉 이벤트가 실제로 발생한 시간보다 처리 시간이 많이 늦어지면 문제가 생김
이벤트 시간 대 처리 시간
-
처리가 지연되는 데는 많은 이유가 있을 수 있음. 큐 대기, 네트워크 결함, 메시지 브로커나 처리자에서 경쟁을 유발하는 성능 문제, 스트림 소비자의 재시작, 결함에서 복구하는 도중 코드 상의 버그를 고친 후 과거 이벤트의 재처리 드의 이유
-
또한 메시지가 지연되면 메시지 순서를 예측하지 못할 수도 있음
-
이벤트 시간과 처리 시간을 혼동하면 좋지 않은 데이터가 만들어질 수 있음

- 위 예시를 보면 요청이 안정적으로 들어왔지만, 이벤트 처리 시간을 기준으로 처리되었기 때문에 재시작 이후 백로그를 처리하는 동안 요청이 비정상적으로 튀는 것처럼 보일 수 있음
준비 여부 인식
-
이벤트 시간 기준으로 윈도우를 정의할 때 까다로운 점은 특정 윈도우에서 모든 이벤트가 도작했다거나 아직도 이벤트가 계속 들어오고 있는지를 확신할 수 없다는 것임
-
타임아웃을 설정하고 얼마 동안 새 이벤트가 들어오지 않으면 윈도우가 준비됐다고 선언할 수 있지만, 일부 이벤트는 여전히 네트워크 중단으로 지연돼 다른 장비 어딘가에 버퍼링됐을 수도 있음
-
이를 위해 윈도우를 이미 종료한 후에 도착한 낙오자를 처리할 방법이 필요함
-
낙오자의 이벤트를 무시. 정상적인 환경에서 낙오자 이벤트는 대체로 적은 비율을 차지하기 때문. 놓친 이벤트의 수를 지표로 추적해 많은 양의 데이터가 누락되는 경우 경고를 보낼 수 있음
-
수정 값을 발생. 수정 값은 낙오자 이벤트가 포함된 윈도우를 기준으로 갱신된 값임
-
어떤 시계를 사용할 것인가?
-
이벤트에 타임스탬프를 할당하는 것은 어려운 일임. 어떤 앱이 있다고 했을 때 사용자는 오프라인 환경에서 앱을 사용할 수 있음
-
오프라인일 때 장치의 로컬에 이벤트를 버퍼링하다가 인터넷 연결이 가능해지면 이벤트를 서버로 보낼 수 있음. 이 경우 스트림 소비자는 이 이벤트를 극단적으로 지연된 낙오자 이벤트로 봄
-
이런 맥락에서 이벤트의 타임스탬프는 모바일 장치의 로컬 시계를 따르는 실제 사용자의 상호작용이 발생했던 실제 시각이여야 함
-
다만, 사용자가 제어하는 장비의 시계를 항상 신뢰하기는 어려움
-
잘못된 장치 시계를 조정하는 한 가지 방법은 세 가지 타임스탬프를 로그로 남기는 것
-
이벤트가 발생한 시간. 장치 시계를 따름
-
이벤트를 서버로 보낸 시간. 장치 시계를 따름
-
서버에서 이벤트를 받은 시간. 서버 시계를 따름
-
-
두 번째와 세 번째 타임스탬프의 차이를 구하면 장치 시계와 서버 시계 간의 오프셋을 추정할 수 있고, 계산된 오프셋을 이벤트 타임스탬프에 적용해 이벤트가 실제로 발생한 시간을 추정할 수 있음
윈도우 유형
-
일반적으로 윈도우는 이벤트 수를 세거나 윈도우 내 평균값을 구하는 등 집계를 할 때 사용하며, 일반적으로 사용하는 몇 가지 유형이 존재
-
텀플링 윈도우(Tumbling window) : 텀플링 윈도우는 고정 길이의 크기를 가지며, 모든 이벤트는 정확히 한 윈도우에 속함. 각 이벤트의 타임스탬프를 가져와 타임스탬프에 가장 가까운 분이 되게끔 초 단위를 버려 윈도우를 결정하는 식으로 1분 텀플링 윈도우를 구현할 수 있음
-
홉핑 윈도우(Hopping window) : 홉핑 윈도우도 고정길이를 사용하지만, 결과를 매끄럽게 만들기 위해 윈도우를 중첩할 수 있음. 예를 들어 1분 크기 홉을 사용하는 5분 윈도우 라면, (10시 03분 00초 ~ 10시 07분 59초)가 하나의 윈도우이며, 그 다음 윈도우는 (10시 04분 00초 ~ 10시 08분 59)초임
-
슬라이딩 윈도우(Sliding window) : 슬라이딩 윈도우는 각 시간 간격 사이에서 발생한 모든 이벤트를 포함함. 5분 슬라이딩 윈도우가 있다면, 10시 03분 39초의 이벤트와 10시 08분 12초의 이벤트는 두 이벤트의 타임스탬프가 5분 이하이기 때문에 같은 윈도우에 포함될 수 있음(텀블링, 홉핑 윈도우에서는 고정 길이의 윈도우를 사용하므로 이 두 이벤트는 같은 윈도우에 포함될 수 없음). 보통 슬라이딩 윈도우는 슬라이딩 간격을 통해 윈도우의 간격을 조절함
-
세션 윈도우(Session window) : 세션 윈도우에는 고정된 기간이 없음. 대신 같은 사용자가 짧은 시간 동안 발생시킨 모든 이벤트를 그룹화해서 세션 윈도우를 정의함. 그리고 일정 시간이 지나 사용자가 비활성화되면 윈도우를 종료함. 주로 웹사이트 분석을 할 때 필요
-
스트림 조인
-
스트림에서도 조인은 필요하지만, 새로운 이벤트가 언제든 나타날 수 있다는 사실이 이를 어렵게 만듦
-
스트림에서의 조인의 유형은 스트림 스트림 조인, 스트림 테이블 조인, 테이블 테이블 조인 세 가지로 구분함
스트림 스트림 조인(윈도우 조인)
-
웹사이트에 검색 기능이 있고 거기서 검색된 URL의 최신 경향을 파악하고 싶다고 해보자.
-
그러면 누군가 검색 질의를 타이핑할 때마다 질의와 반환된 결과가 있는 이벤트를 로깅하고, 그 결과를 클릭할 때마다 클릭을 기록하는 다른 이벤트를 로깅해야 함
-
검색 결과에서 각 URL 당 클릭율을 계산하려면 같은 세션 ID를 가져서 서로 연관되는 검색 활동 이벤트와 클릭 활동 이벤트를 함께 모아야 함
-
이때 사용자는 검색 결과를 쓰지 않고 버릴 수 있고, 클릭이 발생했더라도 검색과 클릭 사이의 시간은 매우 가변적일 수 있음
-
따라서 조인은 조인을 위한 적절한 윈도우를 선택해야 함. 예를 들면 한 시간 이내에 발생한 검색과 클릭을 조인하는 식임
-
클릭율을 구하려면 검색 이벤트와 클릭 이벤트가 모두 필요하며, 이러한 유형의 조인을 구현하려면 스트림 처리자가 상태(state)를 유지해야 함
-
예를 들어 지난 시간에 발생한 모든 이벤트를 세션 ID로 색인하고, 검색 이벤트나 클릭 이벤트가 발생할 때마다 해당 색인에 추가하고 스트림 처리자는 같은 세션 ID로 이미 도착한 이벤트가 있는지 다른 색인을 확인해야 함
-
이벤트가 매칭되면 검색한 결과를 클릭했다고 말하는 이벤트를 방출하고, 검색 이벤트가 클릭 이벤트 매칭 없이 만료되면 검색 결과가 클릭되지 않았다고 말해주는 이벤트를 방출함
스트림 테이블 조인(스트림 강화)

-
이러한 조인이 있다고 가정하자
-
이와 같은 경우 사용자 활동 이벤트를 스트림으로 간주하고 스트림 처리자에서 동일한 조인을 지속적으로 수행하는 게 자연스러움
-
이때 입력은 사용자 ID를 포함한 활동 이벤트 스트림이고 출력은 해당 ID를 가진 사용자 프로필 정보가 추가된 활동 이벤트임
-
이 과정을 데이터베이스의 정보로 활동 이벤트를 강화(enriching)한다고 함
-
이 조인을 수행하기 위해 스트림 처리는 한 번에 하나의 활동 이벤트를 대상으로 데이터베이스에서 이벤트의 사용자 ID를 찾아 활동 이벤트에 프로필 정보를 추가해야 함
-
하지만, 이러한 원격 질의는 느리고 데이터베이스에 과부하를 줄 위험이 있음
-
다른 방법은 네트워크 왕복 없이 로컬에서 질의가 가능하도록 스트림 처리자 내부에 데이터베이스 사본을 적재하는 것임
-
이 경우 시간이 지남에 따라 데이터베이스의 내용이 변할 가능성이 높으므로 데이터베이스의 로컬 복사본이 최신 상태로 유지되도록 해야 함
-
이 문제는 CDC를 사용하여 해결할 수 있음
테이블 테이블 조인(구체화 뷰 유지)
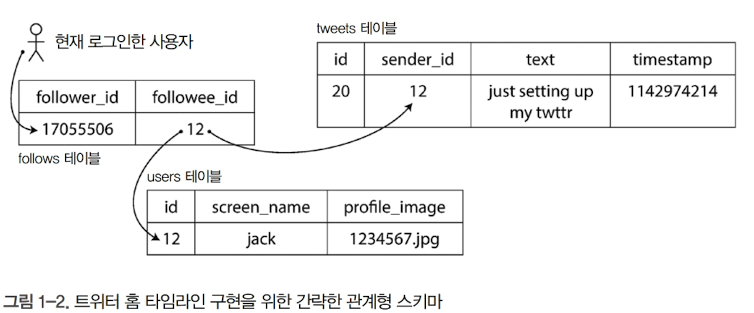
-
위 예시에서 사용자가 자신의 홈 타임라인을 볼 때 사용자가 팔로우한 모든 사람을 순회하며 최근 트윗을 찾아 그것들을 병합하는 것은 너무 많은 비용이 듦
-
대신 트윗이 전송될 때 기록되는 타임라인 캐시를 사용하면, 단일 조회로 같은 기능을 구현할 수 있음
-
이 캐시를 구체화하고 유지보수하기 위해 다음과 같은 이벤트 처리가 필요함
-
사용자 u가 새로 트윗을 보내면 u를 팔로잉하는 모든 사용자의 타임라인에 트윗을 추가함
-
사용자가 트윗을 삭제하면 모든 사용자의 타임라인에서 해당 트윗을 삭제함
-
사용자 u1이 사용자 u2를 팔로우하기 시작하면 u2의 최근 트윗을 u1 타임라인에 추가함
-
사용자 u1이 사용자 u2 팔로우를 취소하면 사용자 u2의 트윗을 사용자 u1의 타임라인에서 삭제함
-
-
스트림 처리자에서 이 캐시 유지를 구현하려면 트윗 이벤트 스트림(전송과 삭제)와 팔로우 관계 이벤트 스트림(팔로우와 언팔로우)가 필요함
-
스트림 처리는 새로운 트윗이 도착했을 때 어떤 타임라인을 갱신하는지 알기 위해 각 사용자의 팔로우 집합이 포함된 데이터베이스를 유지해야 함
-
이런 스트림 처리를 구현하는 다른 방법은 아래와 같이 트윗과 팔로우, 두 테이블을 조인하는 질의에 대한 구체화 뷰를 유지하는 것
SELECT follows.follower_id AS timeline_id,
array_agg(tweets.* ORDER BY tweets.timestamp DESC)
FROM tweets
JOIN follows ON follows.followee_id = tweets.sender_id
GROUP BY follows.follower_id- 스트림 조인은 해당 쿼리의 테이블 조인에 직접 대응됨. 결과적으로 이 질의 결과의 캐시가 타임라인이 되며 조인 대상 테이블이 변할 때마다 갱신됨
조인의 시간 의존성
-
세 가지 조인 모두 스트림 처리자가 하나의 조인 입력을 기반으로 한 특정 상태를 유지해야 하고 다른 조인 입력에서 온 메시지에 그 상태를 질의하는 방식임
-
상태를 유지하는 이벤트의 순서는 매우 중요함. 하지만, 파티셔닝된 로그에서 단일 파티션 내 이벤트 순서는 보존되지만 다른 스트림이나 다른 파티션 사이에서 순서를 보장하는 일반적인 방법은 없음
-
비슷한 시각에 다른 스트림에서 발생한 이벤트가 있으면 어떤 순서로 처리되는 것일까?
-
복수 개의 스트림에 걸친 이벤트 순서가 결정되지 않으면 조인도 비결정이된다는 의미
-
이 문제를 데이터 웨어하우스에서는 천천히 변하는 차원(slowly changing dimension, SCD)라고 함.
-
SCD는 흔히 조인되는 레코드의 특정 버전을 가리키는 유일한 식별자를 사용해 해결함
-
이 경우 조인은 결정적으로 변하지만, 테이블에 있는 레코드의 모든 버전을 보유해야 하기 때문에 로그 컴팩션이 불가능해짐
내결함성
-
일괄 처리에서는 HDFS 상의 분리된 파일에 출력을 기록하며, 단순히 실패하면 처음부터 재수행하는 것을 통해 내결함성을 보장함
-
이러한 원리를 결과적으로 한 번(effectively-once)라는 용어로 설명될 수 있음
-
스트림에서는 일괄 처리보다 덜 직관적인 방법을 사용함
마이크로 일괄 처리와 체크 포인트
-
한 가지 해결책은 스트림을 작은 블록으로 나누고, 작은 블록을 일괄 처리와 같이 다루는 것
-
이는 스파크 스트리밍에서 사용함. 일반적으로 약 1초 정도로 사용
-
마이크로 일괄 처리는 텀블링 윈도우를 암묵적으로 지원(이벤트
타임스탬프 기준이 아닌 처리 시간 기준의 윈도우) -
마이크로 일괄 처리 크기보다 큰 윈도우가 필요한 작업은 마이크로 일괄 처리 작업을 수행한 후 상태를 명시적으로 다음 마이크로 일괄 처리 작업으로 넘겨주어야 함
-
아파치 플링크는 주기적으로 상태의 롤링 체크포인트를 생성하고 지속성 있는 저장소에 저장함.
-
스트림 연산자에 장애가 발생하면 스트림 연산자는 가장 최근 체크포인트에서 재시작하고 해당 체크포인트와 장애 발생 사이의 출력은 버림
-
체크포인트는 메시지 스트림 내 배리어(barrier)가 트리거. 배리어는 마이크로 일괄 처리 사이의 경계(boundary)와 비슷하지만 윈도우의 크기를 특정하지 않음
-
마이크로 일괄 처리와 체크포인트 접근법은 일괄 처리와 같이 정확히 한 번 시맨틱을 지원하지만, 출력이 스트림 처리자를 떠나자마자 스트림 처리 프레임워크는 실패한 일괄 처리 출력을 더 이상 지울 수 없음
-
따라서 이러한 접근법만으로는 내결함성을 보장할 수 없음
원자적 커밋 재검토
-
장애가 발생했을 때 정확히 한 번 처리되는 것처럼 보일려면 처리가 성공했을 때만 모든 출력과 이벤트 처리의 부수 효과가 발생하게 해야함
-
XA 같은 전통적인 분산 트랜잭션을 구현할 때 발생하는 문제를 설명. 그러나 좀 더 제한된 환경에서는 그러한 원자적 커밋을 효율적으로 구현하는 것이 가능하다고 함
-
XA와는 다르게 이종 기술 간 트랜잭션을 지원하지 않는 대신 스트림 처리 프레임워크 내에서 상태 변화와 메시지를 관리해 트랜잭션을 내부적으로 유지하는 방법임
-
트랜잭션 프로토콜에서 발생하는 오버헤드는 단일 트랜잭션 내에서 여러 입력 메시지를 처리해 상쇄
멱등성
-
멱등 연산은 여러 번 수행하더라도 오직 한 번 수행한 것과 같은 효과를 내는 연산임
-
연산 자체가 멱등적이지 않아도 약간의 여분 메타데이터로 연산을 멱등적으로 만들 수 있음
-
예를 들어 카프카로부터 메시지를 소비할 때 모든 메시지에 단조 증가하는 오프셋이 있음. 외부 데이터베이스에 값을 기록할 때 마지막으로 그 값을 기록하라고 트리거한 메시지의 오프셋을 포함하면 반복해서 같은 갱신이 수행되는 것을 막을 수 있음
-
멱등성에 의존한다는 것은 실패한 태스크를 재시작할 때 반드시 같은 순서로 메시지를 재생해야 하며 처리는 결정적이어야 하며 어떤 노드도 동시에 같은 값을 갱신하지 않아야 하는 것을 의미함
-
이를 위해 처리 중인 한 노드에서 다른 노드로 장애 복구가 발생할 때 죽었다고 생각되지만 실제로는 살아있는 노드의 간섭을 방지하기 위해 펜싱이 필요함
실패 후에 상태 재구축하기
-
윈도우 집계나 조인용 테이블과 색인처럼 상태가 필요한 스트림 처리는 실패 후에도 해당 상태가 복구됨을 보장해야 함
-
한 가지 방법은 원격 데이터 저장소에 상태를 유지하고 복제하는 것
-
그러면 스트림 처리자가 실패한 작업을 복구할 때 새 태스크는 복제된 상태를 읽어 데이터 손실 없이 재처리할 수 있음
-
예를 들어 플링크는 주기적으로 연산자 상태의 스냅숏을 캡처하고 이를 HDFS와 같은 지속성 있는 저장소에 기록함. 쌈자와 카프카 스트림은 로그 컴팩션을 사용하는 상태 복제 전용 카프카 토픽에 상태 변화를 보내서 복제함
