Stack
스택은 마지막에 저장한 데이터를 가장 먼저 꺼내게 되는 LIFO(Last In First Out)구조로 되어 있다.
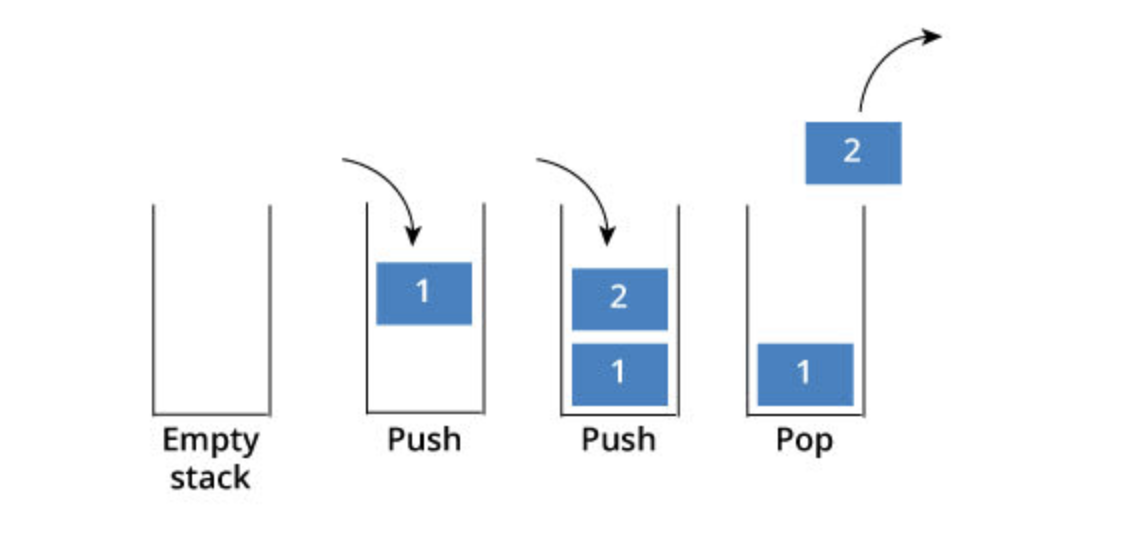
삭제나 삽입시 맨 위에 데이터를 삽입하거나 삭제하기 때문에 시간복잡도는 늘 O(1) 의 시간복잡도를 가진다.
하지만 특정 데이터를 찾을 때는 특정 데이터를 찾을 때까지 수행을 해야하므로 O(n)
의 시간 복잡도를 가진다.
Stack 장단점
✅ top 을 통해 접근하기 때문에 데이터 접근, 삽입, 삭제가 빠르다
⛔ top 위치 이외의 데이터에 접근할 수 없기 때문에 탐색이 불가능하다. 탐색하려면 모든 데이터를 꺼내면서 진행해야 한다.
Stack 선언
Stack<Integer> stack = new Stack<>(); //int형 스택 선언
Stack<String> stack = new Stack<>(); //char형 스택 선언Stack 의 값 추가, 삭제
Stack<Integer> stack = new Stack<>(); //int형 스택 선언
stack.push(1); // stack에 값 1 추가
stack.push(2); // stack에 값 2 추가
stack.push(3); // stack에 값 3 추가
stack.pop(); // stack에 값 제거
stack.clear(); // stack의 전체 값 제거 (초기화)스택에서 값을 제거하고싶다면 pop() 이라는 메서드를 사용하면 된다. pop을 하면 가장 위쪽에 있는 원소의 값이 제거된다.
스택의 값을 모두 제거하고싶다면 clear() 라는 메서드를 사용하면 된다.
Stack의 가장 상단의 값 출력
Stack<Integer> stack = new Stack<>(); //int형 스택 선언
stack.push(1); // stack에 값 1 추가
stack.push(2); // stack에 값 2 추가
stack.push(3); // stack에 값 3 추가
stack.peek(); // stack의 가장 상단의 값 출력스택의 가장 위에 있는 값을 출력하고 싶다면 peek() 라는 함수를 사용하면 된다.
Stack의 기타 메서드
Stack<Integer> stack = new Stack<>(); //int형 스택 선언
stack.push(1); // stack에 값 1 추가
stack.push(2); // stack에 값 2 추가
stack.size(); // stack의 크기 출력 : 2
stack.empty(); // stack이 비어있는제 check (비어있다면 true)
stack.contains(1) // stack에 1이 있는지 check (있다면 true)Queue
큐는 처음에 저정한 데이터를 가장 먼저 꺼내게 되는 FIFO(First In First Out)구조로 되어 있다.
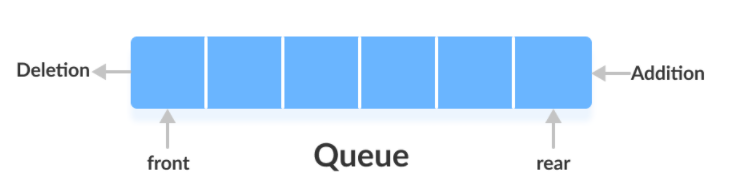
데이터가 삽입되는 곳을 rear, 데이터가 제거되는 곳을 front 라 한다. 데이터를 삭제하기 전에는 큐가 empty 한지, 큐에 데이터를 추가하려 할 때는 큐가 full 인지 확인 후 진행해야 한다.
큐 역시 front, rear 의 위치로 데이터 삽입 삭제가 바로 이루어지기 때문에 원소 삽입, 삭제의 시간 복잡도는 O(1) 이다.
Queue 장단점
✅ 데이터 접근, 삽입, 삭제가 빠르다.
⛔ 큐 역시 스택과 마찬가지로 중간에 위치한 데이터에 대한 접근이 불가능하다.
Queue 선언
Queue queue = new LinkedList(); // 타입 설정x Object로 입력
Queue<QueueDemo> demo = new LinkedList<QueueDemo>(); // 타입을 QueueDemo클래스로 설정
Queue<Integer> i = new LinkedList<Integer>(); // Integer타입으로 선언
Queue<Integer> i2 = new LinkedList<>(); // new부분 타입 생략 가능
Queue<Integer> i3 = new LinkedList<Integer>(Arrays.asList(1, 2, 3)); // 선언과 동시에 초기값 세팅
Queue<String> str = new LinkedList<String>(); // String타입 선언
Queue<Character> ch = new LinkedList<Character>(); // Character타입 선언LinkedList로 생성을 해야한다.
Queue 값 추가/삭제, 탐색 등
위에 스택과 동일한 메서드를 사용한다.
스택과 큐의 활용
- 스택의 활용 예 : 수식계산, 수식괄호검사, 워드프로세서의 undo/redo, 웹브라우저의 뒤로/앞으로
- 큐의 활용 예 : 최근 사용문서, 인쇄작업 대기목록, 버퍼(buffer)
스택과 큐의 구현
스택과 큐를 구현하기 위해서는, 스택은 ArrayList 와 같은 배열기반의 컬렉션 클래스가 적합하지만,
큐는 데이터를 꺼낼 때 항상 첫번째 데이터를 가져오므로 ArrayList 같은 배열 기반의 컬렉션 클래스를 사용한다면, 데이터를 꺼낼 때마다 빈 공간을 채우기 우해 데이터의 복사가 발생하므로 비효율적이다. 그래서 큐는 데이터의 추가/삭제가 쉬운 LinkedList로 구현하는 것이 더 적합하다.
PriorityQueue
Queue 인터페이스의 구현체 중의 하나로, 저장한 순서에 관계없이 우선순위(priority)가 높은 것부터 꺼내게 된다는 특징이 있다. 그리고 null은 저장할 수 없다. null을 저장하려고 하면 NullPointerException이 난다.
PriorityQueue는 저장공간으로 배열을 사용하여, 각 요소를 힙 자료구조의 형태로 저장한다. 힙은 이진트리의 한 종류로 가장 큰 값이나 가장 작은 값을 빠르게 찾을 수 있다는 특징이 있다. 내부구조가 힙으로 구성되어 있기에 시간 복잡도는 O(NLogN)이다.
PriorityQueue 선언
import java.util.PriorityQueue; //import
//int형 priorityQueue 선언 (우선순위가 낮은 숫자 순)
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();
//int형 priorityQueue 선언 (우선순위가 높은 숫자 순)
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(Collections.reverseOrder());
//String형 priorityQueue 선언 (우선순위가 낮은 숫자 순)
PriorityQueue<String> priorityQueue = new PriorityQueue<>();
//String형 priorityQueue 선언 (우선순위가 높은 숫자 순)
PriorityQueue<String> priorityQueue = new PriorityQueue<>(Collections.reverseOrder());PriorityQueue 값 추가
priorityQueue.add(1); // priorityQueue 값 1 추가
priorityQueue.add(2); // priorityQueue 값 2 추가
priorityQueue.offer(3); // priorityQueue 값 3 추가add(value) 또는 offer(value) 라는 메서드를 활용하면 된다.
add() 메서드는 Collection클래스에서 가져오는 메서드라면, offer() Queue클래스에서 가져오는 메서드이다.
add(value) 메서드의 경우 만약 삽입에 성공하면 true를 반환하고, 큐에 여유 공간이 없어 삽입에 실패하면 IllegalStateException을 발생시킨다.
public class PriorityQueueDemo {
public static void main(String[] args) {
Queue pq = new PriorityQueue<>();
pg.offer(3);
pg.offer(1);
pg.offer(5);
pg.offer(2);
pg.offer(4);
System.out.println(pq);
Object obj = null;
while(obj=pq.poll()!=null)
System.out.println(obj);
}
}[1,2,5,3,4]
1
2
3
4
5저장순서가 3,1,5,2,4 인데도 출력결과는 1,2,3,4,5 이다. 우선순위는 숫자가 작을 수록 높은 것이므로 1이 가장 먼저 출력된 것이다.
예제에서는 정수를 사용했는데, 컴파일러가 Integer로 auto boxing 해준다. Integer와 같은 Number의 자손들은 자체적으로 숫자를 비교하는 방법을 정의하고 있기 때문에 비교 방법을 지정해주지 않아도 된다.
객체를 저장할 수도 있지만, 비교가 가능한 기준이 있어야한다.
참조변수 pq를 출력하면 PriorityQueue가 내부적으로 가지고 있는 배열의 내용이 출력되는데, 저장한 순서와 다르게 지정되었다. 이건 힙 자료구조의 형태로 저장된 것이라 그렇다.
힙은 Complete Binary Tree(완전 이진 트리) 이다.
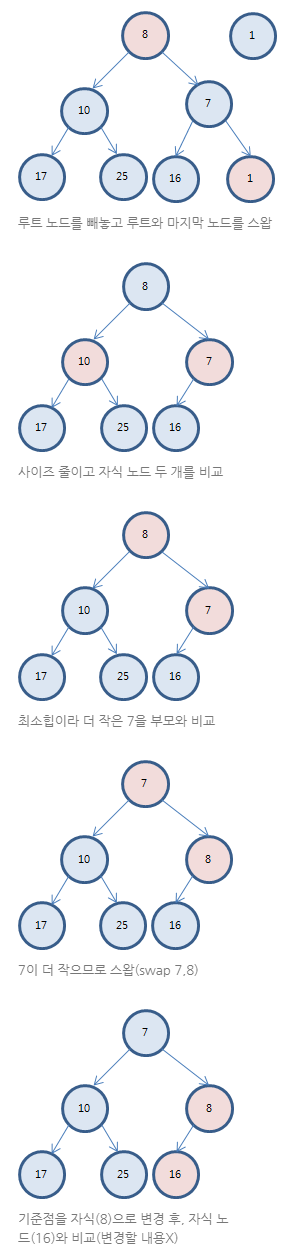
데이터가 들어오면 다음과 같은 순서로 만들어진다.
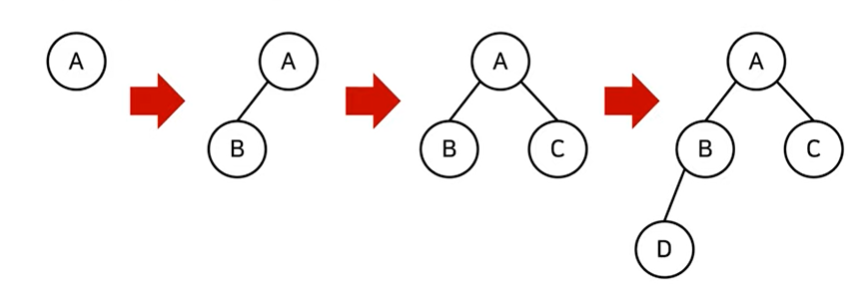
출처: 동빈나- 자료구조: 우선순위 큐(Priority Queue)와 힙(Heap) 10분 핵심 요약
삽입이 실행되면 아래와 같은 구조로 데이터의 삽입이 이루어 진다.
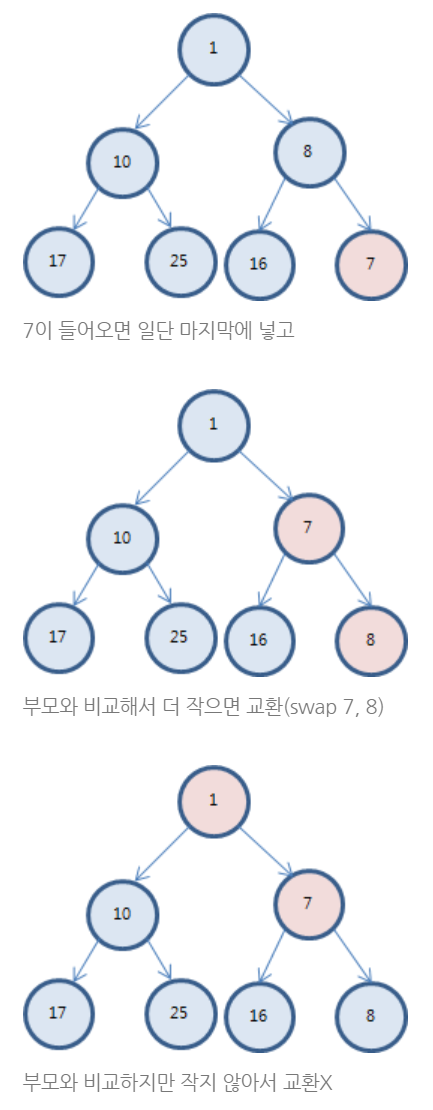
PriorityQueue 값 삭제
priorityQueue.poll(); // priorityQueue에 첫번째 값을 반환하고 제거 비어있다면 null
priorityQueue.remove(); // priorityQueue에 첫번째 값 제거
priorityQueue.clear(); // priorityQueue에 초기화- 우선순위 큐에서 값을 제거하고 싶다면 poll() 이나 remove() 라는 메서드를 사용하면 된다. 우선순위가 가장 높은 값이 제거되며, poll() 함수는 우선순위 큐가 비어있으면 null을 반환한다.
- remove(int Index) 메서드를 사용하면 Index 순위에 해당하는 값을 제거한다.
- clear() 메서드를 사용하면 우선순위 큐의 모든 값을 삭제한다.
public class PriorityQueueDemo {
public static void main(String[] args) {
PriorityQueue<Integer> pq = new PriorityQueue<>();
// 1, 15, 8, 21, 25, 18, 10 값 추가
pq.add(1); pq.add(15); pq.offer(10);
pq.add(21); pq.add(25); pq.offer(18);
pq.add(8);
System.out.println(pq); // 결과 출력
pq.poll();
System.out.println(pq); // 결과 출력
pq.remove();
pq.remove(1);
System.out.println(pq); // 결과 출력
pq.clear();
System.out.println(pq); // 결과 출력
}
}[1,15,8,21,25,18,10]
[8,15,10,21,25,18]
[10,15,18,21,25]
[]결과를 보면 첫 번째 우선순위를 삭제하면 하나씩 밀리는 것이 아닌 우선순위를 재정렬하는 것을 알 수 있다.
이건 또 어떻게 된건지 과정을 봐보자.
Priority Queue에서 우선순위가 가장 높은 값 출력
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();//int형 priorityQueue 선언
priorityQueue.offer(2); // priorityQueue에 값 2 추가
priorityQueue.offer(1); // priorityQueue에 값 1 추가
priorityQueue.offer(3); // priorityQueue에 값 3 추가
priorityQueue.peek(); // priorityQueue에 첫번째 값 참조 = 1우선순위가 가장 높은 값을 참조하고 싶다면 peek() 라는 메서드를 사용하면 된다. 위의 예시에서는 우선순위가 가장 높은 1이 출력된다.
PriorityBlockingQueue
PriorityQueue 는 thread safe 하지 않기 때문에, 멀티쓰레드 환경에서 여러 쓰레드가 해당 자료구조에 접근해야 할 경우에는 PriorityBlockingQueue 를 사용해야 한다.
Deque(Double-Ended Queue)
Queue변형으로, 한쪽끝으로만 추가/삭제를 할 수 있는 큐와 달리, 덱(Deque)은 양쪽 끝에 추가/삭제가 가능하다.
구현체로는 ArrayDeque, LinkedList 등이 있다.
Deque 메소드
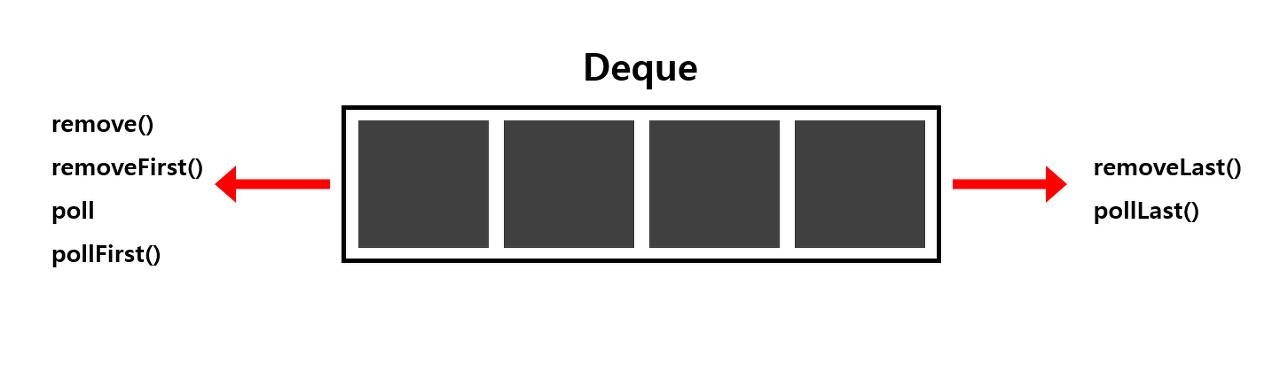
| 메소드명 | 내용 | 비고 |
|---|---|---|
| add() | 마지막에 원소 삽입 | 용량 초과 시 예외 발생 |
| addFirst() | 맨 앞에 원소 삽입 | 용량 초과 시 예외 발생 |
| addLast() | 마지막에 원소 삽입 | 용량 초과 시 예외 발생 |
| offer() | 마지막에 원소 삽입 | 삽입 성공 시 true, 용량 제한에 걸리는 경우 false 반환 |
| offerFirst() | 맨 앞에 원소 삽입 | 삽입 성공 시 true, 용량 제한에 걸리는 경우 false 반환 |
| offerLast() | 마지막에 원소 삽입 | 삽입 성공 시 true, 용량 제한에 걸리는 경우 false 반환 |
Deque 값 삭제
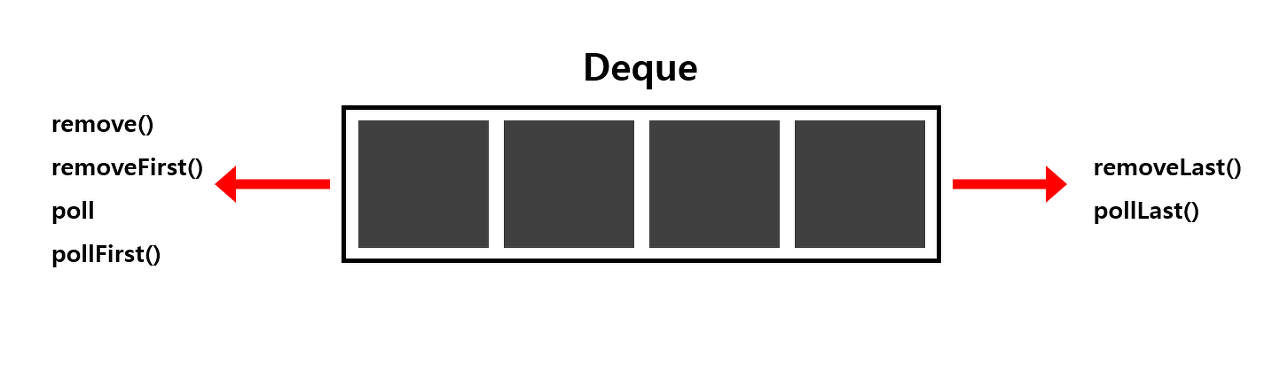
| 메소드명 | 내용 | 비고 |
|---|---|---|
| remove() | 맨 앞의 원소 제거 후 해당 원소를 리턴 | 덱이 비어있는 경우 예외 발생 |
| removeFirst() | 맨 앞의 원소 제거 후 해당 원소를 리턴 | 덱이 비어있는 경우 예외 발생 |
| removeLast() | 마지막 원소 제거 후 해당 원소를 리턴 | 덱이 비어있는 경우 예외 발생 |
| poll() | 맨 앞의 원소 제거 후 해당 원소를 리턴 | 덱이 비어있는 경우 null 리턴 |
| pollFirst() | 맨 앞의 원소 제거 후 해당 원소를 리턴 | 덱이 비어있는 경우 null 리턴 |
| pollLast() | 마지막 원소 제거 후 해당 원소를 리턴 | 덱이 비어있는 경우 null 리턴 |
Deque 원소 확인
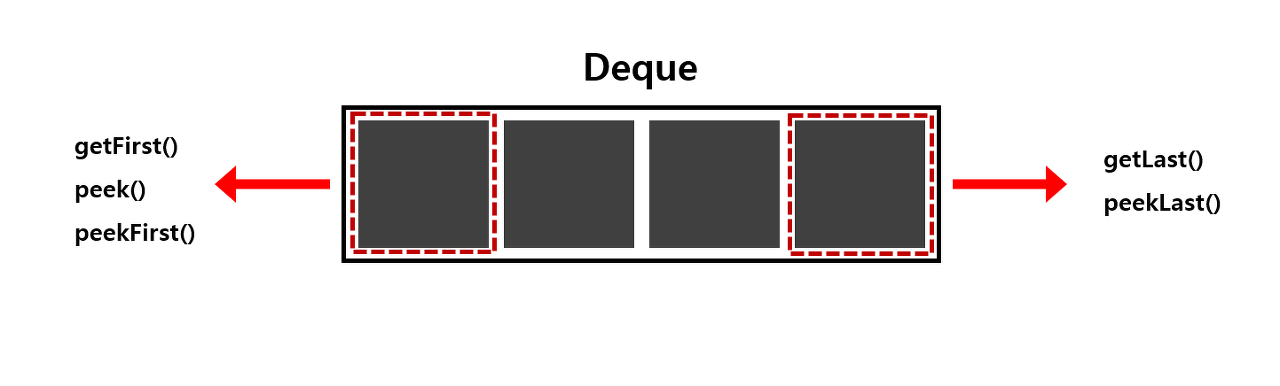
| 메소드명 | 내용 | 비고 |
|---|---|---|
| getFirst() | 맨 앞의 원소를 리턴 | 덱이 비어있는 경우 예외 발생 |
| getLast() | 마지막 원소를 리턴 | 덱이 비어있는 경우 예외 발생 |
| peek() | 맨 앞의 원소를 리턴 | 덱이 비어있는 경우 null 리턴 |
| peekFirst() | 맨 앞의 원소를 리턴 | 덱이 비어있는 경우 null 리턴 |
| peekLast() | 마지막 원소를 리턴 | 덱이 비어있는 경우 null 리턴 |
| contains(x) | 덱에 x와 동일한 원소가 있는지 true 혹은 false 반환 | |
| isEmpty() | 덱이 비어있는지 true 혹은 false 반환 | |
참고자료: 남궁성의 자바의 정석
https://coding-factory.tistory.com/601
https://coding-factory.tistory.com/603
https://crazykim2.tistory.com/575
