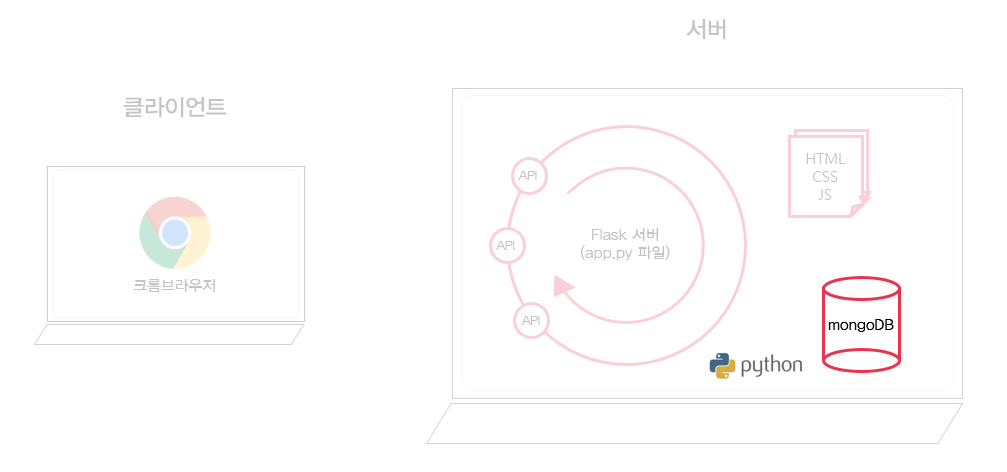
3주차는 크롤링, mongoDB를 활용하여 웹 스크래핑 하기!
파이썬 패키지사용법 예시(미세먼지, 영화)
import requests
r = requests.get('http://openapi.seoul.go.kr:8088/6d4d776b466c656533356a4b4b5872/json/RealtimeCityAir/1/99')
rjson = r.json()
gus = rjson['RealtimeCityAir']['row']
for gu in gus:
gu_name = gu['MSRSTE_NM']
gu_mise = gu['IDEX_MVL']
if (gu_mise > 50):
print(gu_name, gu_mise)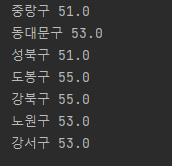
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None:
rank = movie.select_one('td:nth-child(1) > img')['alt']
title = a_tag.text
star = movie.select_one('td.point').text
print(rank, title, star)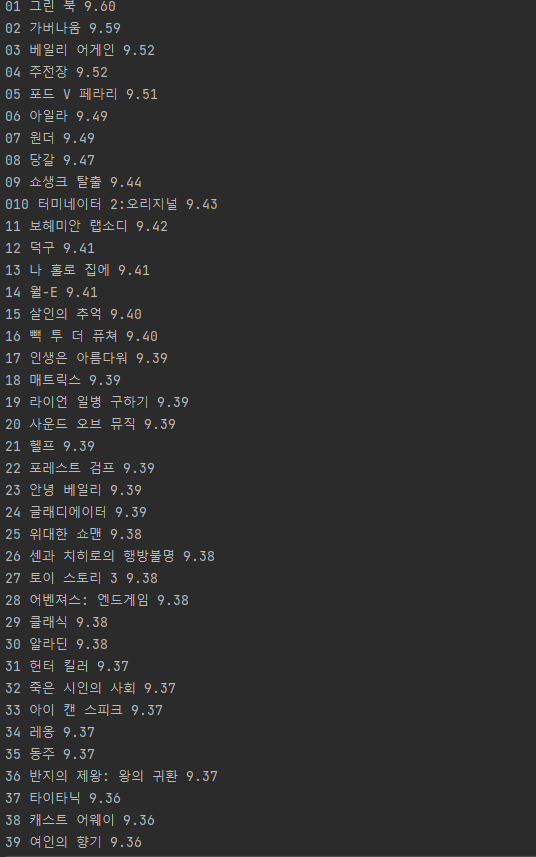
pymongo 코드 요약
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
same_ages = list(db.users.find({'age':21},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})3주차 숙제 지니뮤직 스크래핑
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=D&rtm=N&ymd=20211229',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
music_chart = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for songs in music_chart:
a_tag = songs.select_one('td.info > a.title.ellipsis')
if a_tag is not None:
titlename = a_tag.text.strip()
artist = songs.select_one('td.info > a.artist.ellipsis').text.strip()
rank = songs.select_one('td.number').text[0:2].strip()
print(rank, titlename, artist)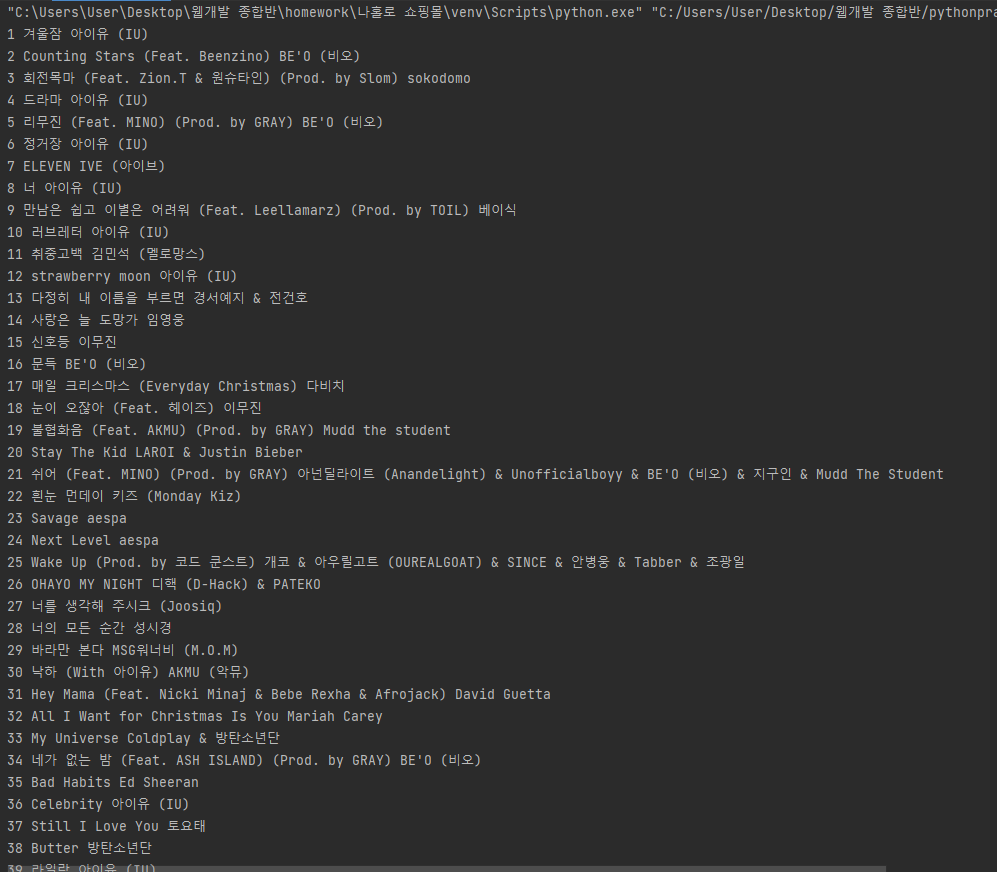

hi